
Large Multimodal Models (LMMs) have demonstrated remarkable capabilities when trained on extensive visual-text paired data, advancing multimodal understanding tasks significantly. However, these models struggle with complex real-world knowledge, particularly long-tail information that emerges after training cutoffs or domain-specific knowledge restricted by privacy, copyright, or security concerns. When forced to operate beyond their internal knowledge boundaries, LMMs often produce hallucinations, severely compromising their reliability in scenarios where factual accuracy is paramount. While Retrieval-Augmented Generation (RAG) has been widely implemented to overcome these limitations, it introduces its challenges: the decoupled retrieval and generation components resist end-to-end optimisation, and its rigid “retrieve-then-generate” approach triggers unnecessary retrievals even when the model already possesses sufficient knowledge, resulting in increased latency and computational costs.
Recent approaches have made significant strides in addressing knowledge limitations in large models. End-to-end reinforcement learning (RL) methods like OpenAI’s o-series, DeepSeek-R1, and Kimi K-1.5 have remarkably improved model reasoning capabilities. Simultaneously, Deep Research Models developed by major AI labs have shown that training models to interact directly with internet content substantially enhances their performance on complex real-world tasks. Despite these advances, challenges persist in efficiently integrating external knowledge retrieval with generation capabilities. Current methods either prioritize reasoning without optimized knowledge access or focus on retrieval mechanisms that aren’t seamlessly integrated with the model’s generation process. These approaches often fail to achieve the optimal balance between computational efficiency, response accuracy, and the ability to handle dynamic information, leaving significant room for improvement in creating truly adaptive and knowledge-aware multimodal systems.
Researchers have attempted to explore an end-to-end RL framework to extend the capability boundaries of LMMs. And tried to answer the following questions:
(1) Can LMMs be trained to perceive their knowledge boundaries and learn to invoke search tools when necessary?
(2) What are the effectiveness and efficiency of the RL approach?
(3) Could the RL framework lead to the emergence of robust multimodal intelligent behaviors?
This research introduces MMSearch-R1, which represents a pioneering approach to equip LMMs with active image search capabilities through an end-to-end reinforcement learning framework. This robust method focuses specifically on enhancing visual question answering (VQA) performance by enabling models to autonomously engage with image search tools. MMSearch-R1 trains models to make critical decisions about when to initiate image searches and how to effectively process the retrieved visual information. The system excels at extracting, synthesizing, and utilizing relevant visual data to support sophisticated reasoning processes. As a foundational advancement in multimodal AI, MMSearch-R1 enables LMMs to dynamically interact with external tools in a goal-oriented manner, significantly improving performance on knowledge-intensive and long-tail VQA tasks that traditionally challenge conventional models with their static knowledge bases.
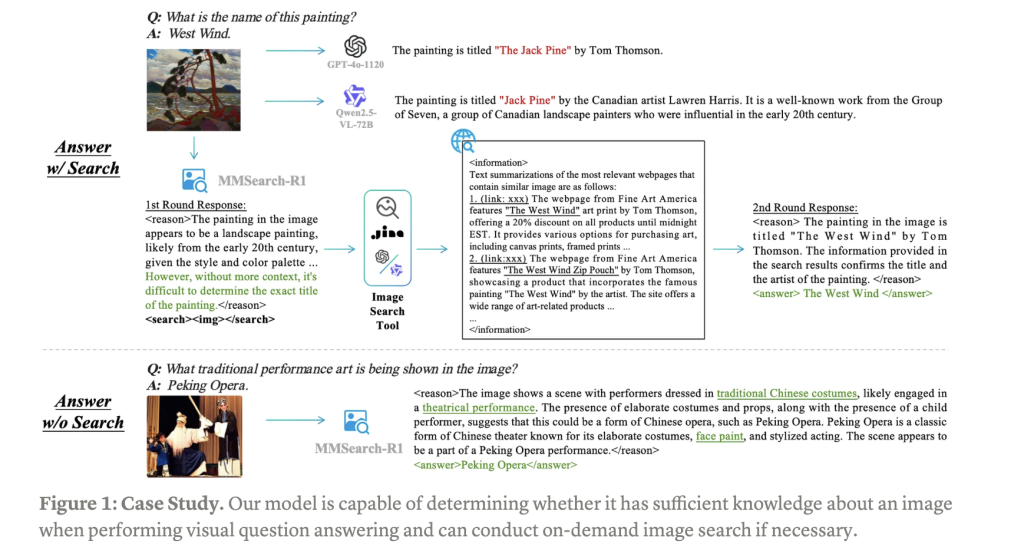
MMSearch-R1 employs a comprehensive architecture that combines sophisticated data engineering with advanced reinforcement learning techniques. The system builds upon the robust FactualVQA dataset, specifically constructed to provide unambiguous answers that can be reliably evaluated with automated methods. This dataset was created by extracting 50,000 Visual Concepts from both familiar and unfamiliar sections of the MetaCLIP metadata distribution, retrieving associated images, and using GPT-4o to generate factual question-answer pairs. After rigorous filtering and balancing processes, the dataset ensures an optimal mix of queries that can be answered with and without image search assistance.
The reinforcement learning framework adapts the standard GRPO algorithm with multi-turn rollouts, integrating an advanced image search tool based on the veRL framework for end-to-end training. This image search capability combines SerpApi, JINA Reader for content extraction, and LLM-based summarization to retrieve and process relevant web content associated with images. The system employs a carefully calibrated reward function that balances answer correctness, proper formatting, and a mild penalty for tool usage, calculated as 0.9 × (Score – 0.1) + 0.1 × Format when image search is used, and 0.9 × Score + 0.1 × Format when it is not.


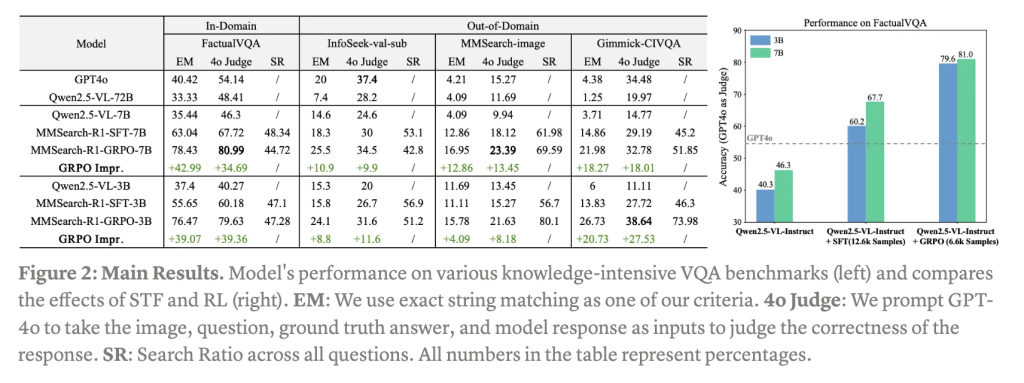
Experimental results demonstrate MMSearch-R1’s significant performance advantages across multiple dimensions. Image search capabilities effectively expand the knowledge boundaries of Large Multimodal Models, with the system learning to make intelligent decisions about when to initiate searches while avoiding over-reliance on external tools. Both supervised fine-tuning (SFT) and reinforcement learning implementations show substantial performance improvements across in-domain FactualVQA testing and out-of-domain benchmarks, including InfoSeek, MMSearch, and Gimmick. Also, the models dynamically adjust their search rates based on visual content familiarity, maintaining efficient resource utilization while maximizing accuracy.
Reinforcement learning demonstrates superior efficiency compared to supervised fine-tuning approaches. When applied directly to Qwen2.5-VL-Instruct-3B/7B models, GRPO achieves better results despite using only half the training data required by SFT methods. This remarkable efficiency highlights RL’s effectiveness in optimizing model performance with limited resources. The system’s ability to balance knowledge access with computational efficiency represents a significant advancement in creating more resource-conscious yet highly capable multimodal systems that can intelligently utilize external knowledge sources.
MMSearch-R1 successfully demonstrates that outcome-based reinforcement learning can effectively train Large Multimodal Models with active image search capabilities. This approach enables models to autonomously decide when to utilize external visual knowledge sources while maintaining computational efficiency. The promising results establish a strong foundation for developing future tool-augmented, reasoning-capable LMMs that can dynamically interact with the visual world.
Check out the Blog and Code. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 85k+ ML SubReddit.
 [Register Now] miniCON Virtual Conference on OPEN SOURCE AI: FREE REGISTRATION + Certificate of Attendance + 3 Hour Short Event (April 12, 9 am- 12 pm PST) + Hands on Workshop [Sponsored]
[Register Now] miniCON Virtual Conference on OPEN SOURCE AI: FREE REGISTRATION + Certificate of Attendance + 3 Hour Short Event (April 12, 9 am- 12 pm PST) + Hands on Workshop [Sponsored]The post MMSearch-R1: End-to-End Reinforcement Learning for Active Image Search in LMMs appeared first on MarkTechPost.
Source: Read MoreÂ

