
Introduction
Large Language Models (LLMs) have set new benchmarks in natural language processing, but their tendency for hallucination—generating inaccurate outputs—remains a critical issue for knowledge-intensive applications. Retrieval-Augmented Generation (RAG) frameworks attempt to solve this by incorporating external knowledge into language generation. However, traditional RAG approaches rely on chunk-based retrieval, which limits their ability to represent complex semantic relationships. Entity-relation graph-based RAG methods (GraphRAG) address some structural limitations, but still face high construction cost, one-shot retrieval inflexibility, and dependence on long-context reasoning and carefully crafted prompts.
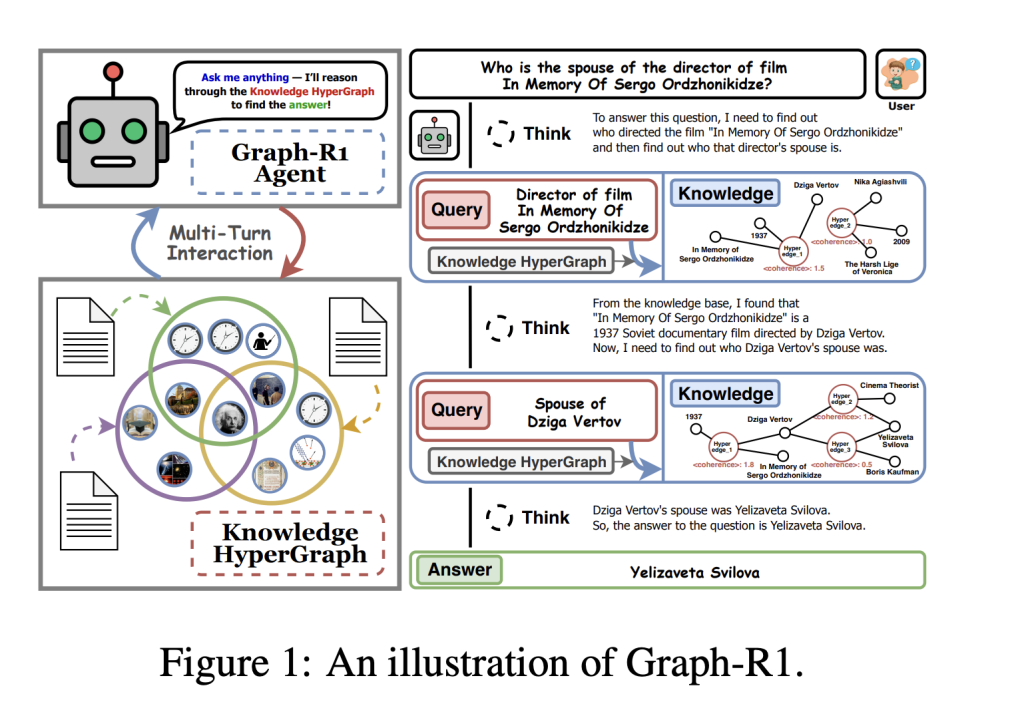
Researchers from Nanyang Technological University, National University of Singapore, Beijing Institute of Computer Technology and Application, and Beijing Anzhen Hospital have introduced Graph-R1, an agentic GraphRAG framework powered by end-to-end reinforcement learning.
Core Innovations of Graph-R1
1. Lightweight Knowledge Hypergraph Construction
Graph-R1 constructs knowledge as a hypergraph, where each knowledge segment is extracted using LLM-driven n-ary relation extraction. This approach encodes richer and more semantically grounded relationships, boosting agentic reasoning capabilities while maintaining manageable cost and computational requirements.
- Efficiency: Only 5.69s and $2.81 per 1,000 tokens for construction (vs. $3.35 for GraphRAG and $4.14 for HyperGraphRAG), while generating semantically rich graphs with 120,499 nodes and 98,073 edges.
2. Multi-Turn Agentic Retrieval Process
Graph-R1 models retrieval as a multi-turn interaction loop (“think-retrieve-rethink-generate”), allowing the agent to adaptively query and refine its knowledge path, unlike previous methods that use one-shot retrieval.
- Dynamic Reasoning: The agent decides at each step whether to continue exploring or terminate with an answer. Entity-based and direct hyperedge retrieval are fused through reciprocal rank aggregation, improving the chances of retrieving the most relevant knowledge.
3. End-to-End Reinforcement Learning Optimization
Graph-R1 uses Group Relative Policy Optimization (GRPO) for end-to-end RL, integrating rewards for format adherence, relevance, and answer correctness. This unified reward guides agents to develop generalizable reasoning strategies tightly aligned with both the knowledge structure and output quality.
- Outcome-directed reward mechanism: Combines format rewards (structural coherence) and answer rewards (semantic accuracy) for effective optimization, only rewarding answers embedded in structurally valid reasoning trajectories.
Key Findings
Benchmarking on RAG QA Tasks
Graph-R1 was evaluated across six standard QA datasets (2WikiMultiHopQA, HotpotQA, Musique, Natural Questions, PopQA, TriviaQA).
| Method | Avg. F1 (Qwen2.5-7B) |
|---|---|
| NaiveGeneration | 13.87 |
| StandardRAG | 15.89 |
| GraphRAG | 24.87 |
| HyperGraphRAG | 29.40 |
| Search-R1 | 46.19 |
| R1-Searcher | 42.29 |
| Graph-R1 | 57.82 |
- Graph-R1 achieves up to 57.82 average F1 with Qwen2.5-7B, surpassing all previous baselines by a wide margin. Larger base models amplify its performance gains.
Ablation Analysis
Component ablation demonstrates that removing hypergraph construction, multi-turn reasoning, or RL optimization dramatically reduces performance, validating the necessity of each module within Graph-R1.
Retrieval and Efficiency
- Graph-R1 retrieval is more concise and effective. It achieves high F1 scores with moderate average content lengths (~1200-1500 tokens per exchange), and supports more interaction turns (average 2.3-2.5), facilitating stable and accurate knowledge extraction.2507.21892v1.pdf
- Generation cost is minimal: Despite richer representation, Graph-R1’s response time per query (7.0s) and per-query cost ($0) outperforms graph-based competitors like HyperGraphRAG (9.6s, $8.76).2507.21892v1.pdf
Generation Quality
Graph-R1’s generation quality is evaluated across seven dimensions—comprehensiveness, knowledgeability, correctness, relevance, diversity, logical coherence, factuality—and consistently outperforms all RL-based and graph-based baselines, achieving top scores in correctness (86.9), relevance (95.2), and coherence (88.5).
Generalizability
Cross-validation on out-of-distribution (O.O.D.) settings reveals that Graph-R1 maintains robust performance across datasets, with O.O.D./I.I.D. ratios often above 85%, demonstrating strong domain generalization properties.
Theoretical Guarantees
Graph-R1 is supported by information-theoretic analyses:
- Graph-structured knowledge provides higher information density per retrieval and faster convergence to correct answers compared to chunk-based retrieval.
- Multi-turn interaction enables the agent to achieve higher retrieval efficiency by dynamically focusing on high-impact graph regions.
- End-to-end RL optimization bridges graph-structured evidence and language generation, reducing output entropy and error rates.
Algorithmic Workflow (High-Level)
- Knowledge Hypergraph Extraction: LLM extracts n-ary relations to build entity and hyperedge sets.
- Multi-turn Agentic Reasoning: The agent alternates between reflective thinking, querying, hypergraph retrieval (entity and hyperedge dual paths), and synthesis.
- GRPO Optimization: RL policy is updated using sampled trajectories and reward normalization, enforcing structure and answer correctness.
Conclusion
Graph-R1 demonstrates that integrating hypergraph-based knowledge representation, agentic multi-turn reasoning, and end-to-end RL delivers unprecedented gains in factual QA performance, retrieval efficiency, and generation quality, charting the path for next-generation agentic and knowledge-driven LLM systems.
FAQ 1: What is the key innovation of Graph-R1 compared to earlier GraphRAG and RAG systems?
Graph-R1 introduces an agentic framework where retrieval is modeled as a multi-turn interaction rather than a single one-shot process. Its main innovations are:
- Hypergraph Knowledge Representation: Instead of simple entity-relation graphs or text chunks, Graph-R1 constructs a semantic hypergraph that enables more expressive, n-ary relationships between entities.
- Multi-Turn Reasoning Loop: The agent operates in repeated cycles of “think–retrieve–rethink–generate” over the hypergraph, dynamically focusing queries rather than retrieving everything at once.
- End-to-End Reinforcement Learning (RL): The agent is trained with a reward function that simultaneously optimizes for step-wise logical reasoning and final answer correctness, enabling tighter alignment between structured knowledge and natural language answers.
FAQ 2: How does Graph-R1’s retrieval and generation efficiency compare to previous methods?
Graph-R1 is significantly more efficient and effective in both retrieval and answer generation:
- Lower Construction & Retrieval Cost: For building the knowledge hypergraph, Graph-R1 takes only 5.69 seconds and costs $2.81 per 1,000 tokens (on the 2Wiki dataset), outperforming similar graph-based methods.
- Faster and Cheaper Generation: Query response times (average 7 seconds per query) and generation costs ($0 per query) are better than prior graph-RAG systems, such as HyperGraphRAG.
- Conciseness & Robustness: Graph-R1 answers are both more concise (usually 1,200–1,500 tokens) and more accurate due to the multi-turn interaction, with state-of-the-art F1 scores across six QA datasets.
FAQ 3: In which scenarios or domains is the Graph-R1 framework most applicable?
Graph-R1 is ideal for complex knowledge-intensive applications demanding both factual accuracy and reasoning transparency, such as:
- Healthcare and Medical AI: Where multi-hop reasoning, traceability, and reliability are essential.
- Legal and Regulatory Domains: That require precise grounded answers and interpretable multi-step reasoning.
- Enterprise Knowledge Automation: For tasks needing scalable, dynamic querying and retrieval across large document or data corpora.
The model’s architecture also allows for easy adaptation to other fields that benefit from agentic, multi-turn knowledge search anchored in structured representations.
Check out the Paper here and GitHub Page. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks.
 Discuss on Hacker News
Discuss on Hacker News  Join our ML Subreddit
Join our ML Subreddit  Sponsor us
Sponsor us The post Graph-R1: An Agentic GraphRAG Framework for Structured, Multi-Turn Reasoning with Reinforcement Learning appeared first on MarkTechPost.
Source: Read MoreÂ

