


by Luis Pacheco, Uday Yallapragada and Cristian Muñoz
Large language models (LLMs) like Meta’s LLaMA 70B are revolutionizing natural language processing tasks, but training or fine-tuning them requires massive computational and memory resources. To address these challenges, we employ distributed training across multiple GPU nodes using DeepSpeed and Hugging Face Accelerate.
This blog walks you through a production-ready setup for fine-tuning the LLaMA 70B model on two nodes, each equipped with H100 GPUs, using:
- DeepSpeed Stage 3 ZeRO optimization for memory-efficient training,
- Hugging Face Accelerate for seamless multi-node orchestration,
- 4-bit quantization to drastically reduce memory footprint,
- PEFT (Parameter-Efficient Fine-Tuning) via LoRA for lightweight adaptation.
Whether scaling your model or optimizing compute costs, this setup enables powerful fine-tuning workflows at scale.
Setup
The architecture involves a master node and a worker node, both running identical fine-tuning processes. Communication is managed via NCCL over TCP, and shared access to the dataset/model is through NFS.
Diagram Breakdown
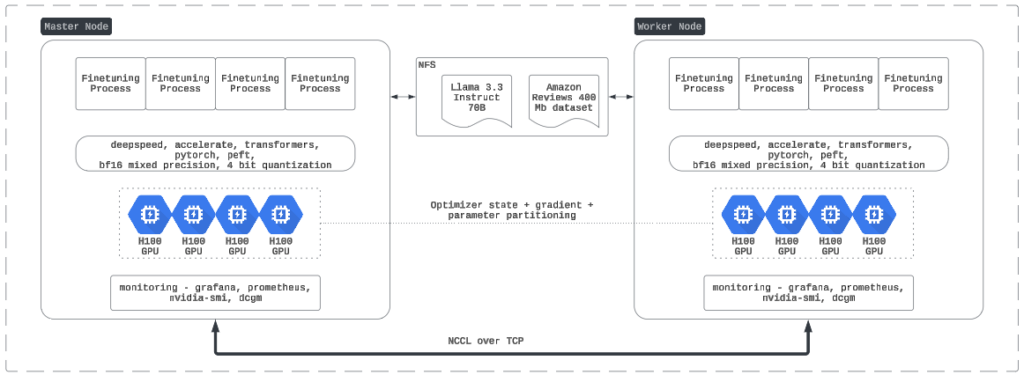
Key Components
-
DeepSpeed Stage 3 (ZeRO-3):
-
- Enables model sharding by partitioning optimizer states, gradients, and parameters across all GPUs.
-
- Critical for training models larger than what fits in the memory of a single GPU.
-
Hugging Face Accelerate:
-
- Provides a lightweight interface to manage distributed training, wrapping model, optimizer, data loaders, and more.
-
- Handles launching across nodes using accelerated launch with configuration files.
-
4-bit Quantization (via bitsandbytes):
-
- Reduces model size in memory, allowing larger models to fit and train faster.
-
- Uses nf4 quantization and bfloat16 (bf16) compute type to balance performance and accuracy.
-
LoRA (Low-Rank Adaptation) via PEFT:
-
- Finetune only a subset of low-rank adapter weights.
-
- Dramatically reduces the number of trainable parameters, making fine-tuning efficient even on smaller datasets.
-
Monitoring:
-
- Tools like Grafana, Prometheus, nvidia-smi, and DCGM track system and GPU performance.
-
Model/Data:
-
- LLaMA 3.3 70B model loaded via NFS.
-
- Amazon Reviews dataset (400 MB) used for binary sentiment classification.
Implementation Details
Accelerate Configurations
Two YAML files define the multi-node setup:
default_config_main.yaml
machine_rank: 0 num_machines: 2 distributed_type: DEEPSPEED mixed_precision: fp8 deepspeed_config: zero_stage: 3
default_config_worker.yaml
machine_rank: 1 main_process_ip: <your ip address>
These configs enable synchronized training across two nodes, each running 4 processes (1 per GPU).
Python Script Highlights
The fine-tuning script llm_finetune_for_blog.py is modular and production-friendly. Here’s a breakdown of its workflow:
Data Loading & Preprocessing
df = pd.concat([...]) df["label"] = df["rating"].apply(convert_rating) train_dataset = datasets.Dataset.from_pandas(train_df)
- Loads and preprocesses Amazon reviews CSV files.
- Converts ratings to binary labels.
- Tokenizes using Hugging Face tokenizer with padding and truncation.
Model & Quantization Setup
bnb_config = BitsAndBytesConfig(load_in_4bit=True, ...) model = AutoModelForSequenceClassification.from_pretrained(..., quantization_config=bnb_config)
- Loads LLaMA model in 4-bit with nf4 quantization.
- Applies gradient checkpointing and enables input gradients.
Apply LoRA
lora_config = LoraConfig(...) model = get_peft_model(model, lora_config)
- LoRA reduces the number of trainable parameters, speeding up training while maintaining performance.
Accelerator Setup
accelerator = Accelerator(mixed_precision='fp8') model, optimizer, train_dataloader, ... = accelerator.prepare(...)
- Wraps training components with Accelerate to handle distributed training.
Training Loop
for epoch in range(num_epochs): for batch in train_dataloader: outputs = model(**batch) loss = outputs.loss accelerator.backward(loss)
- Simple loop structure with loss backpropagation using Accelerate.
- The optimizer and scheduler steps are executed per batch.
Evaluation
with torch.no_grad(): outputs = model(**batch) total_eval_loss += outputs.loss.item()
- Computes average validation loss at the end of training.
Conclusion
In this blog, we’ve walked through a complete end-to-end setup to fine-tune LLaMA 70B using:
- Distributed multi-node training with DeepSpeed ZeRO-3,
- 4-bit quantization with bitsandbytes to optimize memory usage,
- Hugging Face Accelerate for seamless training orchestration,
- PEFT via LoRA to fine-tune only critical parts of the model efficiently.
This architecture is robust and scalable, suitable for large-scale enterprise LLM fine-tuning tasks. By combining quantization, PEFT, and distributed computing, you can unlock high-performance fine-tuning workflows on trillion-parameter-scale models — all while optimizing for computing cost and speed.
Source: Read MoreÂ
