
In recent years, contrastive language-image models such as CLIP have established themselves as a default choice for learning vision representations, particularly in multimodal applications like Visual Question Answering (VQA) and document understanding. These models leverage large-scale image-text pairs to incorporate semantic grounding via language supervision. However, this reliance on text introduces both conceptual and practical challenges: the assumption that language is essential for multimodal performance, the complexity of acquiring aligned datasets, and the scalability limits imposed by data availability. In contrast, visual self-supervised learning (SSL)—which operates without language—has historically demonstrated competitive results on classification and segmentation tasks, yet has been underutilized for multimodal reasoning due to performance gaps, especially in OCR and chart-based tasks.
Meta Releases WebSSL Models on Hugging Face (300M–7B Parameters)
To explore the capabilities of language-free visual learning at scale, Meta has released the Web-SSL family of DINO and Vision Transformer (ViT) models, ranging from 300 million to 7 billion parameters, now publicly available via Hugging Face. These models are trained exclusively on the image subset of the MetaCLIP dataset (MC-2B)—a web-scale dataset comprising two billion images. This controlled setup enables a direct comparison between WebSSL and CLIP, both trained on identical data, isolating the effect of language supervision.
The objective is not to replace CLIP, but to rigorously evaluate how far pure visual self-supervision can go when model and data scale are no longer limiting factors. This release represents a significant step toward understanding whether language supervision is necessary—or merely beneficial—for training high-capacity vision encoders.

Technical Architecture and Training Methodology
WebSSL encompasses two visual SSL paradigms: joint-embedding learning (via DINOv2) and masked modeling (via MAE). Each model follows a standardized training protocol using 224×224 resolution images and maintains a frozen vision encoder during downstream evaluation to ensure that observed differences are attributable solely to pretraining.
Models are trained across five capacity tiers (ViT-1B to ViT-7B), using only unlabeled image data from MC-2B. Evaluation is conducted using Cambrian-1, a comprehensive 16-task VQA benchmark suite encompassing general vision understanding, knowledge-based reasoning, OCR, and chart-based interpretation.
In addition, the models are natively supported in Hugging Face’s transformers library, providing accessible checkpoints and seamless integration into research workflows.
Performance Insights and Scaling Behavior
Experimental results reveal several key findings:
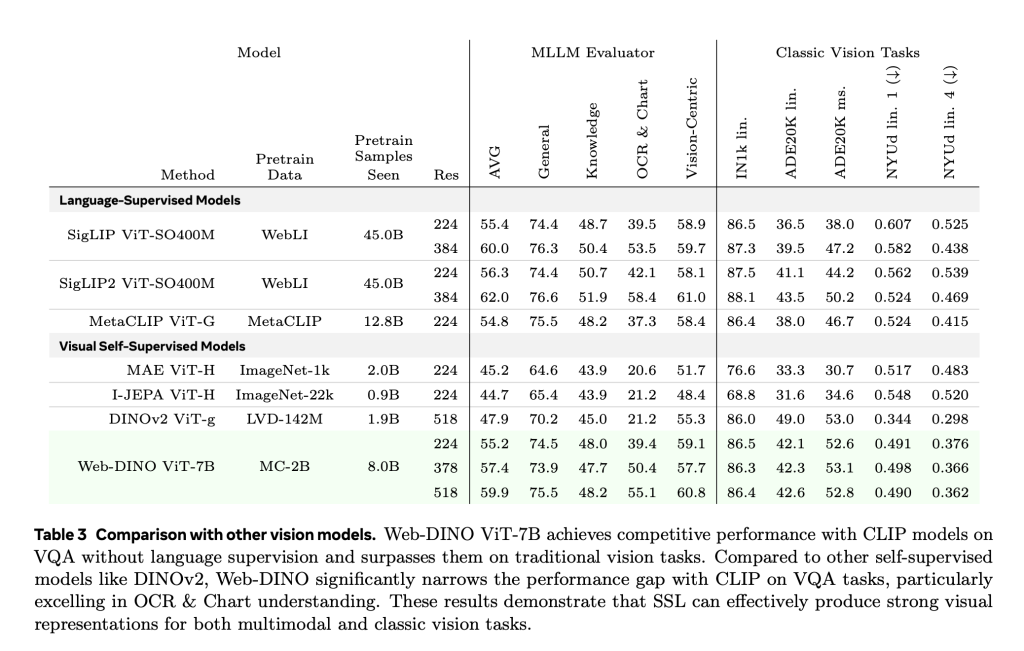
- Scaling Model Size: WebSSL models demonstrate near log-linear improvements in VQA performance with increasing parameter count. In contrast, CLIP’s performance plateaus beyond 3B parameters. WebSSL maintains competitive results across all VQA categories and shows pronounced gains in Vision-Centric and OCR & Chart tasks at larger scales.
- Data Composition Matters: By filtering the training data to include only 1.3% of text-rich images, WebSSL outperforms CLIP on OCR & Chart tasks—achieving up to +13.6% gains in OCRBench and ChartQA. This suggests that the presence of visual text alone, not language labels, significantly enhances task-specific performance.
- High-Resolution Training: WebSSL models fine-tuned at 518px resolution further close the performance gap with high-resolution models like SigLIP, particularly for document-heavy tasks.
- LLM Alignment: Without any language supervision, WebSSL shows improved alignment with pretrained language models (e.g., LLaMA-3) as model size and training exposure increase. This emergent behavior implies that larger vision models implicitly learn features that correlate well with textual semantics.
Importantly, WebSSL maintains strong performance on traditional benchmarks (ImageNet-1k classification, ADE20K segmentation, NYUv2 depth estimation), and often outperforms MetaCLIP and even DINOv2 under equivalent settings.
Concluding Observations
Meta’s Web-SSL study provides strong evidence that visual self-supervised learning, when scaled appropriately, is a viable alternative to language-supervised pretraining. These findings challenge the prevailing assumption that language supervision is essential for multimodal understanding. Instead, they highlight the importance of dataset composition, model scale, and careful evaluation across diverse benchmarks.
The release of models ranging from 300M to 7B parameters enables broader research and downstream experimentation without the constraints of paired data or proprietary pipelines. As open-source foundations for future multimodal systems, WebSSL models represent a meaningful advancement in scalable, language-free vision learning.
Check out the Models on Hugging Face, GitHub Page and Paper. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 90k+ ML SubReddit.
 [Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop
[Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on WorkshopThe post Meta AI Releases Web-SSL: A Scalable and Language-Free Approach to Visual Representation Learning appeared first on MarkTechPost.
Source: Read MoreÂ

