SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. This can be overwhelming for nontechnical users who lack proficiency in SQL. Today, generative AI can help bridge this knowledge gap for nontechnical users to generate SQL queries by using a text-to-SQL application. This application allows users to ask questions in natural language and then generates a SQL query for the user’s request.
Large language models (LLMs) are trained to generate accurate SQL queries for natural language instructions. However, off-the-shelf LLMs can’t be used without some modification. Firstly, LLMs don’t have access to enterprise databases, and the models need to be customized to understand the specific database of an enterprise. Additionally, the complexity increases due to the presence of synonyms for columns and internal metrics available.
The limitation of LLMs in understanding enterprise datasets and human context can be addressed using Retrieval Augmented Generation (RAG). In this post, we explore using Amazon Bedrock to create a text-to-SQL application using RAG. We use Anthropic’s Claude 3.5 Sonnet model to generate SQL queries, Amazon Titan in Amazon Bedrock for text embedding and Amazon Bedrock to access these models.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
Solution overview
This solution is primarily based on the following services:
- Foundational model – We use Anthropic’s Claude 3.5 Sonnet on Amazon Bedrock as our LLM to generate SQL queries for user inputs.
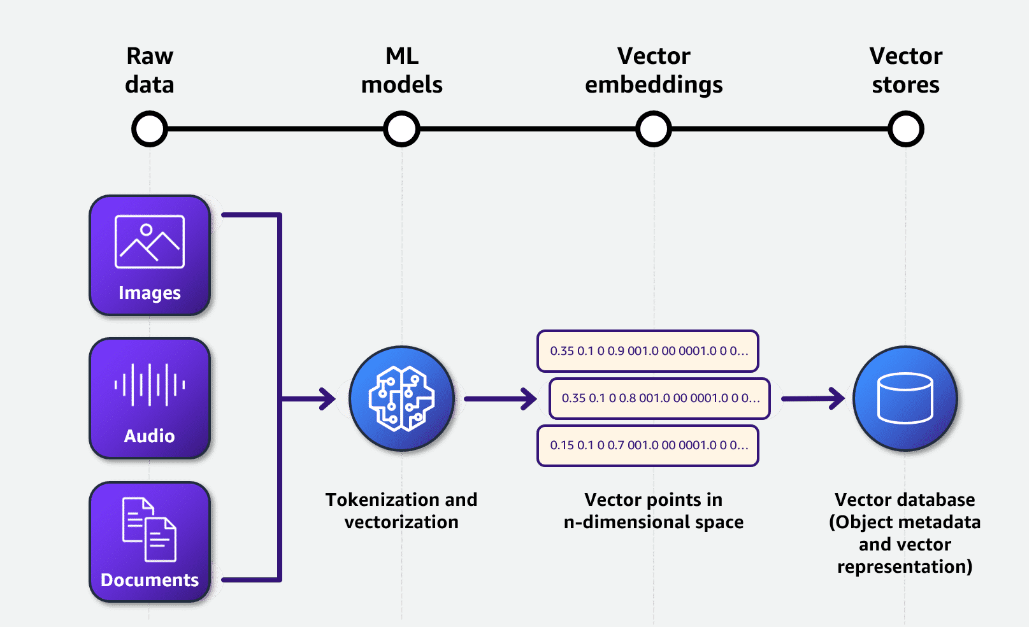
- Vector embeddings – We use Amazon Titan Text Embeddings v2 on Amazon Bedrock for embeddings. Embedding is the process by which text, images, and audio are given numerical representation in a vector space. Embedding is usually performed by a machine learning (ML) model. The following diagram provides more details about embeddings.

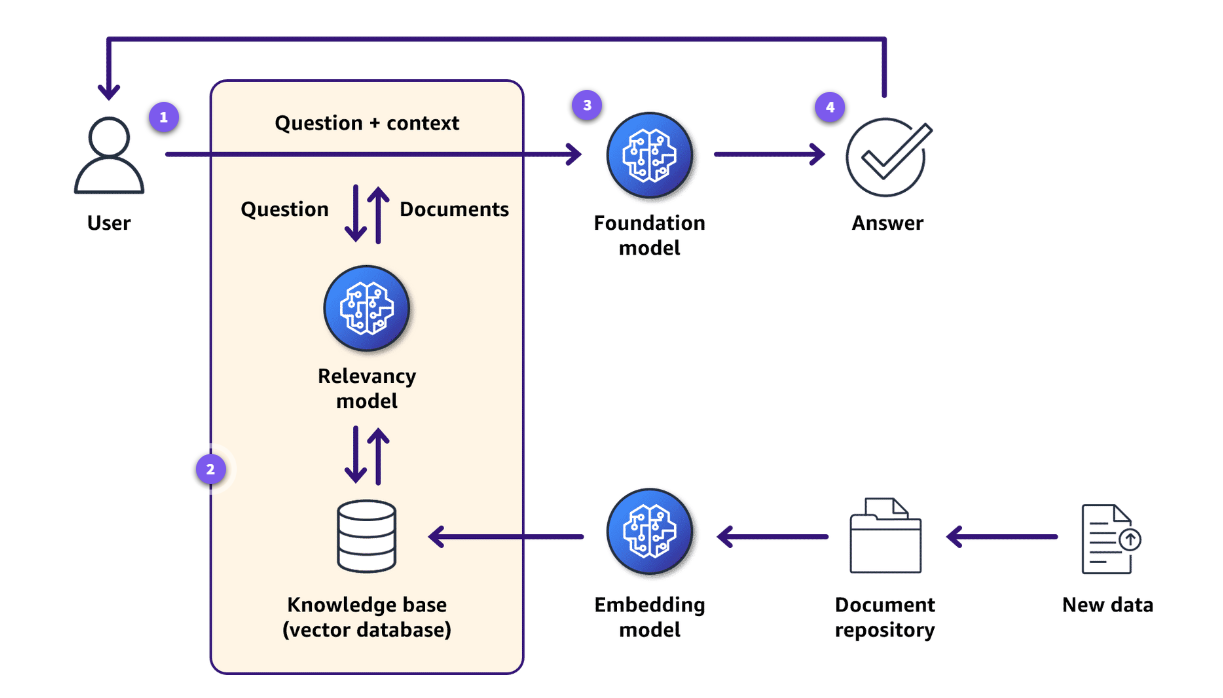
- RAG – We use RAG for providing more context about table schema, column synonyms, and sample queries to the FM. RAG is a framework for building generative AI applications that can make use of enterprise data sources and vector databases to overcome knowledge limitations. RAG works by using a retriever module to find relevant information from an external data store in response to a user’s prompt. This retrieved data is used as context, combined with the original prompt, to create an expanded prompt that is passed to the LLM. The language model then generates a SQL query that incorporates the enterprise knowledge. The following diagram illustrates the RAG framework.

- Streamlit – This open source Python library makes it straightforward to create and share beautiful, custom web apps for ML and data science. In just a few minutes you can build powerful data apps using only Python.
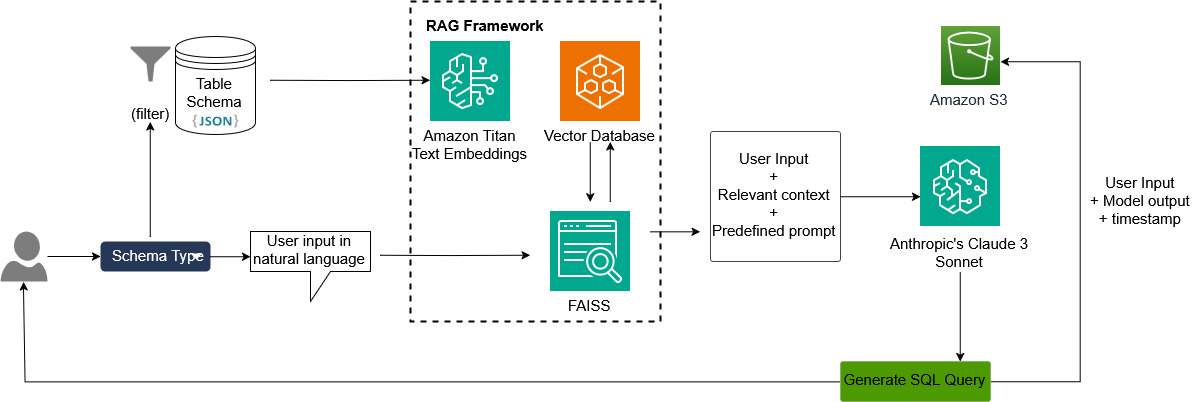
The following diagram shows the solution architecture.

We need to update the LLMs with an enterprise-specific database. This make sure that the model can correctly understand the database and generate a response tailored to enterprise-based data schema and tables. There are multiple file formats available for storing this information, such as JSON, PDF, TXT, and YAML. In our case, we created JSON files to store table schema, table descriptions, columns with synonyms, and sample queries. JSON’s inherently structured format allows for clear and organized representation of complex data such as table schemas, column definitions, synonyms, and sample queries. This structure facilitates quick parsing and manipulation of data in most programming languages, reducing the need for custom parsing logic.
There can be multiple tables with similar information, which can lower the model’s accuracy. To increase the accuracy, we categorized the tables in four different types based on the schema and created four JSON files to store different tables. We’ve added one dropdown menu with four choices. Each choice represents one of these four categories and is lined to individual JSON files. After the user selects the value from the dropdown menu, the relevant JSON file is passed to Amazon Titan Text Embeddings v2, which can convert text into embeddings. These embeddings are stored in a vector database for faster retrieval.
We added the prompt template to the FM to define the roles and responsibilities of the model. You can add additional information such as which SQL engine should be used to generate the SQL queries.
When the user provides the input through the chat prompt, we use similarity search to find the relevant table metadata from the vector database for the user’s query. The user input is combined with relevant table metadata and the prompt template, which is passed to the FM as a single input all together. The FM generates the SQL query based on the final input.
To evaluate the model’s accuracy and track the mechanism, we store every user input and output in Amazon Simple Storage Service (Amazon S3).
Prerequisites
To create this solution, complete the following prerequisites:
- Sign up for an AWS account if you don’t already have one.
- Enable model access for Amazon Titan Text Embeddings v2 and Anthropic’s Claude 3.5 Sonnet on Amazon Bedrock.
- Create an S3 bucket as ‘simplesql-logs-****‘, replace ‘****’ with your unique identifier. Bucket names are unique globally across the entire Amazon S3 service.
- Choose your testing environment. We recommend that you test in Amazon SageMaker Studio, although you can use other available local environments.
- Install the following libraries to execute the code:
pip install streamlit
pip install jq
pip install openpyxl
pip install "faiss-cpu"
pip install langchain
Procedure
There are three main components in this solution:
- JSON files store the table schema and configure the LLM
- Vector indexing using Amazon Bedrock
- Streamlit for the front-end UI
You can download all three components and code snippets provided in the following section.
Generate the table schema
We use the JSON format to store the table schema. To provide more inputs to the model, we added a table name and its description, columns and their synonyms, and sample queries in our JSON files. Create a JSON file as Table_Schema_A.json by copying the following code into it:
{
"tables": [
{
"separator": "table_1",
"name": "schema_a.orders",
"schema": "CREATE TABLE schema_a.orders (order_id character varying(200), order_date timestamp without time zone, customer_id numeric(38,0), order_status character varying(200), item_id character varying(200) );",
"description": "This table stores information about orders placed by customers.",
"columns": [
{
"name": "order_id",
"description": "unique identifier for orders.",
"synonyms": ["order id"]
},
{
"name": "order_date",
"description": "timestamp when the order was placed",
"synonyms": ["order time", "order day"]
},
{
"name": "customer_id",
"description": "Id of the customer associated with the order",
"synonyms": ["customer id", "userid"]
},
{
"name": "order_status",
"description": "current status of the order, sample values are: shipped, delivered, cancelled",
"synonyms": ["order status"]
},
{
"name": "item_id",
"description": "item associated with the order",
"synonyms": ["item id"]
}
],
"sample_queries": [
{
"query": "select count(order_id) as total_orders from schema_a.orders where customer_id = '9782226' and order_status = 'cancelled'",
"user_input": "Count of orders cancelled by customer id: 978226"
}
]
},
{
"separator": "table_2",
"name": "schema_a.customers",
"schema": "CREATE TABLE schema_a.customers (customer_id numeric(38,0), customer_name character varying(200), registration_date timestamp without time zone, country character varying(200) );",
"description": "This table stores the details of customers.",
"columns": [
{
"name": "customer_id",
"description": "Id of the customer, unique identifier for customers",
"synonyms": ["customer id"]
},
{
"name": "customer_name",
"description": "name of the customer",
"synonyms": ["name"]
},
{
"name": "registration_date",
"description": "registration timestamp when customer registered",
"synonyms": ["sign up time", "registration time"]
},
{
"name": "country",
"description": "customer's original country",
"synonyms": ["location", "customer's region"]
}
],
"sample_queries": [
{
"query": "select count(customer_id) as total_customers from schema_a.customers where country = 'India' and to_char(registration_date, 'YYYY') = '2024'",
"user_input": "The number of customers registered from India in 2024"
},
{
"query": "select count(o.order_id) as order_count from schema_a.orders o join schema_a.customers c on o.customer_id = c.customer_id where c.customer_name = 'john' and to_char(o.order_date, 'YYYY-MM') = '2024-01'",
"user_input": "Total orders placed in January 2024 by customer name john"
}
]
},
{
"separator": "table_3",
"name": "schema_a.items",
"schema": "CREATE TABLE schema_a.items (item_id character varying(200), item_name character varying(200), listing_date timestamp without time zone );",
"description": "This table stores the complete details of items listed in the catalog.",
"columns": [
{
"name": "item_id",
"description": "Id of the item, unique identifier for items",
"synonyms": ["item id"]
},
{
"name": "item_name",
"description": "name of the item",
"synonyms": ["name"]
},
{
"name": "listing_date",
"description": "listing timestamp when the item was registered",
"synonyms": ["listing time", "registration time"]
}
],
"sample_queries": [
{
"query": "select count(item_id) as total_items from schema_a.items where to_char(listing_date, 'YYYY') = '2024'",
"user_input": "how many items are listed in 2024"
},
{
"query": "select count(o.order_id) as order_count from schema_a.orders o join schema_a.customers c on o.customer_id = c.customer_id join schema_a.items i on o.item_id = i.item_id where c.customer_name = 'john' and i.item_name = 'iphone'",
"user_input": "how many orders are placed for item 'iphone' by customer name john"
}
]
}
]
}
Configure the LLM and initialize vector indexing using Amazon Bedrock
Create a Python file as library.py by following these steps:
- Add the following import statements to add the necessary libraries:
import boto3 # AWS SDK for Python
from langchain_community.document_loaders import JSONLoader # Utility to load JSON files
from langchain.llms import Bedrock # Large Language Model (LLM) from Anthropic
from langchain_community.chat_models import BedrockChat # Chat interface for Bedrock LLM
from langchain.embeddings import BedrockEmbeddings # Embeddings for Titan model
from langchain.memory import ConversationBufferWindowMemory # Memory to store chat conversations
from langchain.indexes import VectorstoreIndexCreator # Create vector indexes
from langchain.vectorstores import FAISS # Vector store using FAISS library
from langchain.text_splitter import RecursiveCharacterTextSplitter # Split text into chunks
from langchain.chains import ConversationalRetrievalChain # Conversational retrieval chain
from langchain.callbacks.manager import CallbackManager
- Initialize the Amazon Bedrock client and configure Anthropic’s Claude 3.5 You can limit the number of output tokens to optimize the cost:
# Create a Boto3 client for Bedrock Runtime
bedrock_runtime = boto3.client(
service_name="bedrock-runtime",
region_name="us-east-1"
)
# Function to get the LLM (Large Language Model)
def get_llm():
model_kwargs = { # Configuration for Anthropic model
"max_tokens": 512, # Maximum number of tokens to generate
"temperature": 0.2, # Sampling temperature for controlling randomness
"top_k": 250, # Consider the top k tokens for sampling
"top_p": 1, # Consider the top p probability tokens for sampling
"stop_sequences": ["nnHuman:"] # Stop sequence for generation
}
# Create a callback manager with a default callback handler
callback_manager = CallbackManager([])
llm = BedrockChat(
model_id="anthropic.claude-3-5-sonnet-20240620-v1:0", # Set the foundation model
model_kwargs=model_kwargs, # Pass the configuration to the model
callback_manager=callback_manager
)
return llm
- Create and return an index for the given schema type. This approach is an efficient way to filter tables and provide relevant input to the model:
# Function to load the schema file based on the schema type
def load_schema_file(schema_type):
if schema_type == 'Schema_Type_A':
schema_file = "Table_Schema_A.json" # Path to Schema Type A
elif schema_type == 'Schema_Type_B':
schema_file = "Table_Schema_B.json" # Path to Schema Type B
elif schema_type == 'Schema_Type_C':
schema_file = "Table_Schema_C.json" # Path to Schema Type C
return schema_file
# Function to get the vector index for the given schema type
def get_index(schema_type):
embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v2:0",
client=bedrock_runtime) # Initialize embeddings
db_schema_loader = JSONLoader(
file_path=load_schema_file(schema_type), # Load the schema file
# file_path="Table_Schema_RP.json", # Uncomment to use a different file
jq_schema='.', # Select the entire JSON content
text_content=False) # Treat the content as text
db_schema_text_splitter = RecursiveCharacterTextSplitter( # Create a text splitter
separators=["separator"], # Split chunks at the "separator" string
chunk_size=10000, # Divide into 10,000-character chunks
chunk_overlap=100 # Allow 100 characters to overlap with previous chunk
)
db_schema_index_creator = VectorstoreIndexCreator(
vectorstore_cls=FAISS, # Use FAISS vector store
embedding=embeddings, # Use the initialized embeddings
text_splitter=db_schema_text_splitter # Use the text splitter
)
db_index_from_loader = db_schema_index_creator.from_loaders([db_schema_loader]) # Create index from loader
return db_index_from_loader
- Use the following function to create and return memory for the chat session:
# Function to get the memory for storing chat conversations
def get_memory():
memory = ConversationBufferWindowMemory(memory_key="chat_history", return_messages=True) # Create memory
return memory
- Use the following prompt template to generate SQL queries based on user input:
# Template for the question prompt
template = """ Read table information from the context. Each table contains the following information:
- Name: The name of the table
- Description: A brief description of the table
- Columns: The columns of the table, listed under the 'columns' key. Each column contains:
- Name: The name of the column
- Description: A brief description of the column
- Type: The data type of the column
- Synonyms: Optional synonyms for the column name
- Sample Queries: Optional sample queries for the table, listed under the 'sample_data' key
Given this structure, Your task is to provide the SQL query using Amazon Redshift syntax that would retrieve the data for following question. The produced query should be functional, efficient, and adhere to best practices in SQL query optimization.
Question: {}
"""
- Use the following function to get a response from the RAG chat model:
# Function to get the response from the conversational retrieval chain
def get_rag_chat_response(input_text, memory, index):
llm = get_llm() # Get the LLM
conversation_with_retrieval = ConversationalRetrievalChain.from_llm(
llm, index.vectorstore.as_retriever(), memory=memory, verbose=True) # Create conversational retrieval chain
chat_response = conversation_with_retrieval.invoke({"question": template.format(input_text)}) # Invoke the chain
return chat_response['answer'] # Return the answer
Configure Streamlit for the front-end UI
Create the file app.py by following these steps:
- Import the necessary libraries:
import streamlit as st
import library as lib
from io import StringIO
import boto3
from datetime import datetime
import csv
import pandas as pd
from io import BytesIO
- Initialize the S3 client:
s3_client = boto3.client('s3')
bucket_name = 'simplesql-logs-****'
#replace the 'simplesql-logs-****’ with your S3 bucket name
log_file_key = 'logs.xlsx'
- Configure Streamlit for UI:
st.set_page_config(page_title="Your App Name")
st.title("Your App Name")
# Define the available menu items for the sidebar
menu_items = ["Home", "How To", "Generate SQL Query"]
# Create a sidebar menu using radio buttons
selected_menu_item = st.sidebar.radio("Menu", menu_items)
# Home page content
if selected_menu_item == "Home":
# Display introductory information about the application
st.write("This application allows you to generate SQL queries from natural language input.")
st.write("")
st.write("**Get Started** by selecting the button Generate SQL Query !")
st.write("")
st.write("")
st.write("**Disclaimer :**")
st.write("- Model's response depends on user's input (prompt). Please visit How-to section for writing efficient prompts.")
# How-to page content
elif selected_menu_item == "How To":
# Provide guidance on how to use the application effectively
st.write("The model's output completely depends on the natural language input. Below are some examples which you can keep in mind while asking the questions.")
st.write("")
st.write("")
st.write("")
st.write("")
st.write("**Case 1 :**")
st.write("- **Bad Input :** Cancelled orders")
st.write("- **Good Input :** Write a query to extract the cancelled order count for the items which were listed this year")
st.write("- It is always recommended to add required attributes, filters in your prompt.")
st.write("**Case 2 :**")
st.write("- **Bad Input :** I am working on XYZ project. I am creating a new metric and need the sales data. Can you provide me the sales at country level for 2023 ?")
st.write("- **Good Input :** Write an query to extract sales at country level for orders placed in 2023 ")
st.write("- Every input is processed as tokens. Do not provide un-necessary details as there is a cost associated with every token processed. Provide inputs only relevant to your query requirement.")
- Generate the query:
# SQL-AI page content
elif selected_menu_item == "Generate SQL Query":
# Define the available schema types for selection
schema_types = ["Schema_Type_A", "Schema_Type_B", "Schema_Type_C"]
schema_type = st.sidebar.selectbox("Select Schema Type", schema_types)
- Use the following for SQL generation:
if schema_type:
# Initialize or retrieve conversation memory from session state
if 'memory' not in st.session_state:
st.session_state.memory = lib.get_memory()
# Initialize or retrieve chat history from session state
if 'chat_history' not in st.session_state:
st.session_state.chat_history = []
# Initialize or update vector index based on selected schema type
if 'vector_index' not in st.session_state or 'current_schema' not in st.session_state or st.session_state.current_schema != schema_type:
with st.spinner("Indexing document..."):
# Create a new index for the selected schema type
st.session_state.vector_index = lib.get_index(schema_type)
# Update the current schema in session state
st.session_state.current_schema = schema_type
# Display the chat history
for message in st.session_state.chat_history:
with st.chat_message(message["role"]):
st.markdown(message["text"])
# Get user input through the chat interface, set the max limit to control the input tokens.
input_text = st.chat_input("Chat with your bot here", max_chars=100)
if input_text:
# Display user input in the chat interface
with st.chat_message("user"):
st.markdown(input_text)
# Add user input to the chat history
st.session_state.chat_history.append({"role": "user", "text": input_text})
# Generate chatbot response using the RAG model
chat_response = lib.get_rag_chat_response(
input_text=input_text,
memory=st.session_state.memory,
index=st.session_state.vector_index
)
# Display chatbot response in the chat interface
with st.chat_message("assistant"):
st.markdown(chat_response)
# Add chatbot response to the chat history
st.session_state.chat_history.append({"role": "assistant", "text": chat_response})
- Log the conversations to the S3 bucket:
timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
try:
# Attempt to download the existing log file from S3
log_file_obj = s3_client.get_object(Bucket=bucket_name, Key=log_file_key)
log_file_content = log_file_obj['Body'].read()
df = pd.read_excel(BytesIO(log_file_content))
except s3_client.exceptions.NoSuchKey:
# If the log file doesn't exist, create a new DataFrame
df = pd.DataFrame(columns=["User Input", "Model Output", "Timestamp", "Schema Type"])
# Create a new row with the current conversation data
new_row = pd.DataFrame({
"User Input": [input_text],
"Model Output": [chat_response],
"Timestamp": [timestamp],
"Schema Type": [schema_type]
})
# Append the new row to the existing DataFrame
df = pd.concat([df, new_row], ignore_index=True)
# Prepare the updated DataFrame for S3 upload
output = BytesIO()
df.to_excel(output, index=False)
output.seek(0)
# Upload the updated log file to S3
s3_client.put_object(Body=output.getvalue(), Bucket=bucket_name, Key=log_file_key)
Test the solution
Open your terminal and invoke the following command to run the Streamlit application.
streamlit run app.py
To visit the application using your browser, navigate to the localhost.
To visit the application using SageMaker, copy your notebook URL and replace ‘default/lab’ in the URL with ‘default/proxy/8501/ ‘ . It should look something like the following:
https://your_sagemaker_lab_url.studio.us-east-1.sagemaker.aws/jupyterlab/default/proxy/8501/
Choose Generate SQL query to open the chat window. Test your application by asking questions in natural language. We tested the application with the following questions and it generated accurate SQL queries.
Count of orders placed from India last month?
Write a query to extract the canceled order count for the items that were listed this year.
Write a query to extract the top 10 item names having highest order for each country.
Troubleshooting tips
Use the following solutions to address errors:
Error – An error raised by inference endpoint means that an error occurred (AccessDeniedException) when calling the InvokeModel operation. You don’t have access to the model with the specified model ID.
Solution – Make sure you have access to the FMs in Amazon Bedrock, Amazon Titan Text Embeddings v2, and Anthropic’s Claude 3.5 Sonnet.
Error – app.py does not exist
Solution – Make sure your JSON file and Python files are in the same folder and you’re invoking the command in the same folder.
Error – No module named streamlit
Solution – Open the terminal and install the streamlit module by running the command pip install streamlit
Error – An error occurred (NoSuchBucket) when calling the GetObject operation. The specified bucket doesn’t exist.
Solution – Verify your bucket name in the app.py file and update the name based on your S3 bucket name.
Clean up
Clean up the resources you created to avoid incurring charges. To clean up your S3 bucket, refer to Emptying a bucket.
Conclusion
In this post, we showed how Amazon Bedrock can be used to create a text-to-SQL application based on enterprise-specific datasets. We used Amazon S3 to store the outputs generated by the model for corresponding inputs. These logs can be used to test the accuracy and enhance the context by providing more details in the knowledge base. With the aid of a tool like this, you can create automated solutions that are accessible to nontechnical users, empowering them to interact with data more efficiently.
Ready to get started with Amazon Bedrock? Start learning with these interactive workshops.
For more information on SQL generation, refer to these posts:
We recently launched a managed NL2SQL module to retrieve structured data in Amazon Bedrock Knowledge . To learn more, visit Amazon Bedrock Knowledge Bases now supports structured data retrieval.
About the Author
 Rajendra Choudhary is a Sr. Business Analyst at Amazon. With 7 years of experience in developing data solutions, he possesses profound expertise in data visualization, data modeling, and data engineering. He is passionate about supporting customers by leveraging generative AI–based solutions. Outside of work, Rajendra is an avid foodie and music enthusiast, and he enjoys swimming and hiking.
Rajendra Choudhary is a Sr. Business Analyst at Amazon. With 7 years of experience in developing data solutions, he possesses profound expertise in data visualization, data modeling, and data engineering. He is passionate about supporting customers by leveraging generative AI–based solutions. Outside of work, Rajendra is an avid foodie and music enthusiast, and he enjoys swimming and hiking.
Source: Â
")
 Rajendra Choudhary is a Sr. Business Analyst at Amazon. With 7 years of experience in developing data solutions, he possesses profound expertise in data visualization, data modeling, and data engineering. He is passionate about supporting customers by leveraging generative AI–based solutions. Outside of work, Rajendra is an avid foodie and music enthusiast, and he enjoys swimming and hiking.
Rajendra Choudhary is a Sr. Business Analyst at Amazon. With 7 years of experience in developing data solutions, he possesses profound expertise in data visualization, data modeling, and data engineering. He is passionate about supporting customers by leveraging generative AI–based solutions. Outside of work, Rajendra is an avid foodie and music enthusiast, and he enjoys swimming and hiking.