
By Cheng Xie, Bryan Shultz, and Christine Xu
In a previous blog post, we described how Netflix uses eBPF to capture TCP flow logs at scale for enhanced network insights. In this post, we delve deeper into how Netflix solved a core problem: accurately attributing flow IP addresses to workload identities.
A Brief Recap
FlowExporter is a sidecar that runs alongside all Netflix workloads. It uses eBPF and TCP tracepoints to monitor TCP socket state changes. When a TCP socket closes, FlowExporter generates a flow log record that includes the IP addresses, ports, timestamps, and additional socket statistics. On average, 5 million records are produced per second.
In cloud environments, IP addresses are reassigned to different workloads as workload instances are created and terminated, so IP addresses alone cannot provide insights on which workloads are communicating. To make the flow logs useful, each IP address must be attributed to its corresponding workload identity. FlowCollector, a backend service, collects flow logs from FlowExporter instances across the fleet, attributes the IP addresses, and sends these attributed flows to Netflix’s Data Mesh for subsequent stream and batch processing.
The eBPF flow logs provide a comprehensive view of service topology and network health across Netflix’s extensive microservices fleet, regardless of the programming language, RPC mechanism, or application-layer protocol used by individual workloads.
The Problem with Misattribution
Accurately attributing flow IP addresses to workload identities has been a significant challenge since our eBPF flow logs were introduced.
As noted in our previous blog post, our initial attribution approach relied on Sonar, an internal IP address tracking service that emits an event whenever an IP address in Netflix’s AWS VPCs is assigned or unassigned to a workload. FlowCollector consumes a stream of IP address change events from Sonar and uses this information to attribute flow IP addresses in real-time.
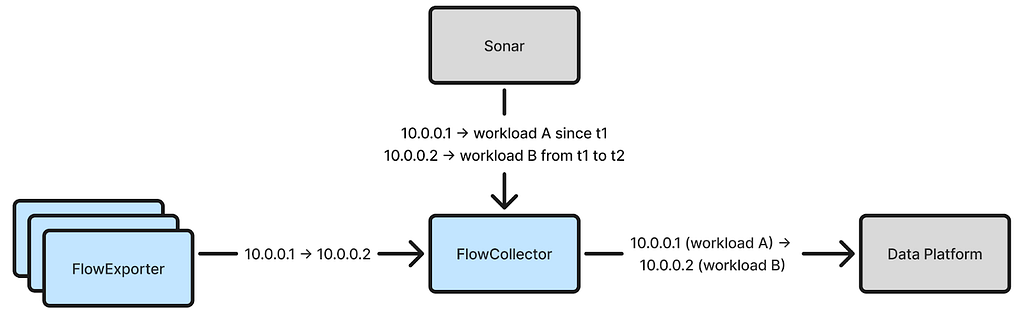
The fundamental drawback of this method is that it can lead to misattribution. Delays and failures are inevitable in distributed systems, which may delay IP address change events from reaching FlowCollector. For instance, an IP address may initially be assigned to workload X but later reassigned to workload Y. However, if the change event for this reassignment is delayed, FlowCollector will continue to assume that the IP address belongs to workload X, resulting in misattributed flows. Additionally, event timestamps may be inaccurate depending on how they are captured.
Misattribution rendered the flow data unreliable for decision-making. Users often depend on flow logs to validate workload dependencies, but misattribution creates confusion. Without expert knowledge of expected dependencies, users would struggle to identify or confirm misattribution. Moreover, misattribution occurred frequently for critical services with a large footprint due to frequent IP address changes. Overall, misattribution makes fleet-wide dependency analysis impractical.
As a workaround, we made FlowCollector hold received flows for 15 minutes before attribution, allowing time for delayed IP address change events. While this approach reduced misattribution, it did not eliminate it. Moreover, the waiting period made the data less fresh, reducing its utility for real-time analysis.
Fully eliminating misattribution is crucial because it only takes a single misattributed flow to produce an incorrect workload dependency. Solving this problem required a complete rethinking of our approach. Over the past year, Netflix developed a new attribution method that has finally eliminated misattribution, as detailed in the rest of this post.
Attributing Local IP Addresses
Each socket has two IP addresses: a local IP address and a remote IP address. Previously, we used the same method to attribute both. However, attributing the local IP address should be a simpler task since the local IP address belongs to the instance where FlowExporter captures the socket. Therefore, FlowExporter should determine the local workload identity from its environment and attribute the local IP address before sending the flow to FlowCollector.
This is straightforward for workloads running directly on EC2 instances, as Netflix’s Metatron provisions workload identity certificates to each EC2 instance at boot time. FlowExporter can simply read these certificates from the local disk to determine the local workload identity.
Attributing local IP addresses for container workloads running on Netflix’s container platform, Titus, is more challenging. FlowExporter runs at the container host level, where each host manages multiple container workloads with different identities. When FlowExporter’s eBPF programs receive a socket event from TCP tracepoints in the kernel, the socket may have been created by one of the container workloads or by the host itself. Therefore, FlowExporter must determine which workload to attribute the socket’s local IP address to. To solve this problem, we leveraged IPMan, Netflix’s container IP address assignment service. IPManAgent, a daemon running on every container host, is responsible for assigning and unassigning IP addresses. As container workloads are launched, IPManAgent writes an IP-address-to-workload-ID mapping to an eBPF map, which FlowExporter’s eBPF programs can then use to look up the workload ID associated with a socket local IP address.

Another challenge was to accommodate Netflix’s IPv6 to IPv4 translation mechanism on Titus. To facilitate IPv6 migration, Netflix developed a mechanism that enables IPv6-only containers to communicate with IPv4 destinations without incurring NAT64 overhead. This mechanism intercepts connect syscalls and replaces the underlying socket with one that uses a shared IPv4 address assigned to the container host. This confuses FlowExporter because the kernel reports the same local IPv4 address for sockets created by different container workloads. To disambiguate, local port information is additionally required. We modified Titus to write a mapping of (local IPv4 address, local port) to the workload ID into an eBPF map whenever a connect syscall is intercepted. FlowExporter’s eBPF programs then use this map to correctly attribute sockets created by the translation mechanism.
With these problems solved, we can now accurately attribute the local IP address of every flow.
Attributing Remote IP Addresses
Once the local IP address attribution problem is solved, accurately attributing remote IP addresses becomes feasible. Now, each flow reported by FlowExporter includes the local IP address, the local workload identity, and connection start/end timestamps. As FlowCollector receives these flows, it can learn the time ranges during which each workload owns a given IP address. For instance, if FlowCollector sees a flow with local IP address 10.0.0.1 associated with workload X that starts at t1 and ends at t2, it can deduce that 10.0.0.1 belonged to workload X from t1 to t2. Since Netflix uses Amazon Time Sync across its fleet, the timestamps (captured by FlowExporter) are reliable.
The FlowCollector service cluster consists of many nodes. Every node must be capable of attributing arbitrary remote IP addresses and, therefore, requires knowledge of all workload IP addresses and their recent ownership records. To represent this knowledge, each node maintains an in-memory hashmap that maps an IP address to a list of time ranges, as illustrated by the following Go structs:
type IPAddressTracker struct {
ipToTimeRanges map[netip.Addr]timeRanges
}
type timeRanges []timeRange
type timeRange struct {
workloadID string
start time.Time
end time.Time
}To populate the hashmap, FlowCollector extracts the local IP address, local workload identity, start time, and end time from each received flow and creates/extends the corresponding time ranges in the map. The time ranges for each IP address are sorted in ascending order, and they are non-overlapping since an IP address cannot belong to two different workloads simultaneously.
Since each flow is only sent to one FlowCollector node, each node must share the time ranges it learned from received flows with other nodes. We implemented a broadcasting mechanism using Kafka, where each node publishes learned time ranges to all other nodes. Although more efficient broadcasting implementations exist, the Kafka-based approach is simple and has worked well for us.
Now, FlowCollector can attribute remote IP addresses by looking them up in the populated map, which returns a list of time ranges. It then uses the flow’s start timestamp to determine the corresponding time range and associated workload identity. If the start time does not fall within any time range, FlowCollector will retry after a delay, eventually giving up if the retry fails. Such failures may occur when flows are lost or broadcast messages are delayed. For our use cases, it is acceptable to leave a small percentage of flows unattributed, but any misattribution is unacceptable.

This new method achieves accurate attribution thanks to the continuous heartbeats, each associated with a reliable time range of IP address ownership. It handles transient issues gracefully — a few delayed or lost heartbeats do not lead to misattribution. In contrast, the previous method relied solely on discrete IP address assignment and unassignment events. Lacking heartbeats, it had to presume an IP address remained assigned until notified otherwise (which can be hours or days later), making it vulnerable to misattribution when the notifications were delayed.
One detail is that when FlowCollector receives a flow, it cannot attribute its remote IP address right away because it requires the latest observed time ranges for the remote IP address. Since FlowExporter reports flows in batches every minute, FlowCollector must wait until it receives the flow batch from the remote workload FlowExporter for the last minute, which may not have arrived yet. To address this, FlowCollector temporarily stores received flows on disk for one minute before attributing their remote IP addresses. This introduces a 1-minute delay, but it is much shorter than the 15-minute delay with the previous approach.
In addition to producing accurate attribution, the new method is also cost-effective thanks to its simplicity and in-memory lookups. Because the in-memory state can be quickly rebuilt when a FlowCollector node starts up, no persistent storage is required. With 30 c7i.2xlarge instances, we can process 5 million flows per second for the entire Netflix fleet.
Attributing Cross-Regional IP Addresses
For simplicity, we have so far glossed over one topic: regionalization. Netflix’s cloud microservices operate across multiple AWS regions. To optimize flow reporting and minimize cross-regional traffic, a FlowCollector cluster runs in each major region, and FlowExporter agents send flows to their corresponding regional FlowCollector. When FlowCollector receives a flow, its local IP address is guaranteed to be within the region.
To minimize cross-region traffic, the broadcasting mechanism is limited to FlowCollector nodes within the same region. Consequently, the IP address time ranges map contains only IP addresses from that region. However, cross-regional flows have a remote IP address in a different region. To attribute these flows, the receiving FlowCollector node forwards them to nodes in the corresponding region. FlowCollector determines the region for a remote IP address by looking up a trie built from all Netflix VPC CIDRs. This approach is more efficient than broadcasting IP address time range updates across all regions, as only 1% of Netflix flows are cross-regional.
Attributing Non-Workload IP Addresses
So far, FlowCollector can accurately attribute IP addresses belonging to Netflix’s cloud workloads. However, not all flow IP addresses fall into this category. For instance, a significant portion of flows goes through AWS ELBs. For these flows, their remote IP addresses are associated with the ELBs, where we cannot run FlowExporter. Consequently, FlowCollector cannot determine their identities by simply observing the received flows. To attribute these remote IP addresses, we continue to use IP address change events from Sonar, which crawls AWS resources to detect changes in IP address assignments. Although this data stream may contain inaccurate timestamps and be delayed, misattribution is not a main concern since ELB IP address reassignment occurs very infrequently.
Verifying Correctness
Verifying that the new method has eliminated misattribution is challenging due to the lack of a definitive source of truth for workload dependencies to validate flow logs against; the flow logs themselves are intended to serve as this source of truth, after all. To build confidence, we analyzed the flow logs of a large service with well-understood dependencies. A large footprint is necessary, as misattribution is more prevalent in services with numerous instances, and there must be a reliable method to determine the dependencies for this service without relying on flow logs.
Netflix’s cloud gateway, Zuul, served this purpose perfectly due to its extensive footprint (handling all cloud ingress traffic), its large number of downstream dependencies, and our ability to derive its dependencies from its routing configurations as the source of truth for comparison with flow logs. We found no misattribution for flows through Zuul over a two-week window. This provided strong confidence that the new attribution method has eliminated misattribution. In the previous approach, approximately 40% of Zuul’s dependencies reported by the flow logs were misattributed.
Conclusion
With misattribution solved, eBPF flow logs now deliver dependable, fleet-wide insights into Netflix’s service topology and network health. This advancement unlocks numerous exciting opportunities in areas such as service dependency auditing, security analysis, and incident triage, while helping Netflix engineers develop a better understanding of our ever-evolving distributed systems.
Acknowledgments
We would like to thank Martin Dubcovsky, Joanne Koong, Taras Roshko, Nabil Schear, Jacob Meyers, Parsha Pourkhomami, Hechao Li, Donavan Fritz, Rob Gulewich, Amanda Li, John Salem, Hariharan Ananthakrishnan, Keerti Lakshminarayan, and other stunning colleagues for their feedback, inspiration, and contributions to the success of this effort.
![]()
How Netflix Accurately Attributes eBPF Flow Logs was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source: Read MoreÂ