
Users notice slow requests; even if 99 % finish quickly, that 1 % “long‑tail” latency can make your app feel sluggish. Request hedging solves this by speculatively firing a second duplicate after a short delay, racing to beat out outliers before they ever impact the UI.
Why the slowest 1 % of requests matter
- The time it takes for the slowest 1 % of requests to finish is known as P99 latency. (P99.9 is the slowest 0.1 %, and so on.)
- Users are sensitive to slowness. One long request is all it takes for an app to feel sluggish.
- In an architectures where a page render hits 50 microservices, one bad service can drag the whole page down.
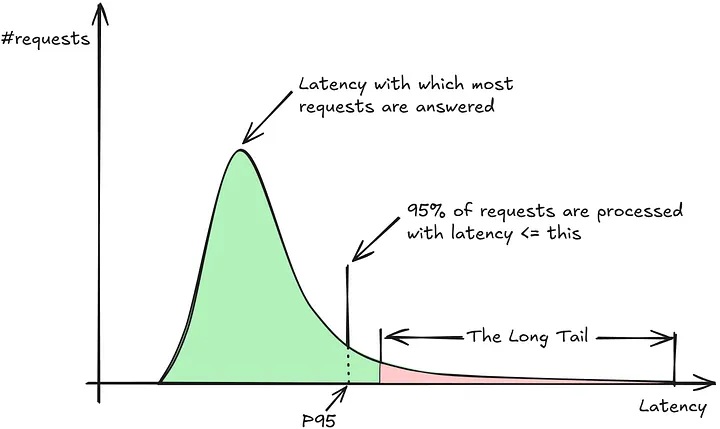
Google’s Bigtable team discovered that firing a second copy of a read after just 10 milliseconds cut their P99.9 latency by 96 % while adding only 2 % extra traffic. That’s cheaper than a single extra VM instance and far more predictable.
What exactly is request hedging?
Send the original request; if no response arrives within a small hedge delay, send a duplicate to another healthy replica. Return whichever finishes first and cancel the other.
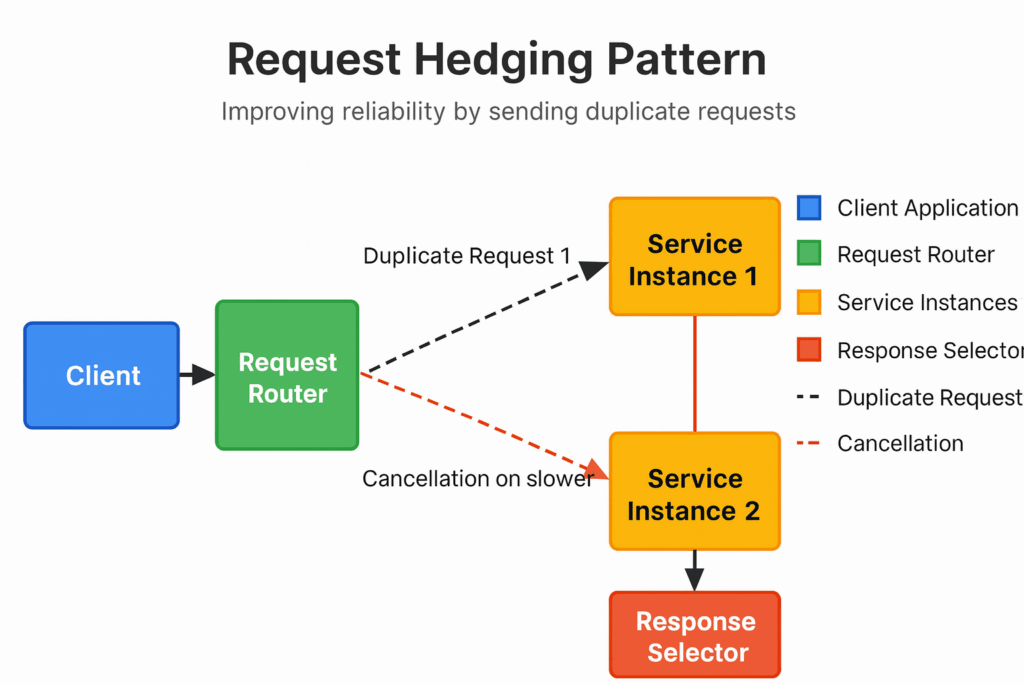
Why it works:
- Outliers are random. Network hiccups don’t hit every server at once.
- Cheap insurance. Most requests finish fast, so the duplicate rarely runs long. You pay a small burst of extra load to avoid a big, visible stall.
How to fit hedging into a Next.js + Sitecore Headless + . NET stack
1. Next.js – browser or Vercel Edge
<span class="token comment">// lightweight helper (TypeScript)</span>
<span class="token keyword">export</span> <span class="token keyword">async</span> <span class="token keyword">function</span> <span class="token function">hedgedFetch</span><span class="token punctuation">(</span>urls<span class="token operator">:</span> <span class="token builtin">string</span><span class="token punctuation">[</span><span class="token punctuation">]</span><span class="token punctuation">,</span> delayMs <span class="token operator">=</span> <span class="token number">50</span><span class="token punctuation">)</span> <span class="token punctuation">{</span>
<span class="token keyword">const</span> controller <span class="token operator">=</span> <span class="token keyword">new</span> <span class="token class-name">AbortController</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token keyword">const</span> timer <span class="token operator">=</span> <span class="token function">setTimeout</span><span class="token punctuation">(</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token operator">=></span> <span class="token punctuation">{</span>
<span class="token keyword">if</span> <span class="token punctuation">(</span>urls<span class="token punctuation">.</span>length <span class="token operator">></span> <span class="token number">1</span><span class="token punctuation">)</span> <span class="token function">fetch</span><span class="token punctuation">(</span>urls<span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">,</span> <span class="token punctuation">{</span> signal<span class="token operator">:</span> controller<span class="token punctuation">.</span>signal <span class="token punctuation">}</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token punctuation">}</span><span class="token punctuation">,</span> delayMs<span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token keyword">try</span> <span class="token punctuation">{</span>
<span class="token keyword">const</span> winner <span class="token operator">=</span> <span class="token keyword">await</span> <span class="token builtin">Promise</span><span class="token punctuation">.</span><span class="token function">any</span><span class="token punctuation">(</span>
urls<span class="token punctuation">.</span><span class="token function">map</span><span class="token punctuation">(</span>u <span class="token operator">=></span> <span class="token function">fetch</span><span class="token punctuation">(</span>u<span class="token punctuation">,</span> <span class="token punctuation">{</span> signal<span class="token operator">:</span> controller<span class="token punctuation">.</span>signal <span class="token punctuation">}</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token keyword">return</span> winner<span class="token punctuation">;</span>
<span class="token punctuation">}</span> <span class="token keyword">finally</span> <span class="token punctuation">{</span>
<span class="token function">clearTimeout</span><span class="token punctuation">(</span>timer<span class="token punctuation">)</span><span class="token punctuation">;</span>
controller<span class="token punctuation">.</span><span class="token function">abort</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token punctuation">}</span>Example: Hedging a front‑end GraphQL fetch
<span class="token keyword">const</span> response <span class="token operator">=</span> <span class="token keyword">await</span> <span class="token function">hedgedFetch</span><span class="token punctuation">(</span><span class="token punctuation">[</span>
<span class="token string">"https://edge-usw.example.com/graphql"</span><span class="token punctuation">,</span>
<span class="token string">"https://edge-use.example.com/graphql"</span>
<span class="token punctuation">]</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token keyword">const</span> json <span class="token operator">=</span> <span class="token keyword">await</span> response<span class="token punctuation">.</span><span class="token function">json</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
This code races two region endpoints, returns the fastest response, and cancels the slower request via AbortController. Adjust delayMs if your P95 latency is lower than the default 50 ms.
2. Next.js API routes or App Router server actions
Same pattern, but tune delayMs lower (20–30 ms) because the call is already inside the data‑center.
3. Envoy / Istio sidecars
An Envoy or Istio sidecar is a small proxy container that runs alongside your application container in the same Kubernetes pod. All inbound and outbound traffic passes through this proxy, so you can add behaviors such as retries, TLS, rate‑limiting, and request hedging by updating proxy settings instead of touching application code.
If you skip sidecars in your Next.js application
You can still hedge browser and server‑side calls by writing helpers (like hedgedFetch) or using Polly/gRPC policies. However, each service must implement and maintain its own logic, and any calls that come into your app from other services will not be hedged, leaving long‑tail spikes unprotected. Over time this scattered approach increases maintenance overhead and risks inconsistent latency behavior across the stack.
<span class="token key atrule">route</span><span class="token punctuation">:</span>
<span class="token key atrule">per_filter_config</span><span class="token punctuation">:</span>
<span class="token key atrule">envoy.hedging</span><span class="token punctuation">:</span>
<span class="token key atrule">hedge_on_per_try_timeout</span><span class="token punctuation">:</span> <span class="token boolean important">true</span>
<span class="token key atrule">initial_hedge_delay</span><span class="token punctuation">:</span> 0.02s <span class="token comment"># 20 ms</span>
<span class="token key atrule">max_requests</span><span class="token punctuation">:</span> <span class="token number">2</span>
Put this in a VirtualService (Istio) or Route Configuration (raw Envoy) to hedge any calls that are safe to repeat without side effects (e.g., GET /product/123), otherwise known as idempotent.
4. .NET back‑end callers
What is gRPC? gRPC (short for Google Remote Procedure Call) is an open‑source framework that lets services invoke functions on other services as though they were local methods. It rides on HTTP/2 for efficient, multiplexed connections, uses Protocol Buffers for small binary messages, and generates type‑safe client and server code in many languages. Built‑in features like deadlines, retries, and hedging policies make it a natural place to enable request hedging without extra plumbing.
- gRPC
<span class="token punctuation">{</span> <span class="token property">"methodConfig"</span><span class="token operator">:</span> <span class="token punctuation">[</span><span class="token punctuation">{</span> <span class="token property">"name"</span><span class="token operator">:</span> <span class="token punctuation">[</span><span class="token punctuation">{</span> <span class="token property">"service"</span><span class="token operator">:</span> <span class="token string">"ProductCatalog"</span> <span class="token punctuation">}</span><span class="token punctuation">]</span><span class="token punctuation">,</span> <span class="token property">"hedgingPolicy"</span><span class="token operator">:</span> <span class="token punctuation">{</span> <span class="token property">"maxAttempts"</span><span class="token operator">:</span> <span class="token number">2</span><span class="token punctuation">,</span> <span class="token property">"hedgingDelay"</span><span class="token operator">:</span> <span class="token string">"0.03s"</span><span class="token punctuation">,</span> <span class="token property">"nonFatalStatusCodes"</span><span class="token operator">:</span> <span class="token punctuation">[</span><span class="token string">"UNAVAILABLE"</span><span class="token punctuation">,</span> <span class="token string">"DEADLINE_EXCEEDED"</span><span class="token punctuation">]</span> <span class="token punctuation">}</span> <span class="token punctuation">}</span><span class="token punctuation">]</span> <span class="token punctuation">}</span>
HTTP
builder<span class="token punctuation">.</span>Services<span class="token punctuation">.</span><span class="token function">AddHttpClient</span><span class="token punctuation">(</span><span class="token string">"edge"</span><span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token function">AddStandardHedgingHandler</span><span class="token punctuation">(</span>o <span class="token operator">=></span> o<span class="token punctuation">.</span>MaxAttempts <span class="token operator">=</span> <span class="token number">2</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
5. Sitecore Experience Edge
Experience Edge already runs in multiple regions. Expose two region‑specific GraphQL URLs to the client and let the hedged fetch pick the fastest.
Roll‑out checklist
- Measure first. Capture your current P50, P95, P99, P99.9 latencies per hop.
- Pick a hedge delay ≈ P95. Too short wastes capacity, too long misses outliers.
- Restrict to idempotent reads. Avoid duplicate writes unless your API supports idempotency keys.
- Cap attempts to two. Start small; you rarely need more.
- Instrument and watch. Expose metrics like
hedged_attempts,cancels, and tail percentiles. Aim for <5 % load overhead.
Risks and how to mitigate them
| Risk | Mitigation |
|---|---|
| Extra traffic / CPU | Monitor overhead; two attempts at most keeps it predictable. |
| Duplicate side effects on POST / PUT | Keep hedging to GET / GraphQL query unless you have idempotency tokens. |
| Window where both copies run | Cancel losers immediately with AbortController, gRPC cancellations, or Envoy resets. |
Key takeaway
Request hedging is a tiny change that brings outsized rewards. A few lines of code (or a single header) can erase those embarrassing long‑tail spikes and make your Next.js + Sitecore + . NET experience feel nearly instantaneous.

Further reading:
Source: Read MoreÂ
