
Organizations across various sectors face significant challenges when converting meeting recordings or recorded presentations into structured documentation. The process of creating handouts from presentations requires lots of manual effort, such as reviewing recordings to identify slide transitions, transcribing spoken content, capturing and organizing screenshots, synchronizing visual elements with speaker notes, and formatting content. These challenges impact productivity and scalability, especially when dealing with multiple presentation recordings, conference sessions, training materials, and educational content.
In this post, we show how you can build an automated, serverless solution to transform webinar recordings into comprehensive handouts using Amazon Bedrock Data Automation for video analysis. We walk you through the implementation of Amazon Bedrock Data Automation to transcribe and detect slide changes, as well as the use of Amazon Bedrock foundation models (FMs) for transcription refinement, combined with custom AWS Lambda functions orchestrated by AWS Step Functions. Through detailed implementation details, architectural patterns, and code, you will learn how to build a workflow that automates the handout creation process.
Amazon Bedrock Data Automation
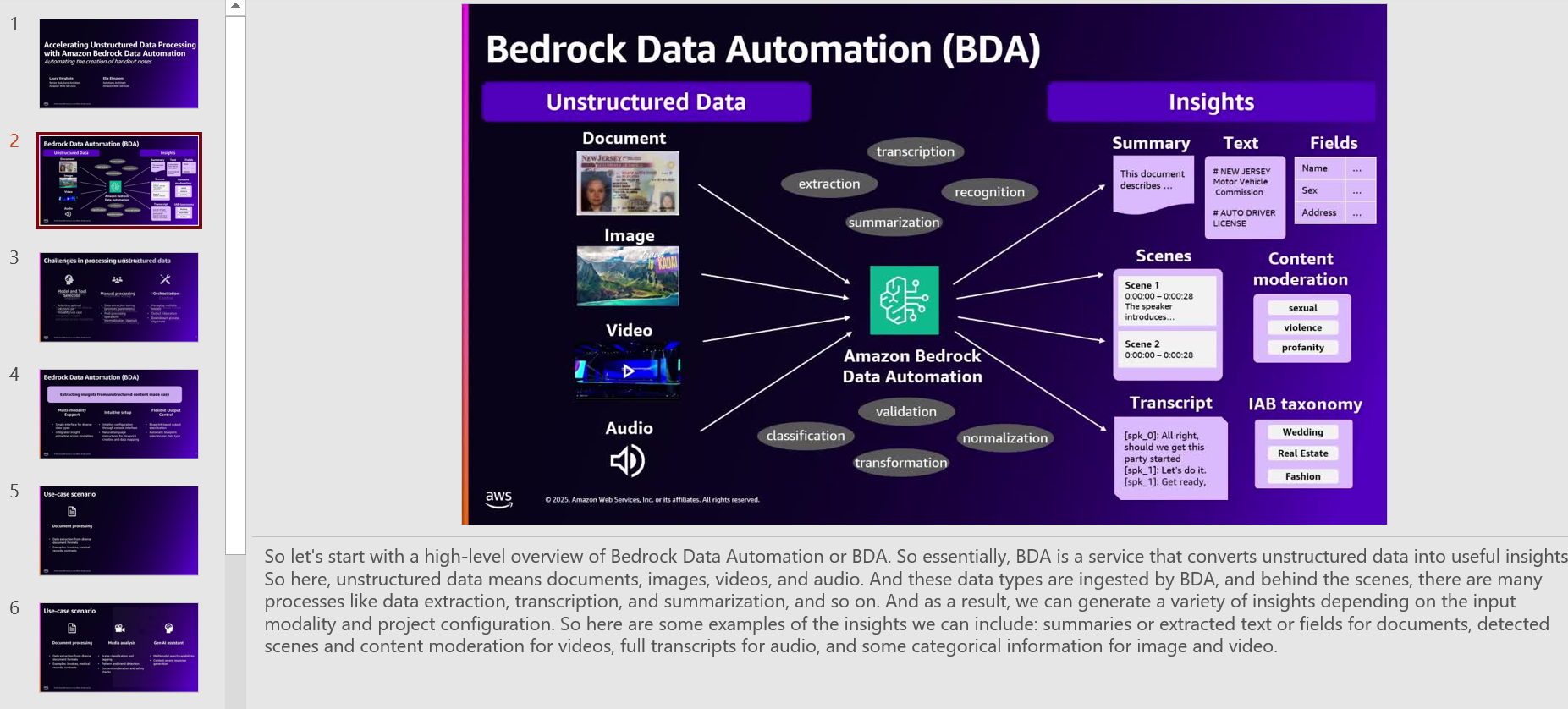
Amazon Bedrock Data Automation uses generative AI to automate the transformation of multimodal data (such as images, videos and more) into a customizable structured format. Examples of structured formats include summaries of scenes in a video, unsafe or explicit content in text and images, or organized content based on advertisements or brands. The solution presented in this post uses Amazon Bedrock Data Automation to extract audio segments and different shots in videos.
Solution overview
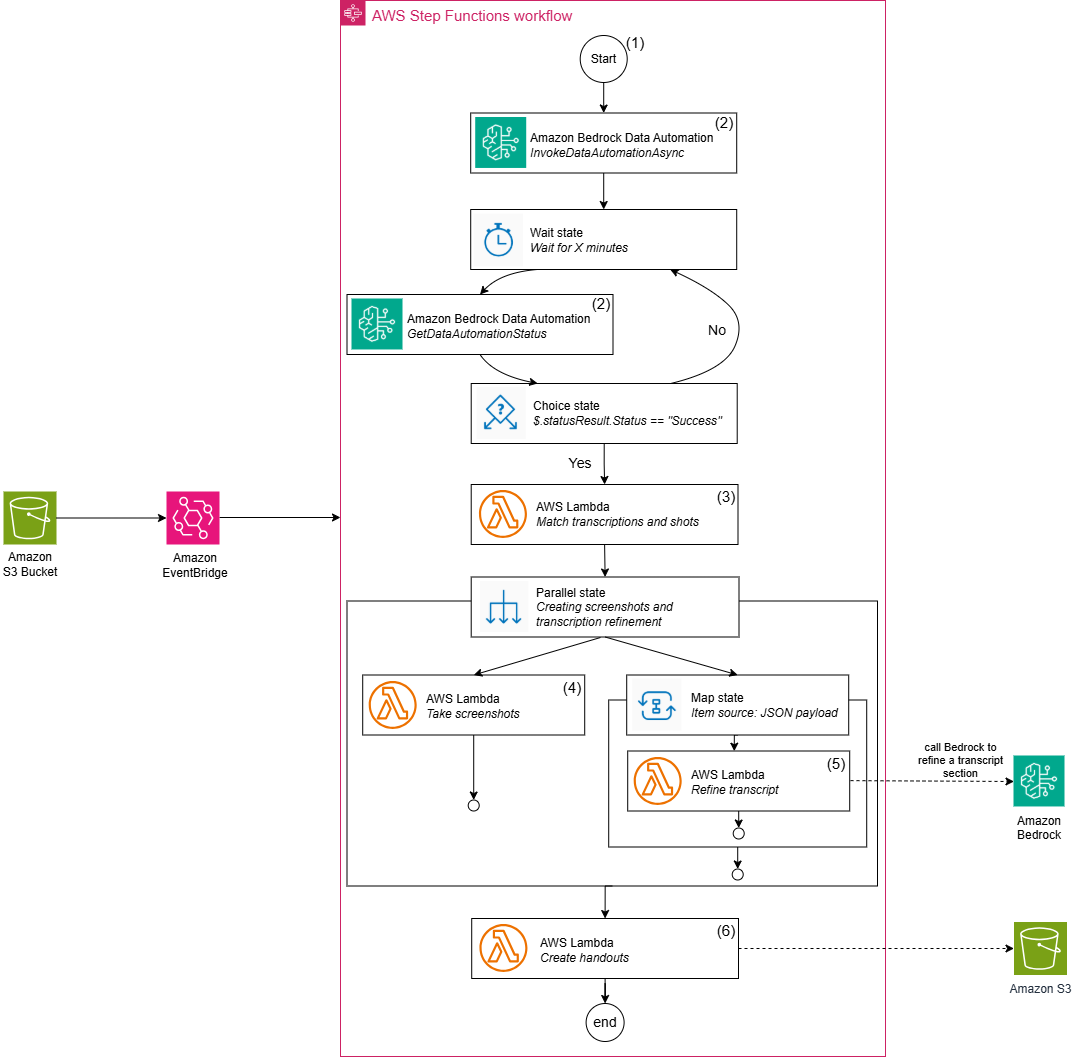
Our solution uses a serverless architecture orchestrated by Step Functions to process presentation recordings into comprehensive handouts. The workflow consists of the following steps:
- The workflow begins when a video is uploaded to Amazon Simple Storage Service (Amazon S3), which triggers an event notification through Amazon EventBridge rules that initiates our video processing workflow in Step Functions.
- After the workflow is triggered, Amazon Bedrock Data Automation initiates a video transformation job to identify different shots in the video. In our case, this is represented by a change of slides. The workflow moves into a waiting state, and checks for the transformation job progress. If the job is in progress, the workflow returns to the waiting state. When the job is complete, the workflow continues, and we now have extracted both visual shots and spoken content.
- These visual shots and spoken content feed into a synchronization step. In this Lambda function, we use the output of the Amazon Bedrock Data Automation job to match the spoken content to the correlating shots based on the matching of timestamps.
- After function has matched the spoken content to the visual shots, the workflow moves into a parallel state. One of the steps of this state is the generation of screenshots. We use a FFmpeg-enabled Lambda function to create images for each identified video shot.
- The other step of the parallel state is the refinement of our transformations. Amazon Bedrock processes and improves each raw transcription section through a Map state. This helps us remove speech disfluencies and improve the sentence structure.
- Lastly, after the screenshots and refined transcript are created, the workflow uses a Lambda function to create handouts. We use the Python-PPTX library, which generates the final presentation with synchronized content. These final handouts are stored in Amazon S3 for distribution.
The following diagram illustrates this workflow.
If you want to try out this solution, we have created an AWS Cloud Development Kit (AWS CDK) stack available in the accompanying GitHub repo that you can deploy in your account. It deploys the Step Functions state machine to orchestrate the creation of handout notes from the presentation video recording. It also provides you with a sample video to test out the results.
To deploy and test the solution in your own account, follow the instructions in the GitHub repository’s README file. The following sections describe in more detail the technical implementation details of this solution.
Video upload and initial processing
The workflow begins with Amazon S3, which serves as the entry point for our video processing pipeline. When a video is uploaded to a dedicated S3 bucket, it triggers an event notification that, through EventBridge rules, initiates our Step Functions workflow.
Shot detection and transcription using Amazon Bedrock Data Automation
This step uses Amazon Bedrock Data Automation to detect slide transitions and create video transcriptions. To integrate this as part of the workflow, you must create an Amazon Bedrock Data Automation project. A project is a grouping of output configurations. Each project can contain standard output configurations as well as custom output blueprints for documents, images, video, and audio. The project has already been created as part of the AWS CDK stack. After you set up your project, you can process content using the InvokeDataAutomationAsync API. In our solution, we use the Step Functions service integration to execute this API call and start the asynchronous processing job. A job ID is returned for tracking the process.
The workflow must now check the status of the processing job before continuing with the handout creation process. This is done by polling Amazon Bedrock Data Automation for the job status using the GetDataAutomationStatus API on a regular basis. Using a combination of the Step Functions Wait and Choice states, we can ask the workflow to poll the API on a fixed interval. This not only gives you the ability to customize the interval depending on your needs, but it also helps you control the workflow costs, because every state transition is billed in Standard workflows, which this solution uses.
When the GetDataAutomationStatus API output shows as SUCCESS, the loop exits and the workflow continues to the next step, which will match transcripts to the visual shots.
Matching audio segments with corresponding shots
To create comprehensive handouts, you must establish a mapping between the visual shots and their corresponding audio segments. This mapping is crucial to make sure the final handouts accurately represent both the visual content and the spoken narrative of the presentation.
A shot represents a series of interrelated consecutive frames captured during the presentation, typically indicating a distinct visual state. In our presentation context, a shot corresponds to either a new slide or a significant slide animation that adds or modifies content.
An audio segment is a specific portion of an audio recording that contains uninterrupted spoken language, with minimal pauses or breaks. This segment captures a natural flow of speech. The Amazon Bedrock Data Automation output provides an audio_segments array, with each segment containing precise timing information such as the start and end time of each segment. This allows for accurate synchronization with the visual shots.
The synchronization between shots and audio segments is critical for creating accurate handouts that preserve the presentation’s narrative flow. To achieve this, we implement a Lambda function that manages the matching process in three steps:
- The function retrieves the processing results from Amazon S3, which contains both the visual shots and audio segments.
- It creates structured JSON arrays from these components, preparing them for the matching algorithm.
- It executes a matching algorithm that analyzes the different timestamps of the audio segments and the shots, and matches them based on these timestamps. This algorithm also considers timestamp overlaps between shots and audio segments.
For each shot, the function examines audio segments and identifies those whose timestamps overlap with the shot’s duration, making sure the relevant spoken content is associated with its corresponding slide in the final handouts. The function returns the matched results directly to the Step Functions workflow, where it will serve as input for the next step, where Amazon Bedrock will refine the transcribed content and where we will create screenshots in parallel.
Screenshot generation
After you get the timestamps of each shot and associated audio segment, you can capture the slides of the presentation to create comprehensive handouts. Each detected shot from Amazon Bedrock Data Automation represents a distinct visual state in the presentation—typically a new slide or significant content change. By generating screenshots at these precise moments, we make sure our handouts accurately represent the visual flow of the original presentation.
This is done with a Lambda function using the ffmpeg-python library. This library acts as a Python binding for the FFmpeg media framework, so you can run FFmpeg terminal commands using Python methods. In our case, we can extract frames from the video at specific timestamps identified by Amazon Bedrock Data Automation. The screenshots are stored in an S3 bucket to be used in creating the handouts, as described in the following code. To use ffmpeg-python in Lambda, we created a Lambda ZIP deployment containing the required dependencies to run the code. Instructions on how to create the ZIP file can be found in our GitHub repository.
The following code shows how a screenshot is taken using ffmpeg-python. You can view the full Lambda code on GitHub.
Transcript refinement with Amazon Bedrock
In parallel with the screenshot generation, we refine the transcript using a large language model (LLM). We do this to improve the quality of the transcript and filter out errors and speech disfluencies. This process uses an Amazon Bedrock model to enhance the quality of the matched transcription segments while maintaining content accuracy. We use a Lambda function that integrates with Amazon Bedrock through the Python Boto3 client, using a prompt to guide the model’s refinement process. The function can then process each transcript segment, instructing the model to do the following:
- Fix typos and grammatical errors
- Remove speech disfluencies (such as “uh” and “um”)
- Maintain the original meaning and technical accuracy
- Preserve the context of the presentation
In our solution, we used the following prompt with three example inputs and outputs:
The following is an example input and output:
To optimize processing speed while adhering to the maximum token limits of the Amazon Bedrock InvokeModel API, we use the Step Functions Map state. This enables parallel processing of multiple transcriptions, each corresponding to a separate video segment. Because these transcriptions must be handled individually, the Map state efficiently distributes the workload. Additionally, it reduces operational overhead by managing integration—taking an array as input, passing each element to the Lambda function, and automatically reconstructing the array upon completion.The Map state returns the refined transcript directly to the Step Functions workflow, maintaining the structure of the matched segments while providing cleaner, more professional text content for the final handout generation.
Handout generation
The final step in our workflow involves creating the handouts using the python-pptx library. This step combines the refined transcripts with the generated screenshots to create a comprehensive presentation document.
The Lambda function processes the matched segments sequentially, creating a new slide for each screenshot while adding the corresponding refined transcript as speaker notes. The implementation uses a custom Lambda layer containing the python-pptx package. To enable this functionality in Lambda, we created a custom layer using Docker. By using Docker to create our layer, we make sure the dependencies are compiled in an environment that matches the Lambda runtime. You can find the instructions to create this layer and the layer itself in our GitHub repository.
The Lambda function implementation uses python-pptx to create structured presentations:


Source: Read MoreÂ

