
Abstract
In recent years, language models and AI have reshaped how we interact with data. Yet, a significant portion of business knowledge still resides in relational databases (highly structured but not exactly user-friendly for those unfamiliar with SQL). So what if you could query that data using natural language, as if you were speaking to a smart assistant?
In this post, we’ll walk through a practical proof of concept (POC) using the well-known Northwind database as our data source. We’ll apply Retrieval-Augmented Generation (RAG) techniques to convert structured data into meaningful, searchable knowledge. By combining tools like LangChain, OpenAI Embeddings, and ChromaDB, we’ll build a system that can answer real business questions about customers, orders, and sales (all without writing a single SQL query).
This hands-on example will demonstrate how to turn raw database records into descriptive text, generate semantic embeddings, and store them in a vector database optimized for intelligent retrieval. Finally, we’ll connect a conversational AI model to deliver precise, context-aware answers in plain language.
Our goal isn’t just to show a technical integration (it’s much more than that). We aim to explore a new way of accessing business data that’s intuitive, scalable, and aligned with the future of intelligent interfaces. If you’ve ever wondered how to bring your data to life through conversational AI, this is the roadmap you’ve been looking for.
Introduction
Relational databases have been the backbone of enterprise systems for decades, offering structured and reliable storage for vast amounts of business information. However, accessing that data still relies heavily on technical users who are comfortable writing SQL queries (which limits its utility for many other roles within an organization). This post aims to demonstrate how we can transform structured data into accessible knowledge through AI-powered conversational interfaces.
To do this, we’ll build a practical proof of concept using the classic Northwind database (a well-known dataset that includes customers, orders, products, and more). Instead of querying the data directly with SQL, we’ll generate readable and semantically rich descriptions that can be interpreted by a language model. These textual fragments will be converted into embeddings using OpenAI, stored in a vector database powered by ChromaDB, and made retrievable through LangChain, all using Python as the orchestration layer.
Why apply embeddings to tabular data? Because it allows us to move beyond the rigid structure of SELECT statements and JOINs (toward a system where users can ask questions like “Which customer bought the most in 1997?” and receive clear, context-aware answers in natural language). This approach does not replace traditional querying techniques (instead, it complements them), making data access more inclusive and aligned with modern AI-driven experiences.
Ultimately, this opens the door to a new way of working with data (one where conversation replaces complexity and insight becomes truly accessible).
What Are Embeddings?
One of the fundamental challenges in working with language models or textual data is representation. Computers operate on numbers, but words have no inherent numerical value. To bridge this gap, we need a way to transform text into a format that machines can understand while still preserving its semantic meaning. This is precisely where embeddings come into play.
Embeddings are dense vector representations of words, sentences, or even entire documents. Each piece of text is mapped to a real-valued vector—often in a space with hundreds or thousands of dimensions—where semantic relationships can be modeled geometrically. Unlike older methods like one-hot encoding, embeddings allow us to capture similarity: words such as “king” and “queen” appear close together, while unrelated terms like “king” and “lettuce” remain far apart.
The real power of embeddings lies in their ability to reflect meaning. This enables models to reason not just about the surface of the text, but about what it implies—unlocking applications in translation, sentiment analysis, document classification, recommendation systems, semantic search, and, crucially, retrieval-augmented conversational agents.
In the context of this blog, we use embeddings to convert structured database records into descriptive, semantically rich text fragments. These fragments are embedded using a model like OpenAI’s and stored in a vector database. When a user asks a question, it too is embedded, and the system retrieves the most relevant fragments to generate a natural-language answer. This technique is part of what’s known as Retrieval-Augmented Generation (RAG).
Embeddings are commonly produced by pre-trained models from providers like OpenAI, Hugging Face, or Cohere. In our case, we rely on OpenAIEmbeddings, which leverage large-scale transformer models trained on diverse, multilingual datasets optimized for semantic understanding.
One of the greatest advantages of embeddings is their ability to generalize. For instance, a user might ask “Who was the top customer in 1997?” and the system can infer related notions like “highest purchase volume” or “most frequent buyer” without needing exact word matches. This goes far beyond traditional keyword-based search.
Modern embeddings are also contextual. In models like BERT, ELMo, or GPT, the vector for a word depends on its surrounding text. The word “bank” in “sat on the bank” and “deposited money in the bank” will generate entirely different embeddings. This dynamic understanding of context is one reason why these models perform so well in complex language tasks.
In our use case, we apply embeddings to fragments derived from SQL queries, effectively transforming structured information into semantically searchable knowledge. This enables a more natural interaction with data, where users don’t need to understand database schemas or SQL syntax to retrieve meaningful insights.
The pipeline involves embedding each text chunk, storing the resulting vectors in a vector store like ChromaDB, and embedding the user’s query to perform a similarity search. The most relevant matches are passed to a language model, which uses them as context to generate an intelligent, context-aware response.
This method not only streamlines access to information but also enhances accuracy by leveraging the semantic proximity between questions and data fragments.
Let’s understand, what is a chunk?
In the context of language models and semantic search, chunks refer to small, meaningful segments of text that have been split from a larger document. Rather than processing an entire file or paragraph at once, the system breaks down the content into manageable pieces (usually a few hundred characters long with some overlap between them). This technique allows the model to better understand and retrieve relevant information during a query.
Chunking is essential when working with long documents or structured data transformed into natural language. It ensures that each piece maintains enough context to be useful while staying within the token limits of the language model. For example, an entire order history from a database might be divided into chunks that describe individual transactions, making it easier for the system to locate and reason over specific details.
This process not only improves the efficiency of embedding generation and similarity search but also enhances the relevance of responses provided by the conversational agent.
LangChain and ChromaDB: Connecting Language Models to Meaningful Data
To build a system where users can ask questions in natural language and receive intelligent, relevant answers, we need more than just a powerful language model (we need a framework that can manage context, memory, and retrieval). That’s where LangChain comes in.
LangChain is an open-source framework designed to help developers integrate large language models (LLMs) with external data sources and workflows. Rather than treating the model as a black box, LangChain provides structured components (like prompt templates, memory modules, agents, and chains) that make it easier to build dynamic, stateful, and context-aware applications. One of its most popular use cases is Retrieval-Augmented Generation (RAG) (where the model uses external knowledge retrieved from a document store to improve its responses).
To make this retrieval process efficient and accurate, LangChain works seamlessly with ChromaDB.
ChromaDB is a lightweight, high-performance vector database optimized for storing and querying embeddings. It enables fast similarity searches (allowing the system to retrieve the most semantically relevant pieces of information based on a user’s query). This makes Chroma ideal for use in search engines, recommendation systems, and conversational agents.
In a LangChain workflow, ChromaDB serves as the brain’s long-term memory. It stores the embedded representations of documents or data fragments, and returns the most relevant ones when queried. These fragments are then injected into the language model as context (resulting in more accurate and grounded responses).
Together, LangChain and ChromaDB bridge the gap between raw data and intelligent conversation.
Proof of Concept: From SQL Rows to Smart Conversations
In this section, we’ll walk through the steps of building a fully functional proof of concept. Our goal: enable users to ask questions in plain language (such as “Which customers placed the most orders in 1997?”) and get accurate answers generated using data from a relational database.
We’ll use the classic Northwind database, which contains tables for customers, orders, products, and more. Instead of querying it directly with SQL, we’ll extract meaningful data, turn it into descriptive text fragments, generate semantic embeddings, and store them in ChromaDB. Then, we’ll use LangChain to retrieve relevant chunks and feed them to OpenAI’s language model (turning structured data into natural conversation).
For this Proof of Concept you must follow the following steps:
Step 0: Environment setup
Before diving into building the intelligent assistant, it’s essential to prepare a clean and isolated development environment. This ensures that all dependencies are properly aligned, and avoids conflicts with other global Python packages or projects. Here’s how to set up everything from scratch.
Create Embedding Depployment
Before we can generate embeddings from our text data, we need to create a deployment for an embedding model within our Azure OpenAI resource. This deployment acts as the gateway through which we send text and receive vector representations in return.
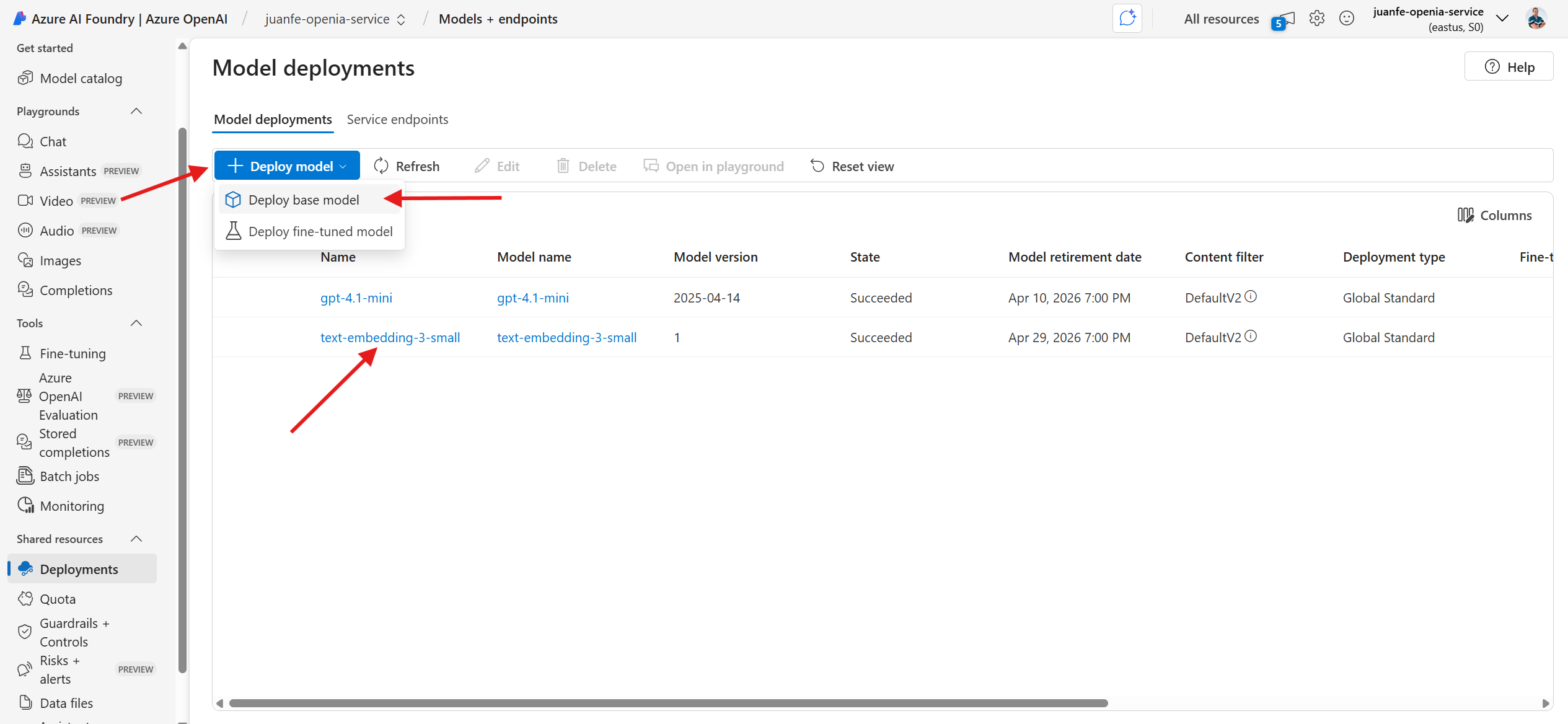
Figure 1: Azure OpenAI – Embedding and Chat Model Deployments.
To begin, navigate to your Azure OpenAI resource in the Azure Portal. Select the Deployments tab, then click + Create to initiate a new deployment. Choose the model text-embedding-3-small from the dropdown list (this is one of the most efficient and semantically rich models currently available). Assign a unique name to your deployment—for example, text-embedding-3-small—and ensure you take note of this name, as it will be required later in your code.
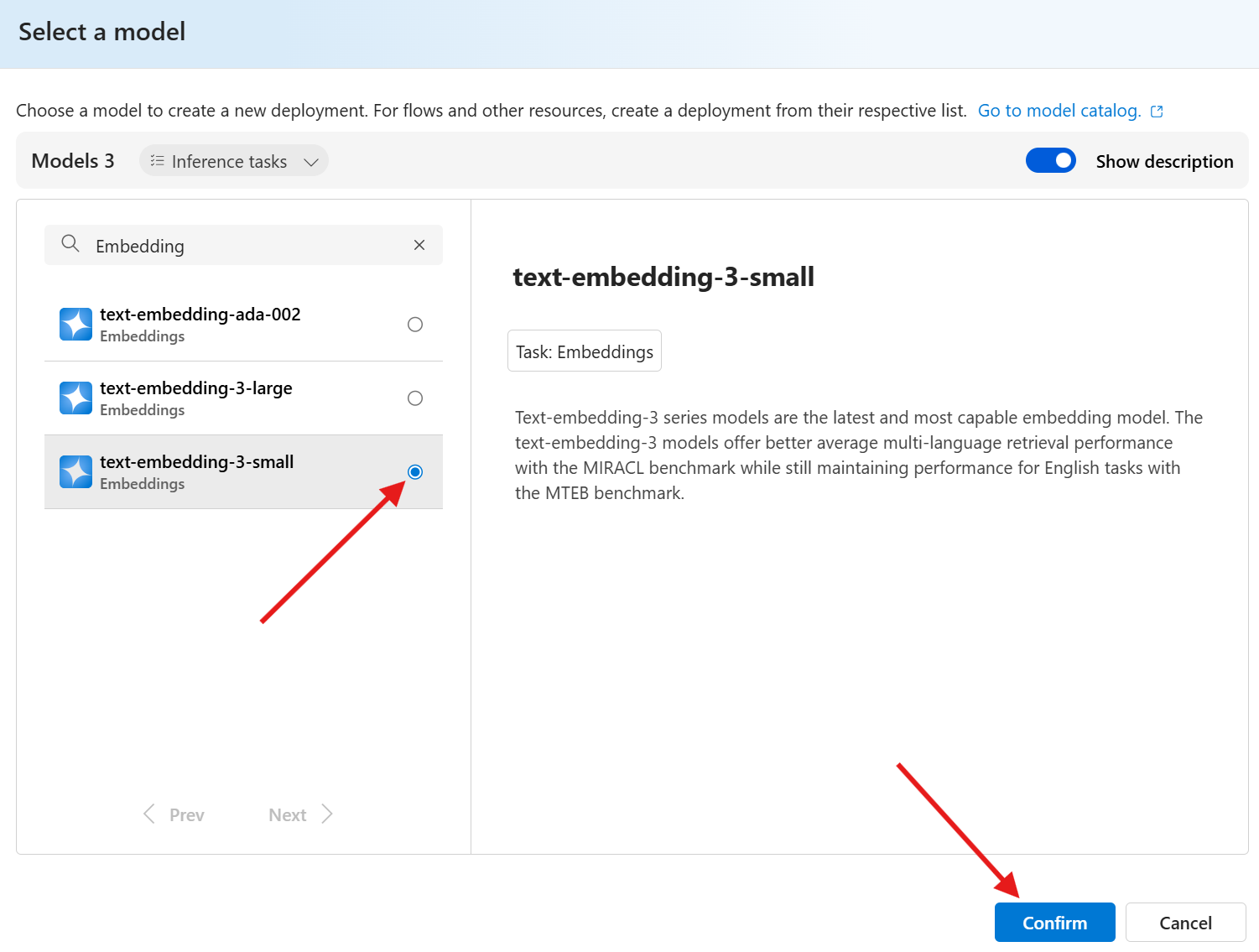
Figure 2: Selecting the Text Embedding Model (text-embedding-3-small) in Azure OpenAI.
Once deployed, Azure will expose a dedicated endpoint along with your API key. These credentials will allow your application to communicate securely with the deployed model. Be sure to also confirm the API version associated with the model (such as 2024-02-01) and verify that this matches the version specified in your code or environment variables.
By completing this step, you set up the foundation for semantic understanding in your application. The embedding model will convert text into high-dimensional vectors that preserve the meaning and context of the input, enabling powerful similarity search and retrieval capabilities later on in your pipeline.
LLM Model Deployment
Don’t forget to configure the LLM model as well (such as gpt-4.1-mini), since it will be responsible for generating responses during the interaction phase of the implementation.

Figure 3: Deploying the LLM Base Model in Azure OpenAI (gpt-4.1-mini).

Figure 4: Selecting a Chat completion Model from Azure OpenAI Catalog.
To connect your application with the deployed LLM, you will need the endpoint URL and the API key shown in the deployment details. This information is essential for authenticating your requests and sending prompts to the model. In this case, we are using the gpt-4.1-mini deployment with the Azure OpenAI SDK and API key authentication. Once retrieved, these credentials allow your code to securely interact with the model and generate context-aware responses as part of the proof of concept.
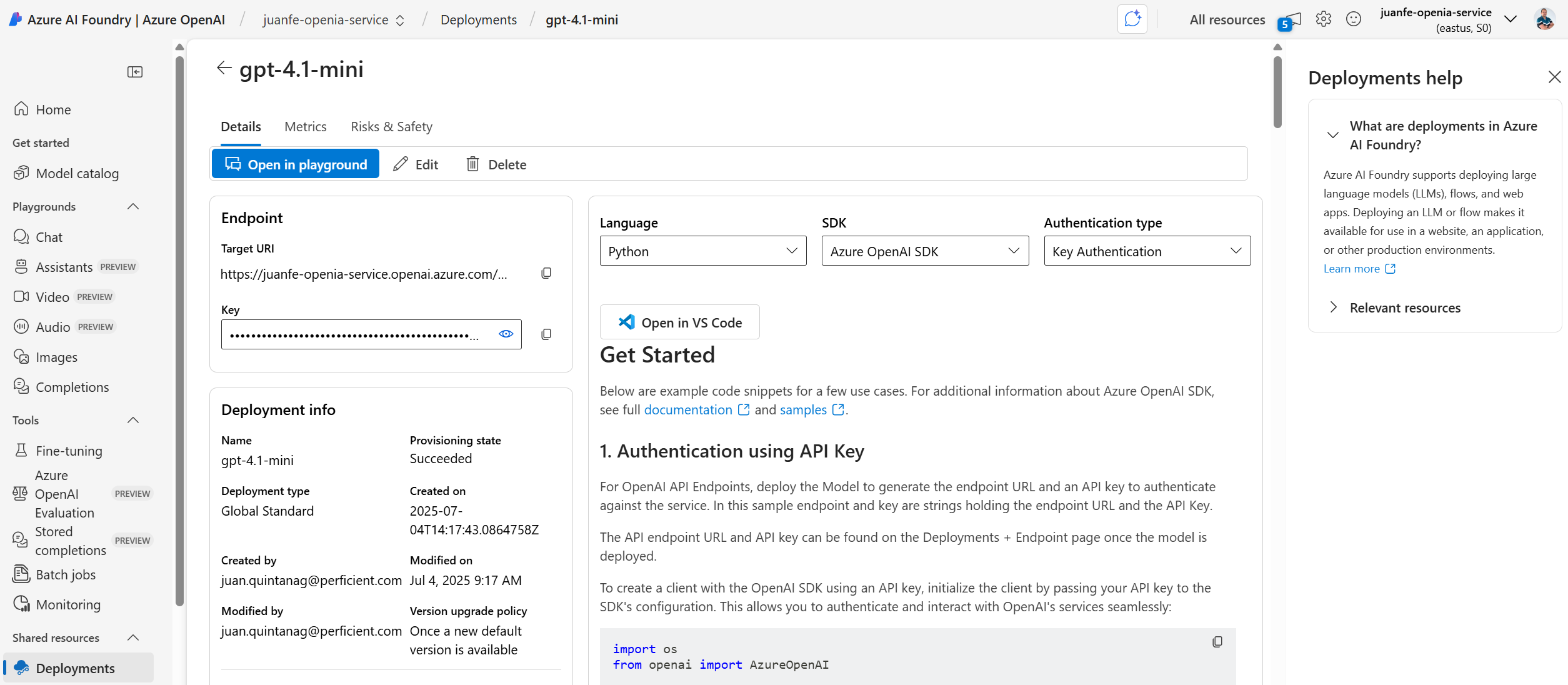
Figure 5: Accessing Endpoint and API Key for gpt-4.1-mini Deployment.
The key information we need from this screenshot to correctly configure our code in the Proof of Concept is the following:
Endpoint URL (Target URI)
(Located under the “Endpoint” section)
This is the base URL you will use to send requests to the deployed model. It’s required when initializing the client in your code.API Key
(Hidden under the “Key” field)
This is your secret authentication token. You must pass it securely in your code to authorize requests to the Azure OpenAI service.Deployment Name
(Shown as “gpt‑4.1‑mini” in the “Deployment info” section)
You will need this name when specifying which model deployment your client should interact with (e.g., when using LangChain or the OpenAI SDK).Provisioning Status
(Shows “Succeeded”)
Confirms that the deployment is ready to use. If this status is anything other than “Succeeded,” the model is not yet available.Model Version and Creation Timestamp
(Optional, for auditing or version control)
Useful for documentation, debugging, or future migration planning.
Create a requirements.txt file
Start by listing all the libraries your project will depend on. Save the following content as requirements.txt in your project root:
pyodbc langchain==0.3.25 openai==1.82.0 chromadb==1.0.10 tiktoken pydantic langchain-core langchain-community langchain-text-splitters langchain-openai==0.1.8
This file defines the exact versions needed for everything—from LangChain and ChromaDB to the Azure OpenAI integration.
Create a virtual environment
To avoid interfering with other Python installations on your machine, use a virtual environment. Run the following command in your terminal:
python -m venv venv
This creates a dedicated folder called venv that holds a self-contained Python environment just for this project.
Activate the virtual environment
Next, activate the environment:
venvScriptsactivate
Once activated, your terminal prompt should change to reflect the active environment.
Install dependencies
Now install all required libraries in one go by running:
pip install -r requirements.txt
This will install all the packages listed in your requirements file, ensuring your environment is ready to connect to the Northwind database and work with LangChain and Azure OpenAI. With everything in place, you’re ready to move on to building the assistant—from querying structured data to transforming it into natural, intelligent responses.
Step 1: Azure OpenAI Configuration
Before diving into code, we need to configure the environment so that our application can access Azure OpenAI services securely and correctly. This involves setting three essential environment variables:
AZURE_OPENAI_API_KEY (your Azure OpenAI API key)
AZURE_OPENAI_ENDPOINT (the full endpoint URL of your Azure OpenAI resource)
AZURE_OPENAI_API_VERSION (the specific API version compatible with your deployed models)
These variables are defined directly in Python using the os.environ method:
# --- 1. Environment setup --- os.environ["AZURE_OPENAI_API_KEY"] = "<ApiKey>" os.environ["AZURE_OPENAI_ENDPOINT"] = "<Endpoint>" os.environ["AZURE_OPENAI_API_VERSION"] = "<AzureOpenIAVersion>"
By setting these values, LangChain will know how to connect to your Azure deployment and access the correct models for embeddings and chat completion.
It’s important to ensure that the deployment names used in your code match exactly the ones configured in your Azure portal. With this step complete, you’re now ready to start connecting to your database and transforming structured data into natural language knowledge.
Step 2: Connecting to the database
With the environment ready, the next step is to connect to the Northwind database and retrieve meaningful records. Northwind is a well-known sample dataset that contains information about customers, employees, orders, products, and their relationships. It offers a rich source of structured data for demonstrating how to turn database rows into conversational context.
To begin, we establish a connection with a local SQL Server instance using pyodbc (a Python driver for ODBC-based databases). Once connected, we execute a SQL query that joins several related tables (Orders, Customers, Employees, Order Details, and Products). This query returns detailed records for each order (including the customer who placed it, the salesperson involved, the date, and the specific products purchased with their quantities, prices, and discounts).
By retrieving all of this information in a single query, we ensure that each order contains enough context to be transformed later into meaningful text that a language model can understand.
# --- 2. Database connection ---
conn = pyodbc.connect(
"DRIVER={ODBC Driver 17 for SQL Server};SERVER=localhost;DATABASE=Northwind;Trusted_Connection=yes;"
)
cursor = conn.cursor()
cursor.execute("""
SELECT
o.OrderID,
c.CompanyName AS Customer,
e.FirstName + ' ' + e.LastName AS Salesperson,
o.OrderDate,
p.ProductName,
od.Quantity,
od.UnitPrice,
od.Discount
FROM Orders o
JOIN Customers c ON o.CustomerID = c.CustomerID
JOIN Employees e ON o.EmployeeID = e.EmployeeID
JOIN [Order Details] od ON o.OrderID = od.OrderID
JOIN Products p ON od.ProductID = p.ProductID
""")
records = cursor.fetchall()Step 3: Transforming records into text
Relational databases are optimized for storage and querying, not for natural language understanding. To bridge that gap, we need to convert structured rows into readable, descriptive sentences that capture the meaning behind the data.
In this step, we take the SQL query results and group them by order. Each order includes metadata (such as customer name, date, and salesperson) along with a list of purchased products. We format this information into short narratives that resemble human-written descriptions.
For example, an entry might read:
“Order 10250 was placed by ‘Ernst Handel’ on 1996-07-08. Salesperson: Nancy Davolio. Items included: 10 x Camembert Pierrot at $34.00 each with 0% discount.”
By doing this, we make the data semantically rich and accessible to the language model. Instead of dealing with abstract IDs and numeric values, the model now sees contextually meaningful information about who bought what, when, and under what conditions. These text fragments are the foundation for generating accurate embeddings and useful answers later on.
Then, the next part of the code in charge of performing this task, is as follows
# --- 3. Transform records into text ---
from collections import defaultdict
orders_data = defaultdict(list)
for row in records:
key = (row.OrderID, row.Customer, row.Salesperson, row.OrderDate)
orders_data[key].append((row.ProductName, row.Quantity, row.UnitPrice, row.Discount))
documents = []
for (order_id, customer, seller, date), items in orders_data.items():
lines = [f"Order {order_id} was placed by '{customer}' on {date:%Y-%m-%d}. Salesperson: {seller}."]
lines.append("Items included:")
for product, qty, price, discount in items:
lines.append(f" - {qty} x {product} at ${price:.2f} each with {discount*100:.0f}% discount.")
documents.append(" ".join(lines))Relational databases are optimized for storage and querying, not for natural language understanding. To bridge that gap, we need to convert structured rows into readable, descriptive sentences that capture the meaning behind the data.
In this step, we take the SQL query results and group them by order. Each order includes metadata (such as customer name, date, and salesperson) along with a list of purchased products. We format this information into short narratives that resemble human-written descriptions.
For example, an entry might read:
“Order 10250 was placed by ‘Ernst Handel’ on 1996-07-08. Salesperson: Nancy Davolio. Items included: 10 x Camembert Pierrot at $34.00 each with 0% discount.”
By doing this, we make the data semantically rich and accessible to the language model. Instead of dealing with abstract IDs and numeric values, the model now sees contextually meaningful information about who bought what, when, and under what conditions. These text fragments are the foundation for generating accurate embeddings and useful answers later on.
Step 4: Splitting text into chunks
Once we have our text-based descriptions, the next challenge is to prepare them for embedding. Language models (and vector databases) perform best when working with manageable segments of text rather than long, unstructured paragraphs.
To achieve this, we break each document into smaller chunks using a character-based splitter. In this case, we set a chunk size of 300 characters with an overlap of 50 characters. The overlap ensures that important information near the edges of a chunk isn’t lost when transitioning between segments.
For example, if an order includes many products or a particularly detailed description, it may span multiple chunks. These overlapping fragments preserve continuity and improve the accuracy of downstream retrieval.
# --- 4. Split texts into chunks --- splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=50) docs = splitter.create_documents(documents)
This process not only improves the quality of the embeddings but also enhances retrieval performance later on, when a user asks a question and the system needs to locate the most relevant context quickly.
By preparing clean, consistent input in this way, we’re setting the stage for a robust and semantically aware assistant that understands each order at a granular level.
Step 5: Creating embeddings with Azure OpenAI
With our text chunks ready, the next step is to convert them into numerical representations that capture their semantic meaning. These representations, known as embeddings, allow the system to measure how similar one piece of text is to another—not by exact words, but by meaning.
To generate these embeddings, we use the text-embedding-3-small model deployed on Azure OpenAI. This model transforms each chunk into a high-dimensional vector, where semantically similar chunks are positioned close together in vector space.
# --- 5. Create embeddings with Azure OpenAI ---
embeddings = AzureOpenAIEmbeddings(
deployment="text-embedding-3-small", # Deployment correcto para embeddings
model="text-embedding-3-small",
api_version="2024-02-01"
)For instance, two orders that include similar products or are placed by the same customer will produce embeddings that are close in distance. This similarity is what allows the assistant to later retrieve relevant information based on a natural language query, even if the wording is different.
Using Azure OpenAI for embeddings offers both scalability and enterprise-grade integration. It also ensures compatibility with the rest of our LangChain pipeline, as the embeddings can be seamlessly stored and queried within a vector database like Chroma.
This step essentially transforms our structured business data into a format that the language model can reason over—making it a critical part of the entire retrieval-augmented workflow.
Step 6: Storing embeddings in Chroma
Once the embeddings are generated, they need to be stored in a way that allows for fast and accurate retrieval. This is where Chroma comes in—a lightweight, high-performance vector database built specifically for handling semantic search.
Each text chunk, along with its corresponding embedding, is stored in Chroma using a local persistence directory. By doing so, we’re creating a searchable memory that allows the system to quickly find the most relevant fragments when a question is asked.
# --- 6. Store the embeddings in Chroma --- db = Chroma.from_documents(docs, embeddings, persist_directory="./northwind_db")
Chroma supports similarity search out of the box. When a user submits a query, the system converts that query into its own embedding and searches the database for nearby vectors (in other words, the most semantically related pieces of content).
This design mimics how our own memory works—we don’t recall entire databases, just the most relevant bits based on context and meaning. Storing the embeddings in Chroma gives our assistant the same ability.
By the end of this step, we’ve effectively turned structured business data into a knowledge base that can be queried using natural language, enabling more intelligent and human-like interactions.
Step 7: Configuring the question-answering engine with AzureChatOpenAI
At this stage, we have a searchable knowledge base ready to go. Now it’s time to build the brain of the assistant—the component that takes a user’s question, retrieves the relevant context, and generates a natural, intelligent response.
We use AzureChatOpenAI, a LangChain-compatible wrapper for Azure-hosted GPT models. In this example, we configure it to use the gpt-4.1-mini deployment. This model serves as the core reasoning engine, capable of understanding user queries and formulating answers based on the data retrieved from Chroma.
LangChain’s RetrievalQA chain orchestrates the interaction. When a question is submitted, the process works as follows:
The system converts the query into an embedding.
Chroma searches for the most relevant chunks.
The retrieved chunks are passed as context to the GPT model.
The model generates a concise and informative response.
# --- 7. Configure RetrievalQA with AzureChatOpenAI ---
retriever = db.as_retriever()
llm = AzureChatOpenAI(
deployment_name="gpt-4.1-mini", # Deployment LLM
model="gpt-4", # Model LLM
api_version="2024-02-01",
temperature=0
)
qa = RetrievalQA.from_chain_type(llm=llm, retriever=retriever)This architecture is what makes Retrieval-Augmented Generation (RAG) so effective. Rather than relying solely on the model’s training data, it supplements it with real, dynamic business information—allowing it to give accurate and up-to-date answers.
By combining a high-quality language model with focused contextual data, we give our assistant the tools to reason, explain, and even summarize complex order information without writing a single SQL query.
Step 8: Question loop
With everything in place, the final step is to set up a simple interaction loop that allows users to engage with the assistant through natural language. This loop waits for a user’s input, processes the question, retrieves the most relevant data from Chroma, and generates an answer using Azure OpenAI.
The experience is intuitive—users don’t need to know SQL or the structure of the database. Instead, they can simply ask questions like:
- Which employee achieved the highest total unit sales?
- Which discounted products were the most frequently sold?
- Which customer purchased the widest variety of products?
- Which order had the highest overall value?
- Who processed the most orders in July 1996?
Behind the scenes, the assistant interprets the question, finds the best-matching entries from the embedded knowledge base, and composes a response based on actual transactional data.
# --- 8. Question loop ---
print("Ask me about any order from the Northwind database.")
while True:
question = input("nYour question: ")
if question.lower() == "exit":
break
result = qa(question)
print("n Aswer:n", result["result"])
Aswer:n", result["result"]) Aswer:n", result["result"])
Aswer:n", result["result"])This approach makes data exploration conversational. It lowers the barrier for interacting with structured information, opening new possibilities for customer support, sales analysis, and executive reporting—all through plain language.
At the end of this loop, we’ve built something more than just a chatbot. It’s a practical proof of concept showing how large language models can bring structured data to life in real time, transforming static records into dynamic, human-centered knowledge.
Northwind Assistant in Action: Sample Questions and Answers
This section showcases the assistant in action. By combining data from the Northwind database with Azure OpenAI and Chroma, we’ve built a system that understands natural language and responds with precise, contextual answers. Instead of writing complex SQL queries, users can now explore business insights simply by asking questions. Below are some example queries and the kind of intelligent responses the assistant is capable of generating.

Figure 6: User prompt asking which discounted products were sold the most.

Figure 7: AI-generated answer showing the top-selling products with discounts applied.

Figure 8: Natural language question about which order had the highest total value.
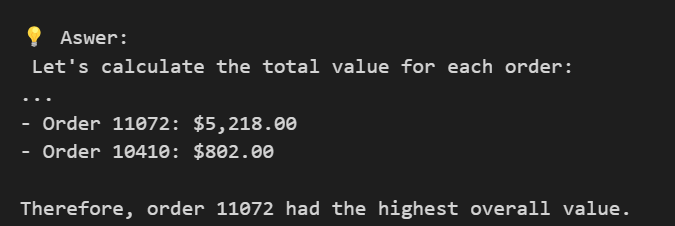
Figure 9: Response calculating and displaying the order with the highest overall value.
Conclusions
Combining SQL with LLMs unlocks new value from legacy data
By extracting and transforming structured information from a traditional database like Northwind, we demonstrated how even decades-old datasets can become fuel for modern AI-driven insights (without rewriting backend systems).
Semantic search enhances how we ask and answer questions
Using embeddings and a vector store (in this case, ChromaDB), the assistant is able to retrieve contextually relevant chunks of information instead of relying on rigid keyword matches. This allows for more flexible and intuitive interactions.
Natural language becomes the new interface for analytics
Thanks to Azure OpenAI’s chat capabilities, users no longer need to write complex SQL queries to understand data. Instead, they can simply ask questions in plain English (and get coherent answers backed by structured sources).
Modularity and scalability are built into the architecture
Each step of the assistant—data extraction, transformation, embedding, storage, and retrieval—is modular. This makes it easy to extend to new datasets, scale up in the cloud, or integrate into enterprise tools and workflows.
This approach bridges the gap between business users and data
Perhaps most importantly, this proof of concept shows that language models can act as intelligent intermediaries (allowing non-technical users to access meaningful insights from complex databases, instantly and conversationally).
References
Microsoft. (2024). What is Azure OpenAI Service? Microsoft Learn.
https://learn.microsoft.com/en-us/azure/ai-services/openai/overview
Chroma. (2024). ChromaDB: The AI-native open-source embedding database.
https://docs.trychroma.com/
OpenAI. (2024). Text embeddings documentation. OpenAI API Reference.
https://platform.openai.com/docs/guides/embeddings/what-are-embeddings
FutureSmart AI. (2024). ChromaDB: An open-source vector embedding database. FutureSmart AI Blog. https://blog.futuresmart.ai/chromadb-an-open-source-vector-embedding-database
FutureSmart AI. (2023). Master RAG with LangChain: A practical guide. FutureSmart AI Blog. https://blog.futuresmart.ai/master-rag-with-langchain-a-practical-guide
Jurafsky, D., & Martin, J. H. (2023). Speech and Language Processing (3rd ed., Draft). Stanford University. Retrieved from https://web.stanford.edu/~jurafsky/slp3/
Source: Read MoreÂ

