
Google Research has unveiled a groundbreaking method for fine-tuning large language models (LLMs) that slashes the amount of required training data by up to 10,000x, while maintaining or even improving model quality. This approach centers on active learning and focusing expert labeling efforts on the most informative examples—the “boundary cases” where model uncertainty peaks.
The Traditional Bottleneck
Fine-tuning LLMs for tasks demanding deep contextual and cultural understanding—like ad content safety or moderation—has typically required massive, high-quality labeled datasets. Most data is benign, meaning that for policy violation detection, only a small fraction of examples matter, driving up the cost and complexity of data curation. Standard methods also struggle to keep up when policies or problematic patterns shift, necessitating expensive retraining.
Google’s Active Learning Breakthrough
How It Works:
- LLM-as-Scout: The LLM is used to scan a vast corpus (hundreds of billions of examples) and identify cases it’s least certain about.
- Targeted Expert Labeling: Instead of labeling thousands of random examples, human experts only annotate those borderline, confusing items.
- Iterative Curation: This process repeats, with each batch of new “problematic” examples informed by the latest model’s confusion points.
- Rapid Convergence: Models are fine-tuned in multiple rounds, and the iteration continues until the model’s output aligns closely with expert judgment—measured by Cohen’s Kappa, which compares agreement between annotators beyond chance.
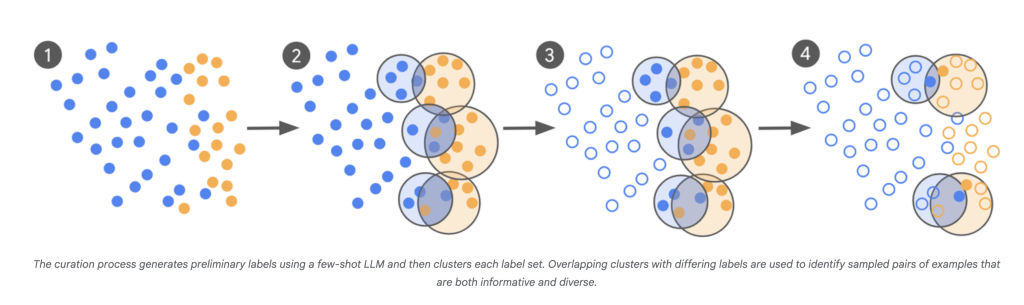
Impact:
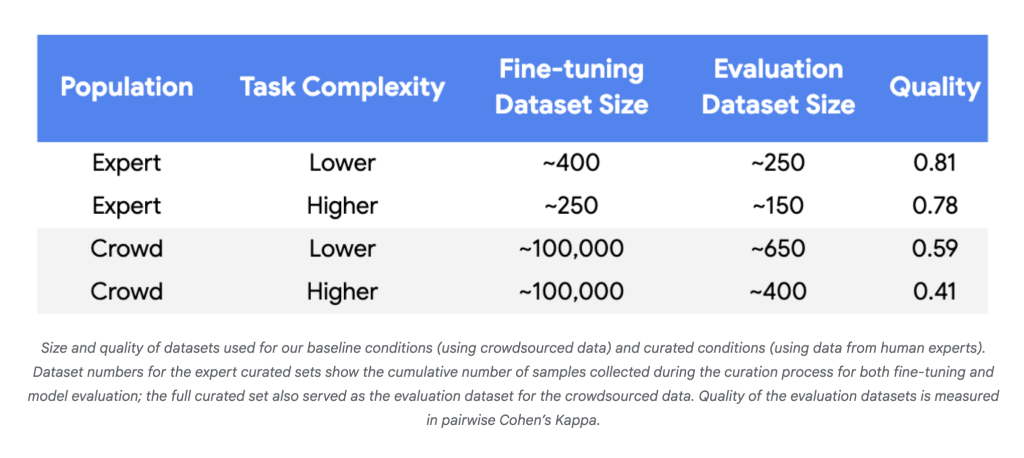
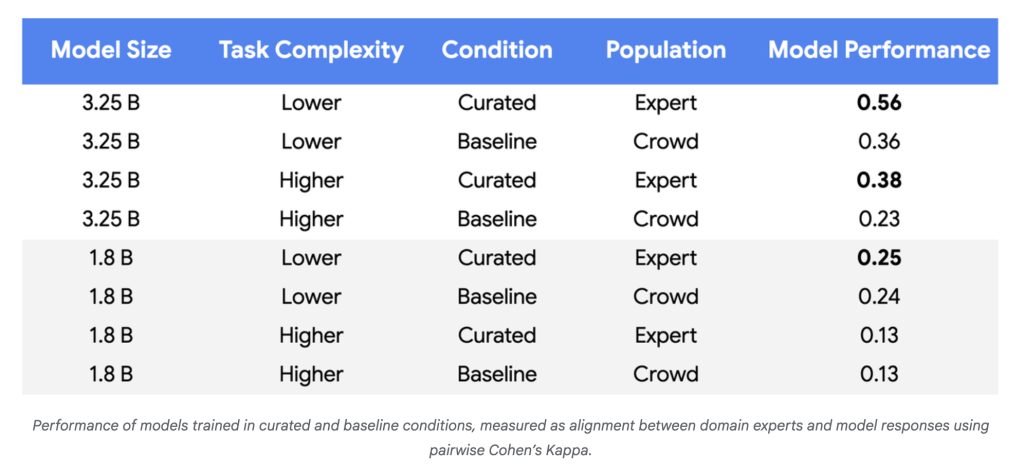
- Data Needs Plummet: In experiments with Gemini Nano-1 and Nano-2 models, alignment with human experts reached parity or better using 250–450 well-chosen examples rather than ~100,000 random crowdsourced labels—a reduction of three to four orders of magnitude.
- Model Quality Rises: For more complex tasks and larger models, performance improvements reached 55–65% over baseline, demonstrating more reliable alignment with policy experts.
- Label Efficiency: For reliable gains using tiny datasets, high label quality was consistently necessary (Cohen’s Kappa > 0.8).
Why It Matters
This approach flips the traditional paradigm. Rather than drowning models in vast pools of noisy, redundant data, it leverages both LLMs’ ability to identify ambiguous cases and the domain expertise of human annotators where their input is most valuable. The benefits are profound:
- Cost Reduction: Vastly fewer examples to label, dramatically lowering labor and capital expenditure.
- Faster Updates: The ability to retrain models on a handful of examples makes adaptation to new abuse patterns, policy changes, or domain shifts rapid and feasible.
- Societal Impact: Enhanced capacity for contextual and cultural understanding increases the safety and reliability of automated systems handling sensitive content.
In Summary
Google’s new methodology enables LLM fine-tuning on complex, evolving tasks with just hundreds (not hundreds of thousands) of targeted, high-fidelity labels—ushering in far leaner, more agile, and cost-effective model development.
Check out the technical article from Google blog. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
 Star us on GitHub
Star us on GitHub Join our ML Subreddit
Join our ML Subreddit  Sponsor us
Sponsor us The post From 100,000 to Under 500 Labels: How Google AI Cuts LLM Training Data by Orders of Magnitude appeared first on MarkTechPost.
Source: Read MoreÂ

