




Understanding different data types like text, images, videos, and audio in one model is a big challenge. Large language models that handle all these together struggle to match the performance of models designed for just one type. Training such models is difficult because different data types have different patterns, making it hard to balance accuracy across tasks. Many models fail to properly align information from various inputs, slowing responses and requiring large amounts of data. These issues make it difficult to create a truly effective model that can understand all data types equally well.
Currently, models focus on specific tasks like recognizing images, analyzing videos, or processing audio separately. Some models try to combine these tasks, but their performance remains much weaker than specialized models. Vision-language models are improving and now process videos, 3D content, and mixed inputs, but integrating audio properly remains a major issue. Large audio-text models attempt to connect speech with language models, but understanding complex audio, like music and events, remains underdeveloped. Newer omni-modal models try to handle multiple data types but struggle with poor performance, unbalanced learning, and inefficient data handling.
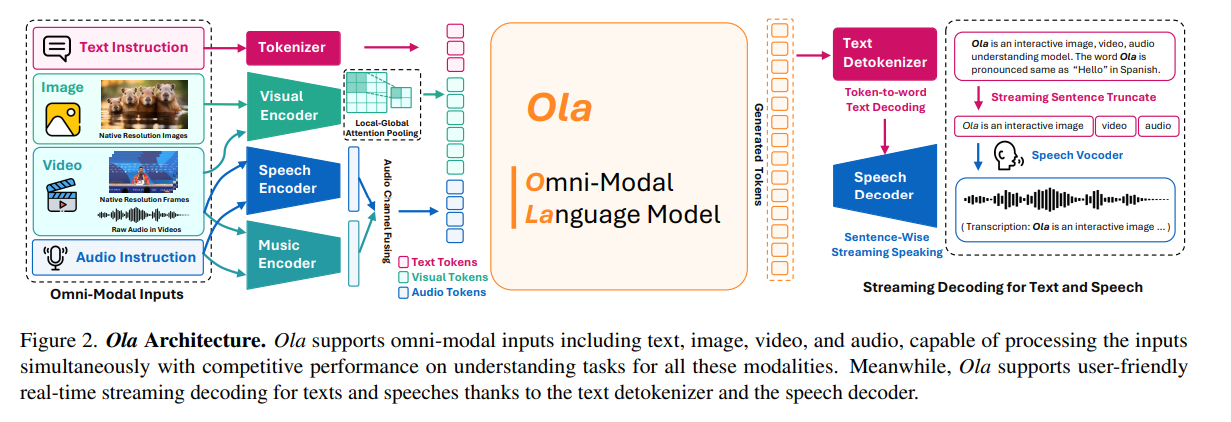
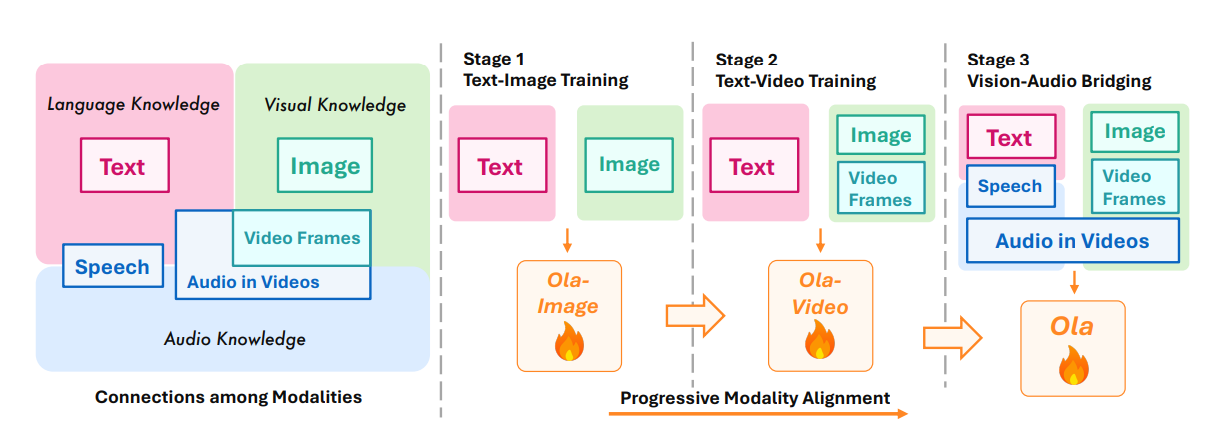
To solve this, researchers from Tsinghua University, Tencent Hunyuan Research, and S-Lab, NTU proposed Ola, an Omni–modal model designed to understand and generate multiple data modalities, including text, speech, images, videos, and audio. The framework is built on a modular architecture where each modality has a dedicated encoder—text, images, videos, and audio—responsible for processing its respective input. These encoders map their data into a unified representational space, allowing a central Large Language Model (LLM) to interpret and generate responses across different modalities. For audio, Ola employs a dual encoder approach that separately processes speech and music features before integrating them into the shared representation. Vision inputs maintain their original aspect ratios using OryxViT, ensuring minimal distortion during processing. The model incorporates a Local-Global Attention Pooling layer to increase efficiency, which compresses token length without losing critical features, maximizing computation without losing performance. Lastly, speech synthesis is handled by an external text-to-speech decoder, supporting real-time streaming output.
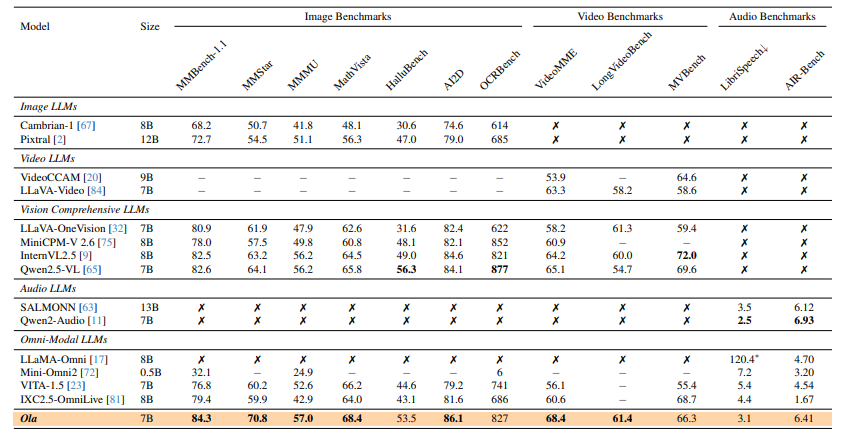
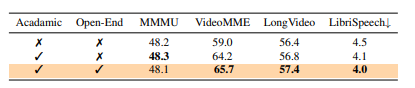
Researchers conducted comprehensive benchmarking across image, video, and audio understanding benchmarks to evaluate the framework. Ola builds upon Qwen-2.5-7B, integrating OryxViT as the vision encoder, Whisper-V3-Large as the speech encoder, and BEATs-AS2M(cpt2) as the music encoder. The training used a high learning rate of 1e-3 for MLP adapter pre-training, reduced to 2e-5 for text-image training and 1e-5 for video-audio training, with a batch size of 256 over 64 NVIDIA A800 GPUs. Extensive evaluations demonstrated Ola’s capabilities across multiple benchmarks, including MMBench-1.1, MMStar, VideoMME, and AIR-Bench, where it outperformed existing omni-modal LLMs. In audio benchmarks, Ola achieved a 1.9% WER on the test-clean subset of LibriSpeech and a 6.41 average score on AIR-Bench, surpassing previous omni-modal models and approaching the performance of specialized audio models. Further analysis highlighted Ola’s cross-modal learning benefits, showing that joint training with video-audio data improved speech recognition performance. Ola’s training strategies were analyzed, demonstrating performance gains in omni-modal learning, cross-modal video-audio alignment, and progressive modality learning.

Ultimately, the proposed model successfully combines text, image, video, and audio information through a progressive modality alignment approach with remarkable performance on various benchmarks. Its architectural innovations, effective training methods, and high-quality cross-modal data preparation overcome the weaknesses of earlier models and present the capabilities of omni-modal learning. Ola’s structure and training process can be used as a baseline in future studies, influencing development in more general AI models. Future work can build on Ola’s foundation to improve omni-modal understanding and application by refining cross-modal alignment and expanding data diversity.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.

The post Ola: A State-of-the-Art Omni-Modal Understanding Model with Advanced Progressive Modality Alignment Strategy appeared first on MarkTechPost.
Source: Read MoreÂ
