




Comparing language models effectively requires a systematic approach that combines standardized benchmarks with use-case specific testing. This guide walks you through the process of evaluating LLMs to make informed decisions for your projects.
Table of contents
- Step 1: Define Your Comparison Goals
- Step 2: Choose Appropriate Benchmarks
- Step 3: Review Existing Leaderboards
- Step 4: Set Up Testing Environment
- Step 5: Use Evaluation Frameworks
- Step 6: Implement Custom Evaluation Tests
- Step 7: Analyze Results
- Step 8: Document and Visualize Findings
- Step 9: Consider Trade-offs
- Step 10: Make an Informed Decision
Step 1: Define Your Comparison Goals
Before diving into benchmarks, clearly establish what you’re trying to evaluate:
 Key Questions to Answer:
Key Questions to Answer:
- What specific capabilities matter most for your application?
- Are you prioritizing accuracy, speed, cost, or specialized knowledge?
- Do you need quantitative metrics, qualitative evaluations, or both?
Pro Tip: Create a simple scoring rubric with weighted importance for each capability relevant to your use case.
Step 2: Choose Appropriate Benchmarks
Different benchmarks measure different LLM capabilities:
General Language Understanding
- MMLU (Massive Multitask Language Understanding)
- HELM (Holistic Evaluation of Language Models)
- BIG-Bench (Beyond the Imitation Game Benchmark)
Reasoning & Problem-Solving
- GSM8K (Grade School Math 8K)
- MATH (Mathematics Aptitude Test of Heuristics)
- LogiQA (Logical Reasoning)
Coding & Technical Ability
- HumanEval (Python Function Synthesis)
- MBPP (Mostly Basic Python Programming)
- DS-1000 (Data Science Problems)
Truthfulness & Factuality
- TruthfulQA (Truthful Question Answering)
- FActScore (Factuality Scoring)
Instruction Following
- Alpaca Eval
- MT-Bench (Multi-Turn Benchmark)
Safety Evaluation
- Anthropic’s Red Teaming dataset
- SafetyBench
Pro Tip: Focus on benchmarks that align with your specific use case rather than trying to test everything.
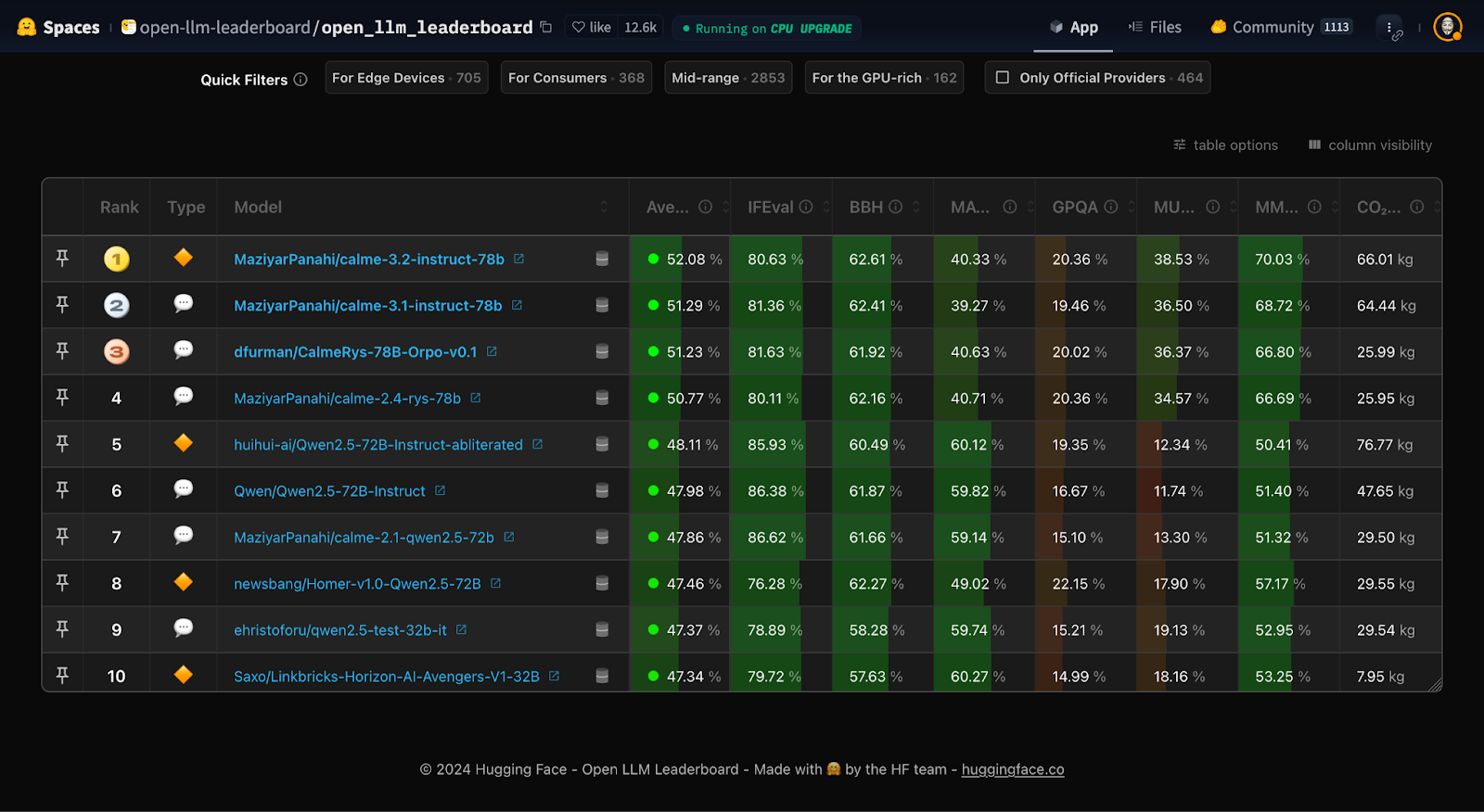
Step 3: Review Existing Leaderboards
Save time by checking published results on established leaderboards:
Recommended Leaderboards
- Hugging Face Open LLM Leaderboard
- Stanford CRFM HELM Leaderboard
- LMSys Chatbot Arena
- Papers with Code LLM benchmarks
Step 4: Set Up Testing Environment
Ensure fair comparison with consistent test conditions:
Environment Checklist
- Use identical hardware for all tests when possible
- Control for temperature, max tokens, and other generation parameters
- Document API versions or deployment configurations
- Standardize prompt formatting and instructions
- Use the same evaluation criteria across models
Pro Tip: Create a configuration file that documents all your testing parameters for reproducibility.
Step 5: Use Evaluation Frameworks
Several frameworks can help automate and standardize your evaluation process:
Popular Evaluation Frameworks
| Framework | Best For | Installation | Documentation |
| LMSYS Chatbot Arena | Human evaluations | Web-based | Link |
| LangChain Evaluation | Workflow testing | pip install langchain-eval | Link |
| EleutherAI LM Evaluation Harness | Academic benchmarks | pip install lm-eval | Link |
| DeepEval | Unit testing | pip install deepeval | Link |
| Promptfoo | Prompt comparison | npm install -g promptfoo | Link |
| TruLens | Feedback analysis | pip install trulens-eval | Link |

Step 6: Implement Custom Evaluation Tests
Go beyond standard benchmarks with tests tailored to your needs:
Custom Test Categories
- Domain-specific knowledge tests relevant to your industry
- Real-world prompts from your expected use cases
- Edge cases that push the boundaries of model capabilities
- A/B comparisons with identical inputs across models
- User experience testing with representative users
Pro Tip: Include both “expected” scenarios and “stress test” scenarios that challenge the models.
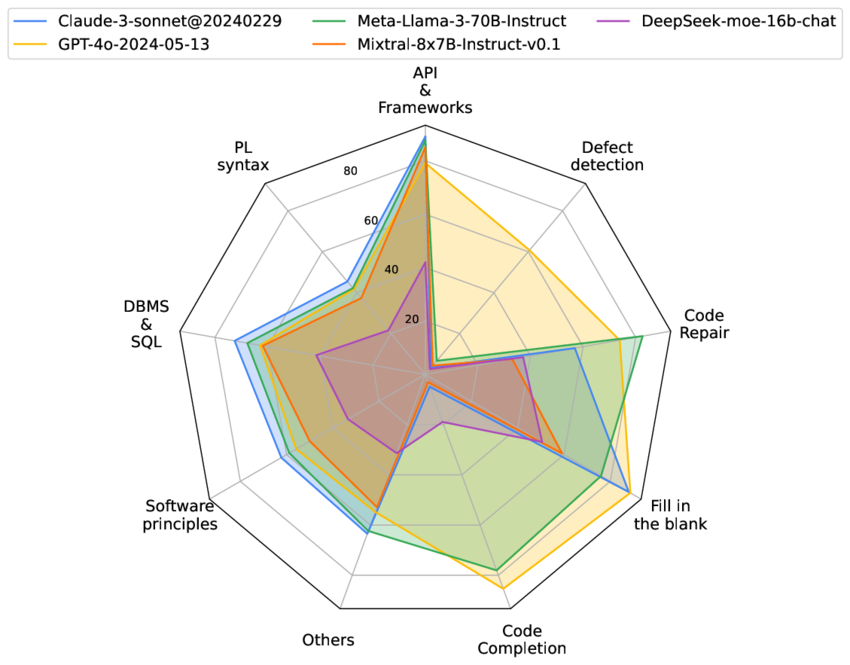
Step 7: Analyze Results
Transform raw data into actionable insights:
Analysis Techniques
- Compare raw scores across benchmarks
- Normalize results to account for different scales
- Calculate performance gaps as percentages
- Identify patterns of strengths and weaknesses
- Consider statistical significance of differences
- Plot performance across different capability domains
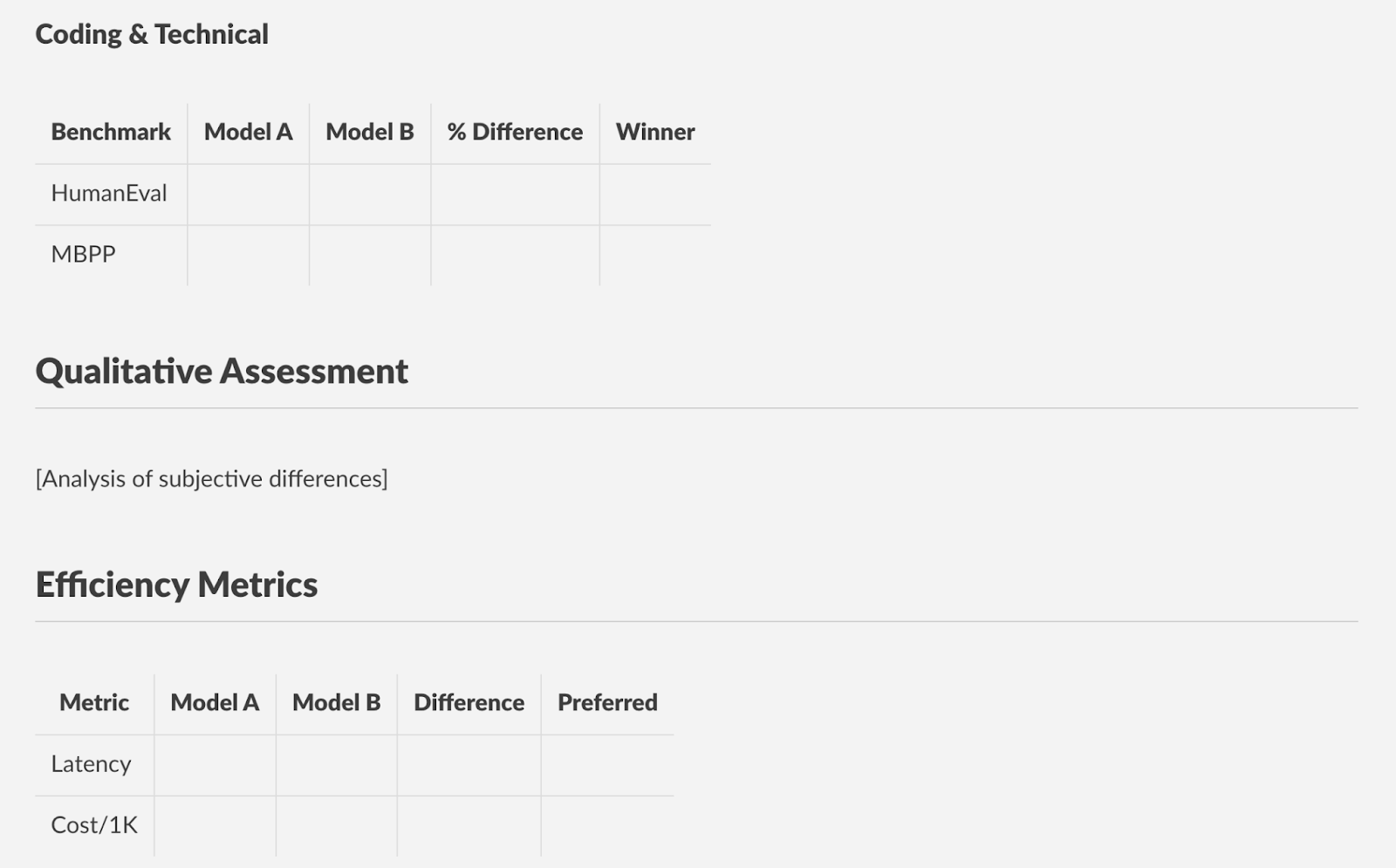
Step 8: Document and Visualize Findings
Create clear, scannable documentation of your results:
Documentation Template

Step 9: Consider Trade-offs
Look beyond raw performance to make a holistic assessment:
Key Trade-off Factors
- Cost vs. performance – is the improvement worth the price?
- Speed vs. accuracy – do you need real-time responses?
- Context window – can it handle your document lengths?
- Specialized knowledge – does it excel in your domain?
- API reliability – is the service stable and well-supported?
- Data privacy – how is your data handled?
- Update frequency – how often is the model improved?
Pro Tip: Create a weighted decision matrix that factors in all relevant considerations.
Step 10: Make an Informed Decision
Translate your evaluation into action:
Final Decision Process
- Rank models based on performance in priority areas
- Calculate total cost of ownership over expected usage period
- Consider implementation effort and integration requirements
- Pilot test the leading candidate with a subset of users or data
- Establish ongoing evaluation processes for monitoring performance
- Document your decision rationale for future reference
The post How to Compare Two LLMs in Terms of Performance: A Comprehensive Web Guide for Evaluating and Benchmarking Language Models appeared first on MarkTechPost.
Source: Read MoreÂ

