


Computer vision enables machines to analyze & interpret visual data, driving innovation across diverse applications such as autonomous vehicles, medical diagnostics, and industrial automation. Researchers aim to enhance computational models to process complex visual tasks more accurately and efficiently, leveraging techniques like neural networks to handle high-dimensional image data. As tasks become more demanding, striking a balance between computational efficiency and performance remains a critical goal for advancing this field.
One significant challenge in lightweight computer vision models is effectively capturing global and local features in resource-constrained environments. Current approaches, including Convolutional Neural Networks (CNNs) and Transformers, face limitations. CNNs, while efficient at extracting local features, need help with global feature interactions. Though powerful for modeling global attention, transformers exhibit quadratic complexity, making them computationally expensive. Further, Mamba-based methods, designed to overcome these challenges with linear complexity, fail to retain high-frequency details crucial for precise visual tasks. This bottleneck limits their utility in real-world scenarios requiring high throughput and accuracy.
Efforts to address these challenges have led to various innovations. CNN-based methods like MobileNet introduced separable convolutions to enhance computational efficiency, while hybrid designs like EfficientFormer combined CNNs with Transformers for selective global attention. Mamba-based models, including VMamba and EfficientVMamba, reduced computational costs by optimizing scanning paths. However, these models focused predominantly on low-frequency features, neglecting high-frequency information essential for detailed visual analysis. This imbalance hinders performance, particularly in tasks requiring fine-grained feature extraction.
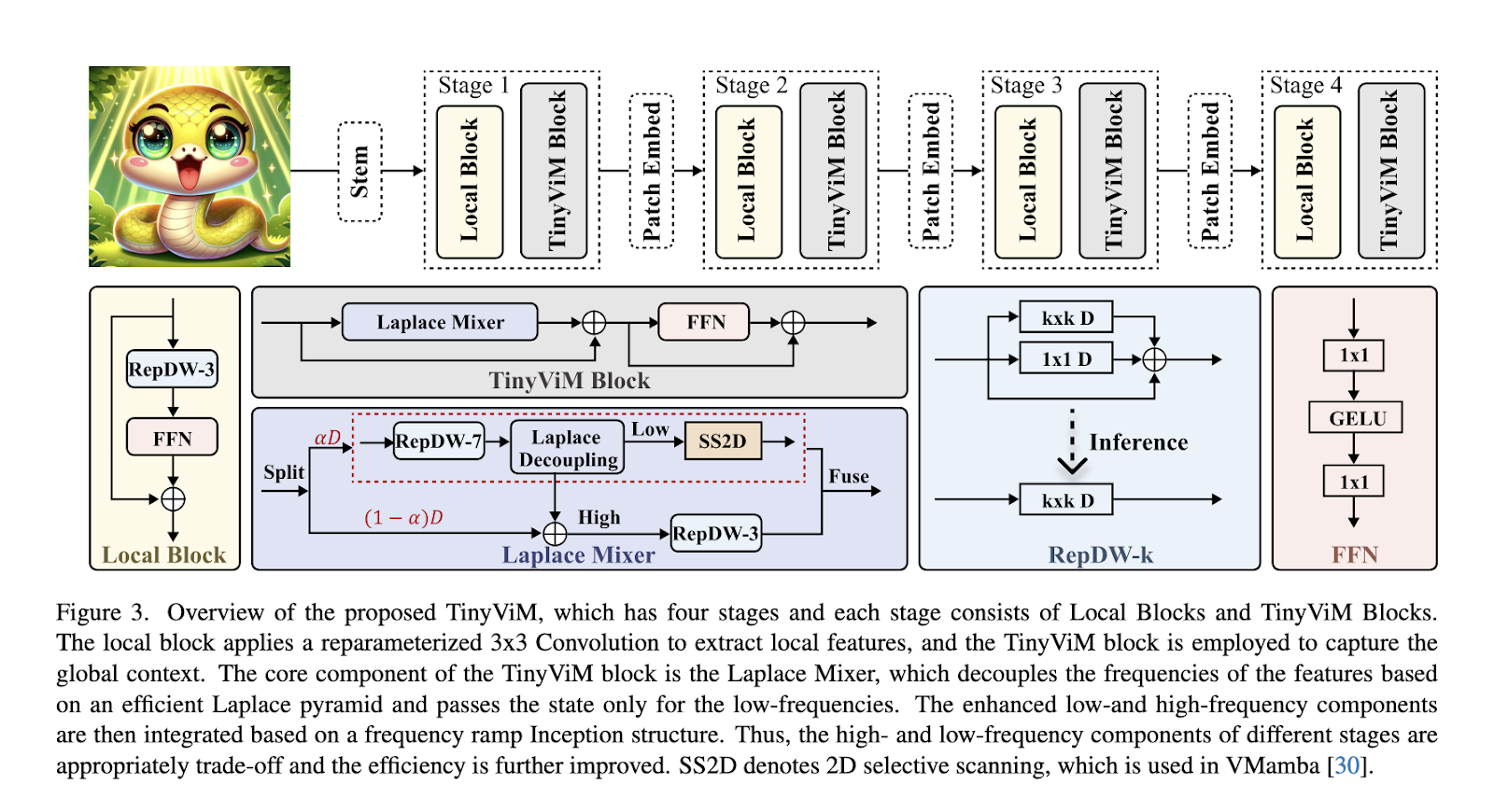
Researchers from Huawei Noah’s Ark Lab introduced TinyViM, a groundbreaking hybrid architecture that integrates Convolution and Mamba blocks, optimized through frequency decoupling. TinyViM aims to improve computational efficiency and feature representation by addressing the limitations of prior approaches. The Laplace mixer is a core innovation in this architecture, enabling efficient decoupling of low- and high-frequency components. By processing low-frequency features with Mamba blocks for global context and high-frequency details with reparameterized convolution operations, TinyViM achieves a more balanced and effective feature extraction process.
TinyViM employs a frequency ramp inception strategy to enhance its efficiency further. This approach adjusts the allocation of computational resources across network stages, focusing more on high-frequency branches in earlier stages where local details are critical and shifting emphasis to low-frequency components in deeper layers for global context. This dynamic adjustment ensures optimal feature representation at every stage of the network. Moreover, the TinyViM architecture incorporates mobile-friendly convolutions, making it suitable for real-time and low-resource scenarios.
Extensive experiments validate TinyViM’s effectiveness across multiple benchmarks. In image classification on the ImageNet-1K dataset, TinyViM-S achieved a top-1 accuracy of 79.2%, surpassing SwiftFormer-S by 0.7%. Its throughput reached 2574 images per second, doubling the efficiency of EfficientVMamba. In object detection and instance segmentation tasks using the MS-COCO 2017 dataset, TinyViM outperformed other models, including SwiftFormer and FastViT, with significant improvements of up to 3% in APbox and APmask metrics. For semantic segmentation on the ADE20K dataset, TinyViM demonstrated state-of-the-art performance with a mean intersection over union (mIoU) of 42.0%, highlighting its superior feature extraction capabilities.

TinyViM’s performance advantages are underscored by its lightweight design, which achieves remarkable throughput without compromising accuracy. For instance, TinyViM-B attained an accuracy of 81.2% on ImageNet-1K, outperforming MobileOne-S4 by 1.8%, Agent-PVT-T by 2.8%, and MSVMamba-M by 1.4%. In detection tasks, TinyViM-B demonstrated 46.3 APbox and 41.3 APmask, while TinyViM-L extended these improvements to 48.6 APbox and 43.8 APmask, affirming its scalability and versatility across task sizes.
The Huawei Noah’s Ark Lab research team has redefined lightweight vision backbones with TinyViM, addressing critical limitations in prior models. By leveraging frequency decoupling, Laplace mixing, and frequency ramp inception, TinyViM balances high-frequency details with low-frequency context, achieving superior accuracy and computational efficiency. Its ability to outperform state-of-the-art CNNs, Transformers, and Mamba-based models across diverse visual tasks is a valuable tool for real-time applications. This work demonstrates the potential of integrating innovative feature extraction techniques into hybrid architectures, paving the way for future advancements in computer vision.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.

 ‘
‘The post This AI Paper Introduces TinyViM: A Frequency-Decoupling Hybrid Architecture for Efficient and Accurate Computer Vision Tasks appeared first on MarkTechPost.
Source: Read MoreÂ