
The Challenge of Designing General-Purpose Vision Encoders
As AI systems grow increasingly multimodal, the role of visual perception models becomes more complex. Vision encoders are expected not only to recognize objects and scenes, but also to support tasks like captioning, question answering, fine-grained recognition, document parsing, and spatial reasoning across both images and videos. Existing models typically rely on diverse pretraining objectives—contrastive learning for retrieval, captioning for language tasks, and self-supervised methods for spatial understanding. This fragmentation complicates scalability and model deployment, and introduces trade-offs in performance across tasks.
What remains a key challenge is the design of a unified vision encoder that can match or exceed task-specific methods, operate robustly in open-world scenarios, and scale efficiently across modalities.
A Unified Solution: Meta AI’s Perception Encoder
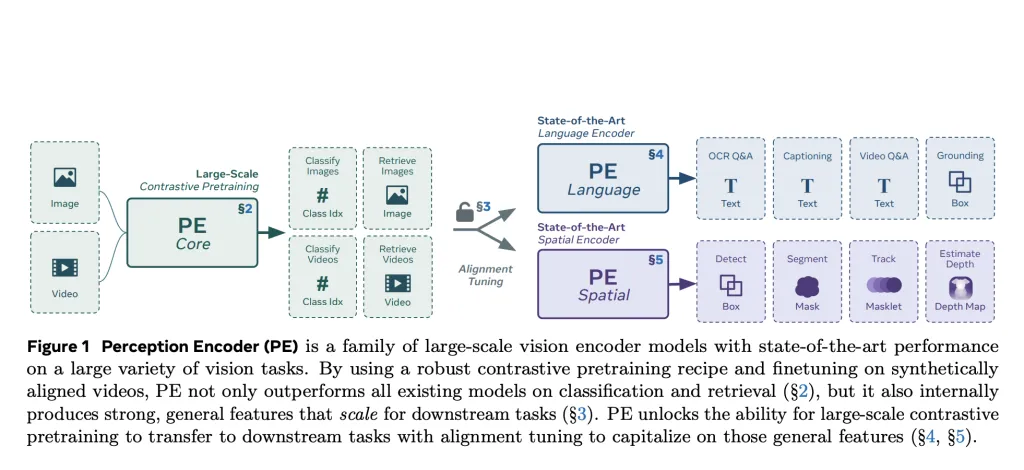
Meta AI introduces Perception Encoder (PE), a vision model family trained using a single contrastive vision-language objective and refined with alignment techniques tailored for downstream tasks. PE departs from the traditional multi-objective pretraining paradigm. Instead, it demonstrates that with a carefully tuned training recipe and appropriate alignment methods, contrastive learning alone can yield highly generalizable visual representations.
The Perception Encoder operates across three scales—PEcoreB, PEcoreL, and PEcoreG—with the largest (G-scale) model containing 2B parameters. These models are designed to function as general-purpose encoders for both image and video inputs, offering strong performance in classification, retrieval, and multimodal reasoning.
Training Approach and Architecture
The pretraining of PE follows a two-stage process. The first stage involves robust contrastive learning on a large-scale curated image-text dataset (5.4B pairs), where several architectural and training enhancements improve both accuracy and robustness. These include progressive resolution scaling, large batch sizes (up to 131K), use of the LAMB optimizer, 2D RoPE positional encoding, tuned augmentations, and masked regularization.
The second stage introduces video understanding by leveraging a video data engine that synthesizes high-quality video-text pairs. This pipeline incorporates captions from the Perception Language Model (PLM), frame-level descriptions, and metadata, which are then summarized using Llama 3.3. These synthetic annotations allow the same image encoder to be fine-tuned for video tasks via frame averaging.
Despite using a single contrastive objective, PE features general-purpose representations distributed across intermediate layers. To access these, Meta introduces two alignment strategies:
- Language alignment for tasks such as visual question answering and captioning.
- Spatial alignment for detection, tracking, and depth estimation, using self-distillation and spatial correspondence distillation via SAM2.
Empirical Performance Across Modalities
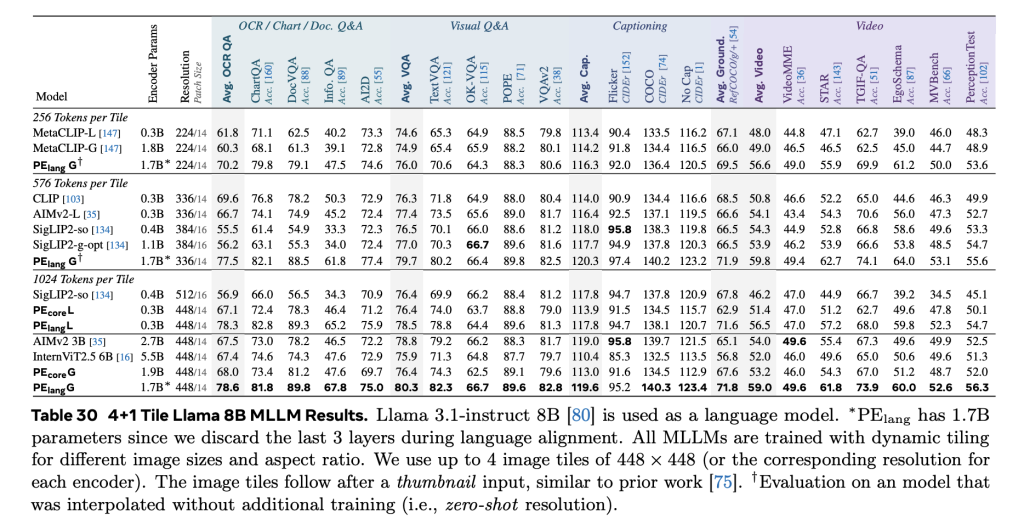
PE demonstrates strong zero-shot generalization across a wide range of vision benchmarks. On image classification, PEcoreG matches or exceeds proprietary models trained on large private datasets such as JFT-3B. It achieves:
- 86.6% on ImageNet-val,
- 92.6% on ImageNet-Adversarial,
- 88.2% on the full ObjectNet set,
- Competitive results on fine-grained datasets including iNaturalist, Food101, and Oxford Flowers.
In video tasks, PE achieves state-of-the-art performance on zero-shot classification and retrieval benchmarks, outperforming InternVideo2 and SigLIP2-g-opt, while being trained on just 22M synthetic video-caption pairs. The use of simple average pooling across frames—rather than temporal attention—demonstrates that architectural simplicity, when paired with well-aligned training data, can still yield high-quality video representations.
An ablation study shows that each component of the video data engine contributes meaningfully to performance. Improvements of +3.9% in classification and +11.1% in retrieval over image-only baselines highlight the utility of synthetic video data, even at modest scale.
Conclusion
Perception Encoder provides a technically compelling demonstration that a single contrastive objective, if implemented with care and paired with thoughtful alignment strategies, is sufficient to build general-purpose vision encoders. PE not only matches specialized models in their respective domains but does so with a unified and scalable approach.
The release of PE, along with its codebase and the PE Video Dataset, offers the research community a reproducible and efficient foundation for building multimodal AI systems. As visual reasoning tasks grow in complexity and scope, PE provides a path forward toward more integrated and robust visual understanding.
Check out the Paper, Model, Code and Dataset. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 90k+ ML SubReddit.
 [Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop
[Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on WorkshopThe post Meta AI Introduces Perception Encoder: A Large-Scale Vision Encoder that Excels Across Several Vision Tasks for Images and Video appeared first on MarkTechPost.
Source: Read MoreÂ

