


In this post, we’ll dive into orchestrating data pipelines with the Databricks Jobs API, empowering you to automate, monitor, and scale workflows seamlessly within the Databricks platform.
Why Orchestrate with Databricks Jobs API?
When data pipelines become complex involving multiple steps—like running notebooks, updating Delta tables, or training machine learning models—you need a reliable way to automate and manage them with ease. The Databricks Jobs API offers a flexible and efficient way to automate your jobs/workflows directly within Databricks or from external systems (for example AWS Lambda or Azure Functions) using the API endpoints.
Unlike external orchestrators such as Apache Airflow, Dagster etc., which require separate infrastructure and integration, the Jobs API is built natively into the Databricks platform. And the best part? It doesn’t cost anything extra. The Databricks Jobs API allows you to fully manage the lifecycle of your jobs/workflows using simple HTTP requests.
Below is the list of API endpoints for the CRUD operations on the workflows:
- Create: Set up new jobs with defined tasks and configurations via the POST /api/2.1/jobs/create Define single or multi-task jobs, specifying the tasks to be executed (e.g., notebooks, JARs, Python scripts), their dependencies, and the compute resources.
- Retrieve: Access job details, check statuses, and review run logs using GET /api/2.1/jobs/get or GET /api/2.1/jobs/list.
- Update: Change job settings such as parameters, task sequences, or cluster details through POST /api/2.1/jobs/update and /api/2.1/jobs/reset.
- Delete: Remove jobs that are no longer required using POST /api/2.1/jobs/delete.
These full CRUD capabilities make the Jobs API a powerful tool to automate job management completely, from creation and monitoring to modification and deletion—eliminating the need for manual handling.
Key components of a Databricks Job
- Tasks: Individual units of work within a job, such as running a notebook, JAR, Python script, or dbt task. Jobs can have multiple tasks with defined dependencies and conditional execution.
- Dependencies: Relationships between tasks that determine the order of execution, allowing you to build complex workflows with sequential or parallel steps.
- Clusters: The compute resources on which tasks run. These can be ephemeral job clusters created specifically for the job or existing all-purpose clusters shared across jobs.
- Retries: Configuration to automatically retry failed tasks to improve job reliability.
- Scheduling: Options to run jobs on cron-based schedules, triggered events, or on demand.
- Notifications: Alerts for job start, success, or failure to keep teams informed.
Getting started with the Databricks Jobs API
Before leveraging the Databricks Jobs API for orchestration, ensure you have access to a Databricks workspace, a valid Personal Access Token (PAT), and sufficient privileges to manage compute resources and job configurations. This guide will walk through key CRUD operations and relevant Jobs API endpoints for robust workflow automation.
1. Creating a New Job/Workflow:
To create a job, you send a POST request to the /api/2.1/jobs/create endpoint with a JSON payload defining the job configuration.
{
"name": "Ingest-Sales-Data",
"tasks": [
{
"task_key": "Ingest-CSV-Data",
"notebook_task": {
"notebook_path": "/Users/name@email.com/ingest_csv_notebook",
"source": "WORKSPACE"
},
"new_cluster": {
"spark_version": "15.4.x-scala2.12",
"node_type_id": "i3.xlarge",
"num_workers": 2
}
}
],
"schedule": {
"quartz_cron_expression": "0 30 9 * * ?",
"timezone_id": "UTC",
"pause_status": "UNPAUSED"
},
"email_notifications": {
"on_failure": [
"name@email.com"
]
}
}
This JSON payload defines a Databricks job that executes a notebook-based task on a newly provisioned cluster, scheduled to run daily at 9:30 AM UTC. The components of the payload are explained below:
- name: The name of your job.
- tasks: An array of tasks to be executed. A job can have one or more tasks.
- task_key: A unique identifier for the task within the job. Used for defining dependencies.
- notebook_task: Specifies a notebook task. Other task types include spark_jar_task, spark_python_task, spark_submit_task, pipeline_task, etc.
- notebook_path: The path to the notebook in your Databricks workspace.
- source: The source of the notebook (e.g., WORKSPACE, GIT).
- new_cluster: Defines the configuration for a new cluster that will be created for this job run. You can also use existing_cluster_id to use an existing all-purpose cluster (though new job clusters are recommended).
- spark_version, node_type_id, num_workers: Standard cluster configuration options.
- schedule: Defines the job schedule using a cron expression and timezone.
- email_notifications: Configures email notifications for job events.
To create a Databricks workflow, the above JSON payload can be included in the body of a POST request sent to the Jobs API’s create endpoint—either using curl or programmatically via the Python requests library as shown below:
Using Curl:
curl -X POST https://<databricks-instance>.cloud.databricks.com/api/2.1/jobs/create -H "Authorization: Bearer <Your-PAT>" -H "Content-Type: application/json" -d '@workflow_config.json' #Place the above payload in workflow_config.json
Using Python requests library:
import requests
import json
create_response = requests.post("https://<databricks-instance>.cloud.databricks.com/api/2.1/jobs/create", data=json.dumps(your_json_payload), auth=("token", token))
if create_response.status_code == 200:
job_id = json.loads(create_response.content.decode('utf-8'))["job_id"]
print("Job created with id: {}".format(job_id))
else:
print("Job creation failed with status code: {}".format(create_response.status_code))
print(create_response.text)
The above example demonstrated a basic single-task workflow. However, the full potential of the Jobs API lies in orchestrating multi-task workflows with dependencies. The tasks array in the job payload allows you to configure multiple dependent tasks.
For example, the following workflow defines three tasks that execute sequentially: Ingest-CSV-Data → Transform-Sales-Data → Write-to-Delta.
{
"name": "Ingest-Sales-Data-Pipeline",
"tasks": [
{
"task_key": "Ingest-CSV-Data",
"notebook_task": {
"notebook_path": "/Users/name@email.com/ingest_csv_notebook",
"source": "WORKSPACE"
},
"new_cluster": {
"spark_version": "15.4.x-scala2.12",
"node_type_id": "i3.xlarge",
"num_workers": 2
}
},
{
"task_key": "Transform-Sales-Data",
"depends_on": [
{
"task_key": "Ingest-CSV-Data"
}
],
"notebook_task": {
"notebook_path": "/Users/name@email.com/transform_sales_data",
"source": "WORKSPACE"
},
"new_cluster": {
"spark_version": "15.4.x-scala2.12",
"node_type_id": "i3.xlarge",
"num_workers": 2
}
},
{
"task_key": "Write-to-Delta",
"depends_on": [
{
"task_key": "Transform-Sales-Data"
}
],
"notebook_task": {
"notebook_path": "/Users/name@email.com/write_to_delta_notebook",
"source": "WORKSPACE"
},
"new_cluster": {
"spark_version": "15.4.x-scala2.12",
"node_type_id": "i3.xlarge",
"num_workers": 2
}
}
],
"schedule": {
"quartz_cron_expression": "0 30 9 * * ?",
"timezone_id": "UTC",
"pause_status": "UNPAUSED"
},
"email_notifications": {
"on_failure": [
"name@email.com"
]
}
}
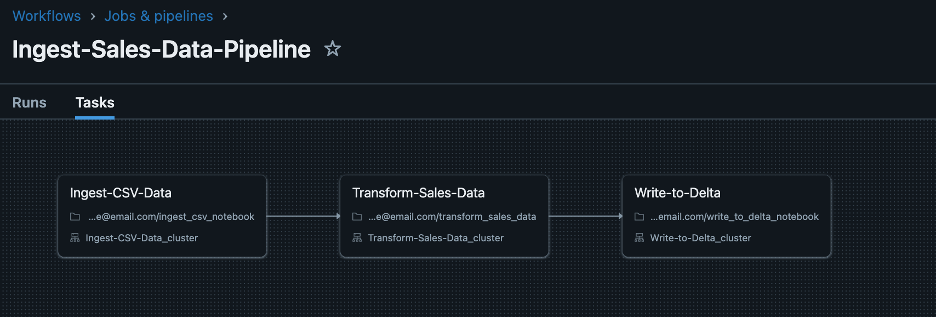
2. Updating Existing Workflows:
For modifying existing workflows, we have two endpoints: the update endpoint /api/2.1/jobs/update and the reset endpoint /api/2.1/jobs/reset. The update endpoint applies a partial update to your job. This means you can tweak parts of the job — like adding a new task or changing a cluster spec — without redefining the entire workflow. While the reset endpoint does a complete overwrite of the job configuration. Therefore, when resetting a job, you must provide the entire desired job configuration, including any settings you wish to keep unchanged, to avoid them being overwritten or removed entirely. Let us go over a few examples to better understand the endpoints better.
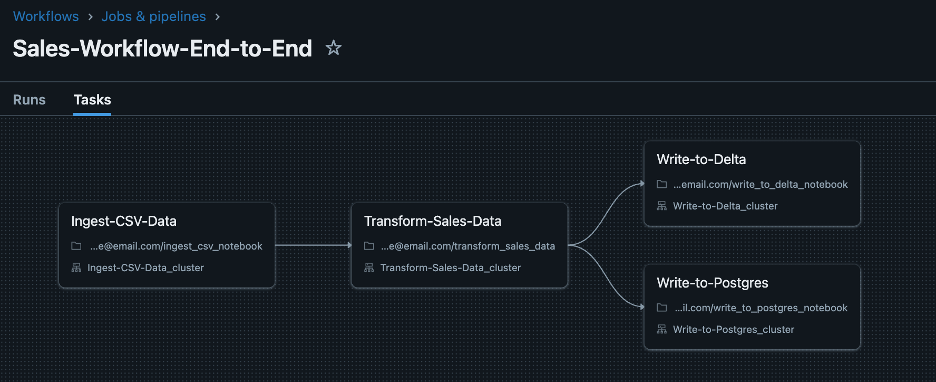
2.1. Update Workflow Name & Add New Task:
Let us modify the above workflow by renaming it from Ingest-Sales-Data-Pipeline to Sales-Workflow-End-to-End, adding an input parametersource_location to the Ingest-CSV-Data, and introducing a new task Write-to-Postgres, which runs after the successful completion of Transform-Sales-Data.
{
"job_id": 947766456503851,
"new_settings": {
"name": "Sales-Workflow-End-to-End",
"tasks": [
{
"task_key": "Ingest-CSV-Data",
"notebook_task": {
"notebook_path": "/Users/name@email.com/ingest_csv_notebook",
"base_parameters": {
"source_location": "s3://<bucket>/<key>"
},
"source": "WORKSPACE"
},
"new_cluster": {
"spark_version": "15.4.x-scala2.12",
"node_type_id": "i3.xlarge",
"num_workers": 2
}
},
{
"task_key": "Transform-Sales-Data",
"depends_on": [
{
"task_key": "Ingest-CSV-Data"
}
],
"notebook_task": {
"notebook_path": "/Users/name@email.com/transform_sales_data",
"source": "WORKSPACE"
},
"new_cluster": {
"spark_version": "15.4.x-scala2.12",
"node_type_id": "i3.xlarge",
"num_workers": 2
}
},
{
"task_key": "Write-to-Delta",
"depends_on": [
{
"task_key": "Transform-Sales-Data"
}
],
"notebook_task": {
"notebook_path": "/Users/name@email.com/write_to_delta_notebook",
"source": "WORKSPACE"
},
"new_cluster": {
"spark_version": "15.4.x-scala2.12",
"node_type_id": "i3.xlarge",
"num_workers": 2
}
},
{
"task_key": "Write-to-Postgres",
"depends_on": [
{
"task_key": "Transform-Sales-Data"
}
],
"notebook_task": {
"notebook_path":"/Users/name@email.com/write_to_postgres_notebook",
"source": "WORKSPACE"
},
"new_cluster": {
"spark_version": "15.4.x-scala2.12",
"node_type_id": "i3.xlarge",
"num_workers": 2
}
}
],
"schedule": {
"quartz_cron_expression": "0 30 9 * * ?",
"timezone_id": "UTC",
"pause_status": "UNPAUSED"
},
"email_notifications": {
"on_failure": [
"name@email.com"
]
}
}
}
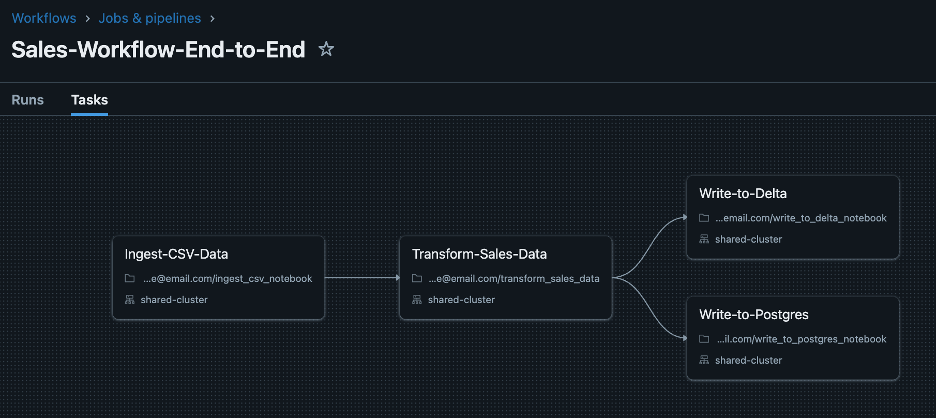
2.2. Update Cluster Configuration:
Cluster startup can take several minutes, especially for larger, more complex clusters. Sharing the same cluster allows subsequent tasks to start immediately after previous ones complete, speeding up the entire workflow. Parallel tasks can also run concurrently sharing the same cluster resources efficiently. Let’s update the above workflow to share the same cluster between all the tasks.
{
"job_id": 947766456503851,
"new_settings": {
"name": "Sales-Workflow-End-to-End",
"job_clusters": [
{
"job_cluster_key": "shared-cluster",
"new_cluster": {
"spark_version": "15.4.x-scala2.12",
"node_type_id": "i3.xlarge",
"num_workers": 2
}
}
],
"tasks": [
{
"task_key": "Ingest-CSV-Data",
"notebook_task": {
"notebook_path": "/Users/name@email.com/ingest_csv_notebook",
"base_parameters": {
"source_location": "s3://<bucket>/<key>"
},
"source": "WORKSPACE"
},
"job_cluster_key": "shared-cluster"
},
{
"task_key": "Transform-Sales-Data",
"depends_on": [
{
"task_key": "Ingest-CSV-Data"
}
],
"notebook_task": {
"notebook_path": "/Users/name@email.com/transform_sales_data",
"source": "WORKSPACE"
},
"job_cluster_key": "shared-cluster"
},
{
"task_key": "Write-to-Delta",
"depends_on": [
{
"task_key": "Transform-Sales-Data"
}
],
"notebook_task": {
"notebook_path": "/Users/name@email.com/write_to_delta_notebook",
"source": "WORKSPACE"
},
"job_cluster_key": "shared-cluster"
},
{
"task_key": "Write-to-Postgres",
"depends_on": [
{
"task_key": "Transform-Sales-Data"
}
],
"notebook_task": {
"notebook_path":"/Users/name@email.com/write_to_postgres_notebook",
"source": "WORKSPACE"
},
"job_cluster_key": "shared-cluster"
}
],
"schedule": {
"quartz_cron_expression": "0 30 9 * * ?",
"timezone_id": "UTC",
"pause_status": "UNPAUSED"
},
"email_notifications": {
"on_failure": [
"name@email.com"
]
}
}
}
2.3. Update Task Dependencies:
Let’s add a new task named Enrich-Sales-Data and update the dependency as shown below:
Ingest-CSV-Data →Enrich-Sales-Data → Transform-Sales-Data →[Write-to-Delta, Write-to-Postgres].Since we are updating dependencies of existing tasks, we need to use the reset endpoint /api/2.1/jobs/reset.
{
"job_id": 947766456503851,
"new_settings": {
"name": "Sales-Workflow-End-to-End",
"job_clusters": [
{
"job_cluster_key": "shared-cluster",
"new_cluster": {
"spark_version": "15.4.x-scala2.12",
"node_type_id": "i3.xlarge",
"num_workers": 2
}
}
],
"tasks": [
{
"task_key": "Ingest-CSV-Data",
"notebook_task": {
"notebook_path":"/Users/name@email.com/ingest_csv_notebook",
"base_parameters": {
"source_location": "s3://<bucket>/<key>"
},
"source": "WORKSPACE"
},
"job_cluster_key": "shared-cluster"
},
{
"task_key": "Enrich-Sales-Data",
"depends_on": [
{
"task_key": "Ingest-CSV-Data"
}
],
"notebook_task": {
"notebook_path":"/Users/name@email.com/enrich_sales_data",
"source": "WORKSPACE"
},
"job_cluster_key": "shared-cluster"
},
{
"task_key": "Transform-Sales-Data",
"depends_on": [
{
"task_key": "Enrich-Sales-Data"
}
],
"notebook_task": {
"notebook_path":"/Users/name@email.com/transform_sales_data",
"source": "WORKSPACE"
},
"job_cluster_key": "shared-cluster"
},
{
"task_key": "Write-to-Delta",
"depends_on": [
{
"task_key": "Transform-Sales-Data"
}
],
"notebook_task": {
"notebook_path":"/Users/name@email.com/write_to_delta_notebook",
"source": "WORKSPACE"
},
"job_cluster_key": "shared-cluster"
},
{
"task_key": "Write-to-Postgres",
"depends_on": [
{
"task_key": "Transform-Sales-Data"
}
],
"notebook_task": {
"notebook_path":"/Users/name@email.com/write_to_postgres_notebook",
"source": "WORKSPACE"
},
"job_cluster_key": "shared-cluster"
}
],
"schedule": {
"quartz_cron_expression": "0 30 9 * * ?",
"timezone_id": "UTC",
"pause_status": "UNPAUSED"
},
"email_notifications": {
"on_failure": [
"name@email.com"
]
}
}
}

The update endpoint is useful for minor modifications like updating the workflow name, updating the notebook path, input parameters to tasks, updating the job schedule, changing cluster configurations like node count etc., while the reset endpoint should be used for deleting existing tasks, redefining task dependencies, renaming tasks etc.
The update endpoint does not delete tasks or settings you omit i.e. tasks not mentioned in the request will remain unchanged, while the reset endpoint removes/deletes any fields or tasks not included in the request.
3. Trigger an Existing Job/Workflow:
Use the/api/2.1/jobs/run-now endpoint to trigger a job run on demand. Pass the input parameters to your notebook tasks using thenotebook_paramsfield.
curl -X POST https://<databricks-instance>/api/2.1/jobs/run-now
-H "Authorization: Bearer <DATABRICKS_TOKEN>"
-H "Content-Type: application/json"
-d '{
"job_id": 947766456503851,
"notebook_params": {
"source_location": "s3://<bucket>/<key>"
}
}'
4. Get Job Status:
To check the status of a specific job run, use the /api/2.1/jobs/runs/get endpoint with the run_id. The response includes details about the run, including its state (e.g., PENDING, RUNNING, COMPLETED, FAILED etc).
curl -X GET https://<databricks-instance>.cloud.databricks.com/api/2.1/jobs/runs/get?run_id=<your-run-id> -H "Authorization: Bearer <Your-PAT>"
5. Delete Job:
To remove an existing Databricks workflow, simply call the DELETE /api/2.1/jobs/delete endpoint using the Jobs API. This allows you to programmatically clean up outdated or unnecessary jobs as part of your pipeline management strategy.
curl -X POST https://<databricks-instance>/api/2.1/jobs/delete
-H "Authorization: Bearer <DATABRICKS_PERSONAL_ACCESS_TOKEN>"
-H "Content-Type: application/json"
-d '{ "job_id": 947766456503851 }'
Conclusion:
The Databricks Jobs API empowers data engineers to orchestrate complex workflows natively, without relying on external scheduling tools. Whether you’re automating notebook runs, chaining multi-step pipelines, or integrating with CI/CD systems, the API offers fine-grained control and flexibility. By mastering this API, you’re not just building workflows—you’re building scalable, production-grade data pipelines that are easier to manage, monitor, and evolve.
Source: Read MoreÂ