




Large Language Models (LLMs) have gained significant importance as productivity tools, with open-source models increasingly matching the performance of their closed-source counterparts. These models operate through Next Token Prediction, where tokens are predicted in sequence when computing attention is between each token and its predecessors. Key-value (KV) pairs are cached to prevent redundant calculations and optimize this process. However, the increasing memory requirements for caching pose substantial limitations, particularly evident in models like LLaMA-65B, which requires over 86GB of GPU memory to store 512K tokens with 8-bit key-value quantization, exceeding even high-capacity GPUs like the H100-80GB.
Existing approaches have emerged to address the memory footprint challenges of KV cache in LLMs, each having its own advantages and disadvantages. Linear attention methods like Linear Transformer, RWKV, and Mamba provide linear scaling with sequence length. Dynamic token pruning approaches such as LazyLLM, A2SF, and SnapKV remove less important tokens, while head dimension reduction techniques like SliceGPT and Sheared focus on reducing attention heads. Methods for sharing KV representations across layers, including YONO and MiniCache, and quantization techniques like GPTQ and KVQuant, attempt to optimize memory usage. However, these approaches consistently face trade-offs between computational efficiency and model performance, often sacrificing essential information or attention patterns.
Researchers from Peking University, and Xiaomi Corp., Beijing have proposed TransMLA, a post-training method that converts widely used GQA-based pre-trained models into MLA-based models. Their research provides theoretical proof that Multi-Layer Attention (MLA) delivers superior expressive power compared to Grouped-Query Attention (GQA) while maintaining the same KV Cache overhead. The team has successfully converted several prominent GQA-based models, including LLaMA-3, Qwen-2.5, Mistral, Mixtral, Gemma-2, and Phi-4, into equivalent MLA models. This transformation aims to revolutionize mainstream LLM attention design by offering a resource-efficient migration strategy that improves model performance while reducing computational costs and environmental impact.
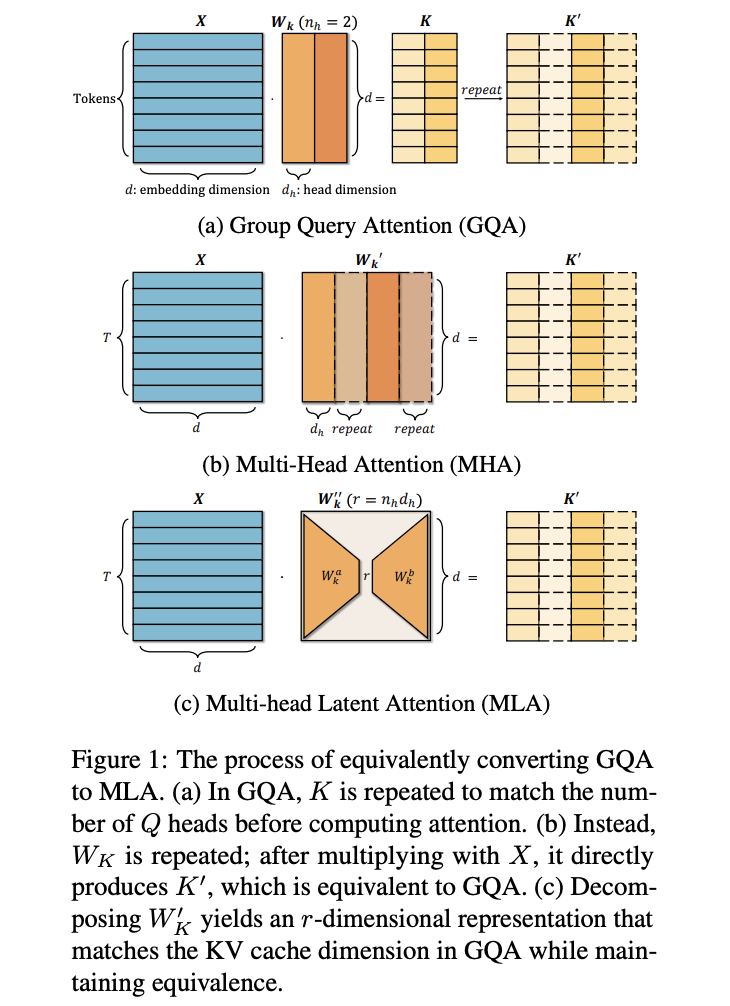
The transformation from GQA to MLA models is shown using the Qwen2.5 framework. In the original Qwen2.5-7B model, each layer contains 28 query heads and 4 key/value heads, with individual head dimensions of 128 and a KV cache dimension of 1024. The conversion to MLA involves adjusting the output dimensions of two weight matrices to 512 while maintaining the KV cache dimension at 1024. The key innovation lies in the TransMLA approach, which projects the weight matrix dimensions from 512 to 3584, enabling all 28 query heads to interact with distinct queries. This transformation substantially enhances the model’s expressive power while keeping the KV cache size constant and adding only a modest 12.5% increase in parameters for both QK and V-O pairs.
The performance evaluation of the TransMLA model shows significant improvements over the original GQA-based architecture. Using the SmolTalk instruction fine-tuning dataset, the TransMLA model achieves lower training loss, indicating enhanced data fitting capabilities. Performance improvements are seen mostly in math and code tasks across both 7B and 14B model configurations. The research investigated the source of these improvements through controlled experiments. When testing with simple dimensionality expansion using identity map initialization without orthogonal decomposition on the GSM8K dataset, the improvement is minimal (0.15%), confirming that the substantial performance gains come from the combination of enlarged KV dimensions and orthogonal decomposition.
In conclusion, researchers present a significant advancement in LLM architecture by introducing TransMLA, an approach to convert used GQA-based pre-trained models into MLA-based models. The theoretical proofs and empirical validation establish the successful transformation with enhanced performance characteristics. This work bridges a critical gap between GQA and MLA architectures in existing research through comprehensive theoretical and experimental comparisons. Moreover, Future developments can focus on extending this transformation approach to major large-scale models like LLaMA, Qwen, and Mistral, with additional optimization through DeepSeek R1 distillation techniques to improve model performance.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)
Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)The post TransMLA: Transforming GQA-based Models Into MLA-based Models appeared first on MarkTechPost.
Source: Read MoreÂ

