
Azure Cosmos DB for NoSQL now supports hybrid search, it is a powerful feature that combines full-text search and vector search to deliver highly relevant and accurate results. This blog post provides a comprehensive guide for developers and architects to understand, implement, and leverage hybrid search capabilities in their applications.
- What is hybrid search?
- How hybrid search works in Cosmos DB
- Vector embedding
- Implementing hybrid search
- Enable hybrid search.
- Container set-up and indexing
- Data Ingestion
- Search Queries
- Code Example
What is Hybrid Search?
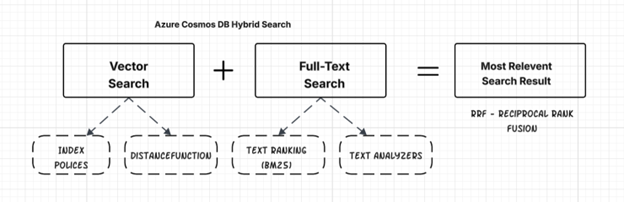
Hybrid search is an advanced search technology that combines keyword search (also known as full-text search) and vector search to deliver more accurate and relevant search results. It leverages the strengths of both approaches to overcome the limitations of each when used in isolation.
Key Components
- Full-Text Search: This traditional method matches the words you type in, using techniques like stemming, lemmatization, and fuzzy matching to find relevant documents. It excels at finding exact matches and is efficient for structured queries with specific terms. Employs the BM25 algorithm to evaluate and rank the relevance of records based on keyword matching and text relevance.
- Vector Search: This method uses machine learning models to represent queries and documents as numerical embeddings in a multidimensional space, allowing the system to find items with similar characteristics and relationships, even if the exact keywords don’t match. Vector search is particularly useful for finding information that’s conceptually similar to the search query.
- Reciprocal Rank Fusion (RRF): This algorithm merges the results from both keyword and vector search, creating a single, unified ranked list of documents. RRF ensures that relevant results from both search types are fairly represented.
Hybrid search is suitable for various use cases, such as:
- Retrieval Augmented Generation (RAG) with LLMs
- Knowledge management systems: Enabling employees to efficiently find pertinent information within an enterprise knowledge base.
- Content Management: Efficiently search through articles, blogs, and documents.
- AI-powered chatbots
- E-commerce platforms: Helping customers find products based on descriptions, reviews, and other text attributes.
- Streaming services: Helping users find content based on specific titles or themes.
Let’s understand vector search and full-text search before diving into hybrid search implementation.
Understanding of Vector Search
Vector search in Azure Cosmos DB for NoSQL is a powerful feature that allows you to find similar items based on their semantic meaning, rather than relying on exact matches of keywords or specific values. It is a fundamental component for building AI applications, semantic search, recommendation engines, and more.
Here’s how vector search works in Cosmos DB:
Vector embeddings
Vector embeddings are numerical representations of data in a high-dimensional space, capturing their semantic meaning. In this space, semantically similar items are represented by vectors that are closer to each other. The dimensionality of these vectors can be quite large. We have separate topics in this blog on how to generate vector embedding.
Storing and indexing vectors
Azure Cosmos DB allows you to store vector embeddings directly within your documents. You define a vector policy for your container to specify the vector data’s path, data type, and dimensions. Cosmos DB supports various vector index types to optimize search performance, accuracy, and cost:
- Flat: Provides exact k-nearest neighbor (KNN) search.
- Quantized Flat: Offers exact search on compressed vectors.
- DiskANN: Enables highly scalable and accurate Approximate Nearest Neighbor (ANN) search.
Querying
- Azure Cosmos DB provides the VectorDistance() system function, which can be used within SQL queries to perform vector similarity searches as part of vector search.
Understanding Full-Text Search
Azure Cosmos DB for NoSQL now offers full-text search functionality (feature is in preview at this time for certain Azure regions), allowing you to perform powerful and efficient text-based searches within your documents directly in the database. This significantly enhances your application’s search capabilities without the need for an external search service for basic full-text needs.
Indexing
To enable full-text search, you need to define a full-text policy specifying the paths for searching and add a full-text index to your container’s indexing policy. Without the index, full-text searches would perform a full scan. Indexing involves tokenization, stemming, and stop word removal, creating a data structure like an inverted index for fast retrieval. Multi-language support (beyond English) and stop word removal are in early preview.
Querying
Cosmos DB provides system functions for full-text search in the NoSQL query language. These include FullTextContains, FullTextContainsAll, and FullTextContainsAny for filtering in the WHERE clause. The FullTextScore function uses the BM25 algorithm to rank documents by their relevance.
How Hybrid Search works in Cosmos DB
- Data Storage: Your documents in Cosmos DB include both text fields (for full-text search) and vector embedding fields (for vector search).
- Indexing:
- Full-Text Index: A full-text policy and index are configured on your text fields, enabling keyword-based searches.
- Vector Index: A vector policy and index are configured on your vector embedding fields, allowing for efficient similarity searches based on semantic meaning.
- Querying: A single query request is used to initiate hybrid search, including both full-text and vector search parameters.
- Parallel Execution: The vector and full-text search components run in parallel.
- VectorDistance() measures vector similarity.
- FullTextContains() or similar functions find keyword matches, and `FullTextScore()` ranks results using BM25.
- Result Fusion: The RRF function merges the rankings from both searches (vector & full text), creating a combined, ordered list based on overall relevance.
- Enhanced Results: The final results are highly relevant, leveraging both semantic understanding and keyword precision.
Vector Embedding
Vector embedding refers to the process of transforming data (like text, images) into a series of numbers, or a vector, that captures its semantic meaning. In this n-dimensional space, similar data points are mapped closer together, allowing computers to understand and analyze relationships that would be difficult with raw data.
To support hybrid search in Azure Cosmos DB, enhance the data by generating vector embeddings from searchable text fields. Store these embeddings in dedicated vector fields alongside the original content to enable both semantic and keyword-based queries.
Steps to generate embeddings with Azure OpenAI models
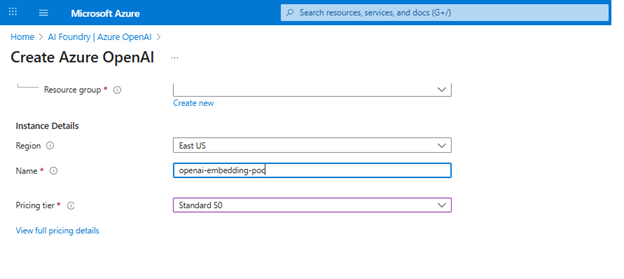
Provision Azure OpenAI Resource
- Sign in to the Azure portal: Go to https://portal.azure.com and log in.
- Create a resource: Select “Create a resource” from the Azure dashboard and search for “Azure OpenAI”.
Deploy Embedding Model
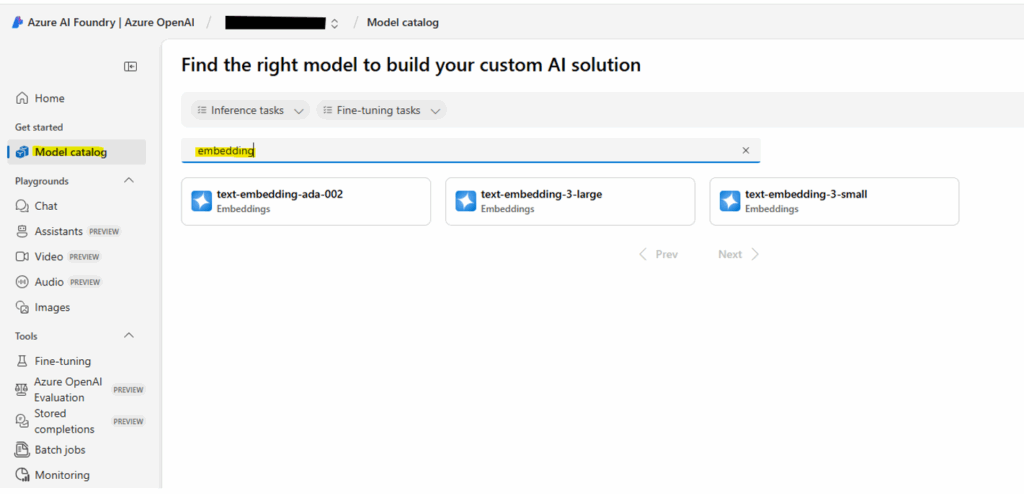
- Navigate to your newly created Azure OpenAI resource and click on “Explore Azure AI Foundry portal” in the overview page.
- Go to the model catalog and search for embedding models.
- Select embedding model:
- From the embedding model list, choose an embedding model like text-embedding-ada-002, text-embedding-3-large, or text-embedding-3-small.
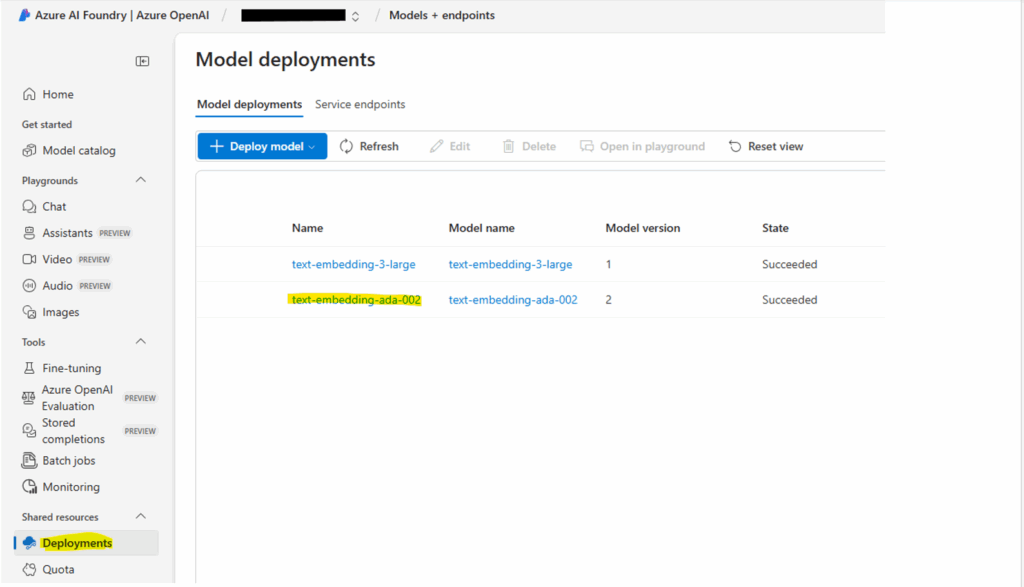
- Deployment name: Provide a unique name for your deployment. This name is crucial for accessing the model via the API.
- Deploy the model: Click “Create” to deploy the embedding model.
- After deployment, the resource will appear under the ‘Deployments’ section.
Accessing and utilizing embeddings
- Endpoint and API Key: After deployment, navigate to your Azure OpenAI resource and find the “Keys and Endpoint” under “Resource Management”. Copy these values as they are needed for authenticating API calls.
- Integration with applications: Use the Azure OpenAI SDK or REST APIs in your applications, referencing the deployment name and the retrieved endpoint and API key to generate embeddings.
Code example for .NET Core
Note: Ensure you have the .NET Core 8 SDK installed
using Azure;
using Azure.AI.OpenAI;
using System;
using System.Linq;
namespace AzureOpenAIAmbeddings
{
class Program
{
static async Task Main(string[] args)
{
// Set your Azure OpenAI endpoint and API key securely
string endpoint = Environment.GetEnvironmentVariable("AZURE_OPENAI_ENDPOINT") ?? "https://YOUR_RESOURCE_NAME.openai.azure.com/"; // Replace with OpenAI endpoint
string apiKey = Environment.GetEnvironmentVariable("AZURE_OPENAI_API_KEY") ?? "YOUR_API_KEY"; // Replace with OpenAI API key
// Create an AzureOpenAIAClient
var credentials = new AzureKeyCredential(apiKey);
var openaiClient = new OpenAIClient(new Uri(endpoint), credentials);
// Create embedding options
EmbeddingOptions embeddingOptions = new()
{
DeploymentName = "text-embedding-ada-002", // Replace with your deployment name
Input = { "Your text for generating embedding" }, // Text that require to generate embedding
};
// Generate embeddings
var returnValue = await openaiClient.GetEmbeddingsAsync(embeddingOptions);
//Store generated embedding data to Cosmos DB along with your text content
var embedding = returnValue.Value.Data[0].Embedding.ToArray()
}
}
}
Implementing Hybrid search
Implementing hybrid search in Azure Cosmos DB for NoSQL involves several key steps to combine the power of vector search and full-text search. This diagram illustrates the architecture of Hybrid Search in Azure Cosmos DB, leveraging Azure OpenAI for generating embedding, combining both vector-based and keyword-based search:
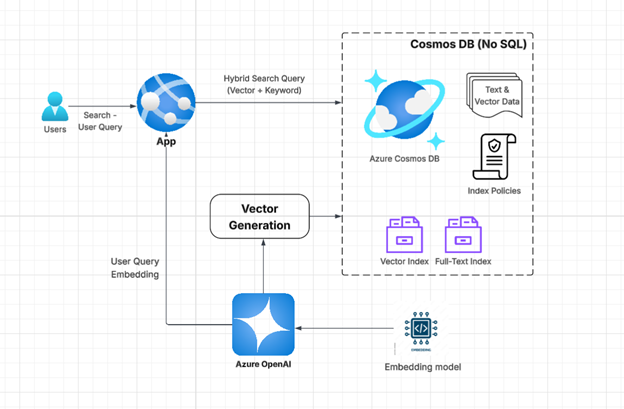
Step 1: Enable hybrid search in the Cosmos DB account
To implement hybrid search in Cosmos DB, begin by enabling both vector search and full-text search on the Azure Cosmos DB account.
- Navigate to Your Azure Cosmos DB for NoSQL Resource Page
-
Access the Features Pane:
- Select the “Features” pane under the “Settings” menu item.
-
Enable Vector Search:
- Locate and select the “Vector Search for NoSQL.” Read the description to understand the feature.
- Click “Enable” to activate vector indexing and search capabilities.

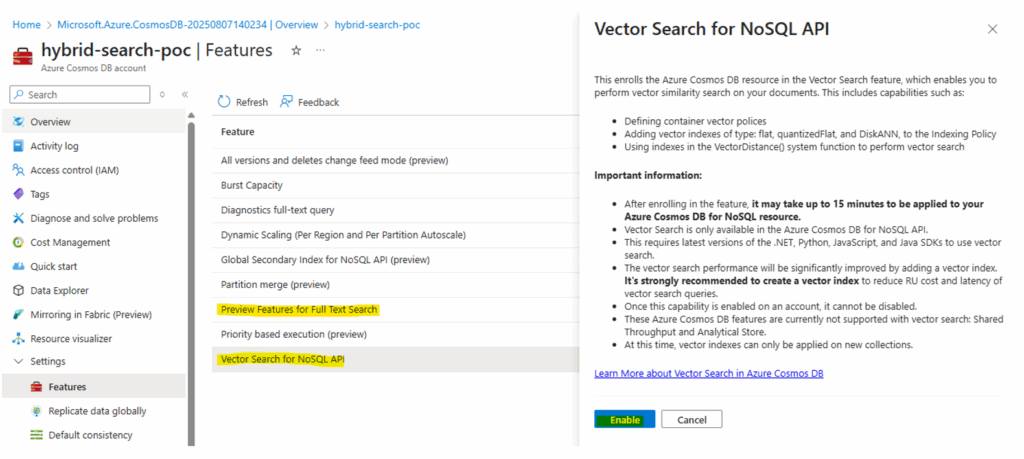
-
Enable Full-Text Search:
- Locate and select the “Preview Feature for Full-Text Search” (Full-Text Search for NoSQL API (preview)). Read the description to confirm your intention to enable it.
- Click “Enable” to activate full-text indexing and search capabilities.
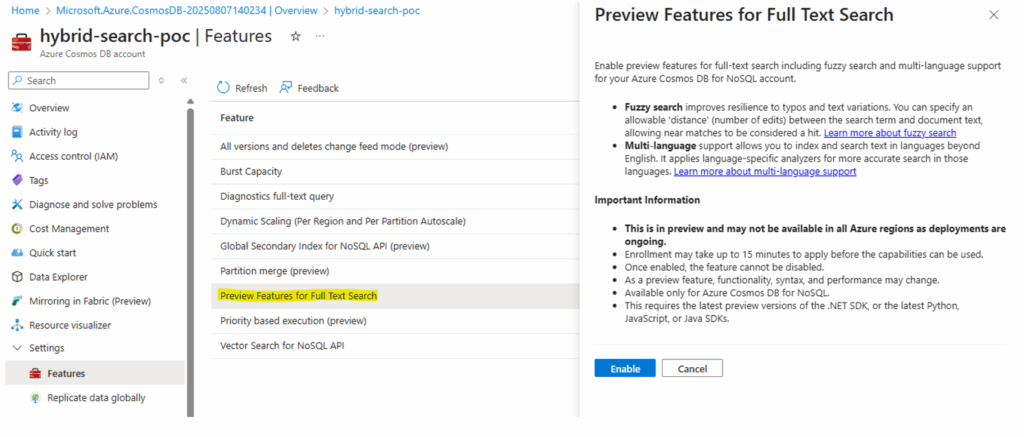
Notes:
-
-
- Once these features are enabled, they cannot be disabled.
- Full Text Search (preview) may not be available in all regions at this time.
-
Step 2: Container Setup and Indexing
- Create a database and container or use an existing one.
- Note: Adding a vector index policy to an existing container may not be supported. If so, you will need to create a new container.
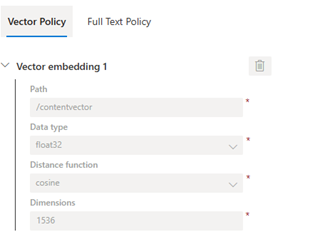
- Define the Vector embedding policy on the container
- You need to specify a vector embedding policy for the container during its creation. This policy defines how vectors are treated at the container level.
-
{ "vectorEmbeddings": [ { "path":"/contentvector", "dataType":"float32", "distanceFunction":"cosine", "dimensions":1536 }, }- Path: Specify the JSON path to your vector embedding field (e.g., /contentvector).
- Data type: Define the data type of the vector elements (e.g., float32).
- Dimensions: Specify the dimensionality of your vectors (e.g., 1536 for text-embedding-ada-002).
- Distance Function: Choose the distance metric for similarity calculation (e.g., cosine, dotProduct, or euclidean)
- Add Vector Index: Add a vector index to your container’s indexing policy. This enables efficient vector similarity searches.
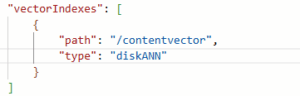
-
-
- Path: Include the same vector path defined in your vector policy.
- Type: Select the appropriate index type (flat, quantizedFlat, or diskANN).
-
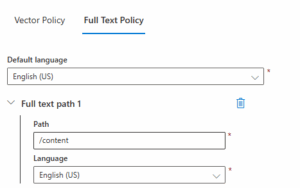
- Define Full-Text Policy: Define a container-level full-text policy. This policy specifies which paths in your documents contain the text content that you want to search.
-
-
- Path: Specify the JSON path to your text search field
- Language: content language
-
- Add Full-Text Index: Add a full-text index to the indexing policy, making full-text searches efficient

Hybrid search index (both Full-Text and Vector index)
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/_etag*/?"
},
{
"path": "/contentvector/*"
}
],
"fullTextIndexes": [
{
"path": "/content"
},
{
"path": "/description"
}
],
"vectorIndexes": [
{
"path": "/contentvector",
"type": "diskANN"
}
]
}
Exclude the Vector Path:
- To optimize performance during data ingestion, you must add the vector path to the “excludedPaths” section of your indexing policy. This prevents the vector path from being indexed by the default range indexes, which can increase RU charges and latency.
Step 3: Data Ingestion
- Generate Vector Embeddings: For every document, convert the text content (and potentially other data like images) into numerical vector embeddings using an embedding model (e.g., from Azure OpenAI Service). This topic is covered above.
- Populate Documents: Insert documents into your container. Each document should have:
- The text content in the fields specified in your full-text policy (e.g., content, description).
- The corresponding vector embedding in the field is specified in your vector policy (e.g., /contentvector).
- Example document

Step 4: Search Queries
Hybrid search queries in Azure Cosmos DB for NoSQL combine the power of vector similarity search and full-text search within a single query using the Reciprocal Rank Fusion (RRF) function. This allows you to find documents that are both semantically similar and contain specific keywords.
SQL: SELECT TOP 10 * FROM c ORDER BY RANK RRF(VectorDistance(c.contentvector, @queryVector), FullTextScore(c.content, @searchKeywords))
VectorDistance(c. contentvector, @queryVector):
- VectorDistance(): This is a system function that calculates the similarity score between two vectors.
- @queryVector: This is a parameter representing the vector embedding of your search query. You would generate this vector embedding using the same embedding model used to create document vector embeddings.
- Return Value: Returns a similarity score based on the distance function defined in your vector policy (e.g., cosine, dot product, Euclidean).
FullTextScore(c.content, @searchKeywords):
- FullTextScore(): This is a system function that calculates a BM25 score, which evaluates the relevance of a document to a given set of search terms. This function relies on a full-text index on the specified path.
- @searchKeywords: This is a parameter representing the keywords or phrases you want to search for. You can provide multiple keywords separated by commas.
- Return Value: Returns a BM25 score, indicating the relevance of the document to the search terms. Higher scores mean greater relevance.
ORDER BY RANK RRF(…):
- RRF(…) (Reciprocal Rank Fusion): This is a system function that combines the ranked results from multiple scoring functions (like VectorDistance and FullTextScore) into a single, unified ranking. RRF ensures that documents that rank highly in either the vector search or the full-text search are prioritized in the final results.
Weighted hybrid search query:
SELECT TOP 10 * FROM c ORDER BY RANK RRF(VectorDistance(c.contentvector, @queryVector), FullTextScore(c.content, @searchKeywords), [2, 1]).
- Optional Weights: You can optionally provide an array of weights as the last argument to RRF to control the relative importance of each component score. For example, to weight the vector search twice as important as the full-text search, you could use RRF(VectorDistance(c.contentvector, @queryVector), FullTextScore(c.content, @searchKeywords), [2,1]).
Multi-field hybrid search query:
SELECT TOP 10 * FROM c ORDER BY RANK RRF(VectorDistance(c.contentvector, @queryVector),VectorDistance(c.imagevector, @queryVector),
FullTextScore(c.content, @searchKeywords, FullTextScore(c.description, @searchKeywords, [3,2,1,1]).
Code Example (.NET Core C#)
- Add Cosmos DB and OpenAI SDKs
- Get Cosmos DB connection string and create Cosmos DB client
- Get the OpenAI endpoint and key to create an OpenAI client
- Generate embedding for user query
- A hybrid search query to do a vector and keyword search
using Microsoft.Azure.Cosmos;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
namespace CosmosHybridSearch
{
public class Product
{
public string Id { get; set; }
public string Name { get; set; }
public float[] DescriptionVector { get; set; } // Your vector embedding property
}
public class Program
{
private static readonly string EndpointUri = "YOUR_COSMOS_DB_ENDPOINT";
private static readonly string PrimaryKey = "YOUR_COSMOS_DB_PRIMARY_KEY";
private static readonly string DatabaseId = "YourDatabaseId";
// Set your Azure OpenAI endpoint and API key securely.
string endpoint = Environment.GetEnvironmentVariable("AZURE_OPENAI_ENDPOINT") ?? "https://YOUR_RESOURCE_NAME.openai.azure.com/"; // Replace with your endpoint
string apiKey = Environment.GetEnvironmentVariable("AZURE_OPENAI_API_KEY") ?? "YOUR_API_KEY"; // Replace with your API key
public static async Task Main(string[] args)
{
using CosmosClient client = new(EndpointUri, PrimaryKey);
Database database = await client.CreateDatabaseIfNotExistsAsync(DatabaseId);
Container container = database.GetContainer(ContainerId);
// Create an AzureOpenAiEmbeddings instance - not online :)
var credentials = new ApiKeyServiceClientCredentials(apiKey);
AzureOpenAiEmbeddings openAiClient = new(endpoint, credentials);
// Example: search your actual query vector and search term.
float[] queryVector;
string searchTerm = "lamp";
EmbeddingOptions embeddingOptions = new()
{
DeploymentName = "text-embedding-ada-002", // Replace with your deployment name
Input = searchTerm,
};
var queryVectorResponse = await openAICient.GetEmbeddingsAsync(embeddingOptions);
queryVector = returnValue.Value.Data[0].Embedding.ToArray()
// Define the hybrid search query using KQL
QueryDefinition queryDefinition = new QueryDefinition(
"SELECT top 10 * " +
"FROM myindex " +
"ORDER BY _vectorScore(desc, @queryVector), FullTextScore(_description, @searchTerm)")
.WithParameter("@queryVector", queryVector)
.WithParameter("@searchTerm", searchTerm);
List<Product> products = new List<Product>();
using FeedIterator<Product> feedIterator = container.GetItemQueryIterator<Product>(queryDefinition);
while (feedIterator.HasMoreResults)
{
FeedResponse<Product> response = await feedIterator.ReadNextAsync();
foreach (Product product in response)
{
products.Add(product);
}
}
// Process your search results
foreach (Product product in products)
{
Console.WriteLine($"Product Id: {product.Id}, Name: {product.Name}");
}
}
}
}
Source: Read MoreÂ