
Recent advances in generative models, especially diffusion models and rectified flows, have revolutionized visual content creation with enhanced output quality and versatility. Human feedback integration during training is essential for aligning outputs with human preferences and aesthetic standards. Current approaches like ReFL methods depend on differentiable reward models that introduce VRAM inefficiency for video generation. DPO variants achieve only marginal visual improvements. Further, RL-based methods face challenges including conflicts between ODE-based sampling of rectified flow models and Markov Decision Process formulations, instability when scaling beyond small datasets, and a lack of validation for video generation tasks.
Aligning LLMs employs Reinforcement Learning from Human Feedback (RLHF), which trains reward functions based on comparison data to capture human preferences. Policy gradient methods have proven effective but are computationally intensive and require extensive tuning, while Direct Policy Optimization (DPO) offers cost efficiency but delivers inferior performance. DeepSeek-R1 recently showed that large-scale RL with specialized reward functions can guide LLMs toward self-emergent thought processes. Current approaches include DPO-style methods, direct backpropagation with reward signals like ReFL, and policy gradient-based methods such as DPOK and DDPO. Production models primarily utilize DPO and ReFL due to the instability of policy gradient methods in large-scale applications.
Researchers from ByteDance Seed and the University of Hong Kong have proposed DanceGRPO, a unified framework adapting Group Relative Policy Optimization to visual generation paradigms. This solution operates seamlessly across diffusion models and rectified flows, handling text-to-image, text-to-video, and image-to-video tasks. The framework integrates with four foundation models (Stable Diffusion, HunyuanVideo, FLUX, SkyReels-I2V) and five reward models covering image/video aesthetics, text-image alignment, video motion quality, and binary reward assessments. DanceGRPO outperforms baselines by up to 181% on key benchmarks, including HPS-v2.1, CLIP Score, VideoAlign, and GenEval.
The architecture utilizes five specialized reward models to optimize visual generation quality:
- Image Aesthetics quantifies visual appeal using models fine-tuned on human-rated data.
- Text-image Alignment uses CLIP to maximize cross-modal consistency.
- Video Aesthetics Quality extends evaluation to temporal domains using Vision Language Models (VLMs).
- Video Motion Quality evaluates motion realism through physics-aware VLM analysis.
- Thresholding Binary Reward employs a discretization mechanism where values exceeding a threshold receive 1, others 0, specifically designed to evaluate generative models’ ability to learn abrupt reward distributions under threshold-based optimization.
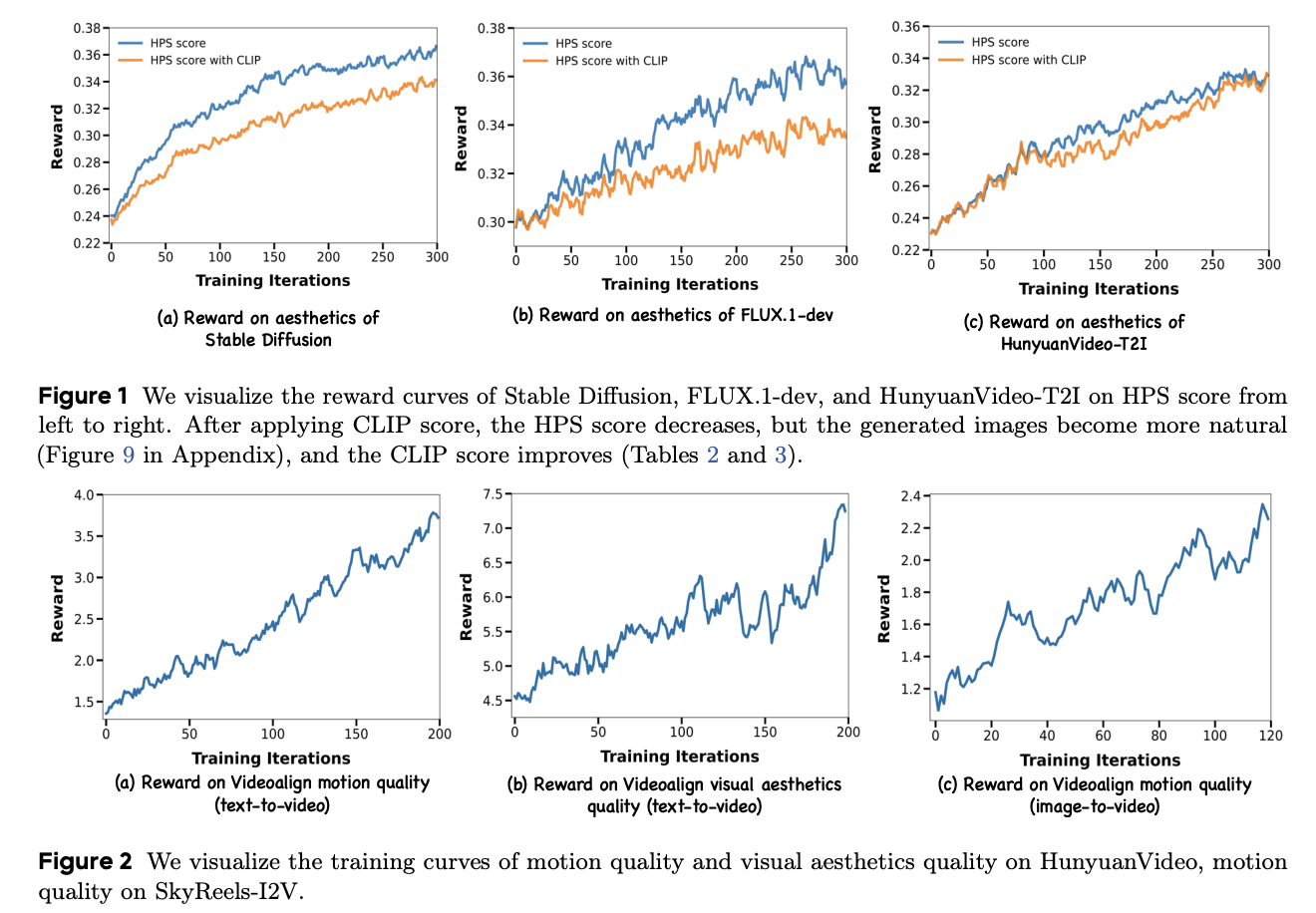
DanceGRPO shows significant improvements in reward metrics for Stable Diffusion v1.4 with an increase in the HPS score from 0.239 to 0.365, and CLIP Score from 0.363 to 0.395. Pick-a-Pic and GenEval evaluations confirm the method’s effectiveness, with DanceGRPO outperforming all competing approaches. For HunyuanVideo-T2I, optimization using the HPS-v2.1 model increases the mean reward score from 0.23 to 0.33, showing enhanced alignment with human aesthetic preferences. With HunyuanVideo, despite excluding text-video alignment due to instability, the methodology achieves relative improvements of 56% and 181% in visual and motion quality metrics, respectively. DanceGRPO uses the VideoAlign reward model’s motion quality metric, achieving a substantial 91% relative improvement in this dimension.
In this paper, researchers have introduced DanceGRPO, a unified framework for enhancing diffusion models and rectified flows across text-to-image, text-to-video, and image-to-video tasks. It addresses critical limitations of prior methods by bridging the gap between language and visual modalities, achieving superior performance through efficient alignment with human preferences and robust scaling to complex, multi-task settings. Experiments demonstrate substantial improvements in visual fidelity, motion quality, and text-image alignment. Future work will explore GRPO’s extension to multimodal generation, further unifying optimization paradigms across Generative AI.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 90k+ ML SubReddit.
The post DanceGRPO: A Unified Framework for Reinforcement Learning in Visual Generation Across Multiple Paradigms and Tasks appeared first on MarkTechPost.
Source: Read MoreÂ

