




Machines learn to connect images and text by training on large datasets, where more data helps models recognize patterns and improve accuracy. Vision-language models (VLMs) rely on these datasets to perform tasks like image captioning and visual question answering. The question is whether increasing datasets to 100 billion examples dramatically improves accuracy, cultural diversity, and support for low-resource languages. Scaling beyond 10 billion has slowed down, and doubts are raised about whether there will be further benefits. With such enormous data come quality control problems, bias, and computational constraints.
Currently, vision-language models depend on massive datasets such as Conceptual Captions and LAION, with millions to billions of image-text pairs. These datasets enable zero-shot classification and image captioning, but their advancement has slowed to around 10 billion pairs. This constraint minimizes the prospect of further refining model accuracy, inclusivity, and multilingual comprehension. Existing approaches are based on web-crawled data, which poses issues like low-quality samples, linguistic biases, and underrepresentation of multiculturalism. The efficiency of further scaling is questionable beyond this point, bringing into question the ability of increased dataset size alone to produce substantial improvements.
To mitigate limitations in cultural diversity and multilinguality in vision-language models, researchers from Google Deepmind proposed WebLI-100B, a dataset containing 100 billion image-text pairs, which is ten times larger than previous datasets. This dataset captures rare cultural concepts and improves model performance in less-explored areas like low-resource languages and diverse representations. Unlike prior datasets, WebLI-100B focuses on scaling data instead of relying on heavy filtering, which often removes important cultural details. The framework involves pre-training models on different subsets of the WebLI-100B dataset (1B, 10B, and 100B) to analyze the impact of data scaling. Models trained on the full dataset performed better in cultural and multilingual tasks than those trained on smaller datasets, even when using the same computational resources. Instead of aggressive filtering, the dataset maintains a broad representation of languages and cultural elements, making it more inclusive.
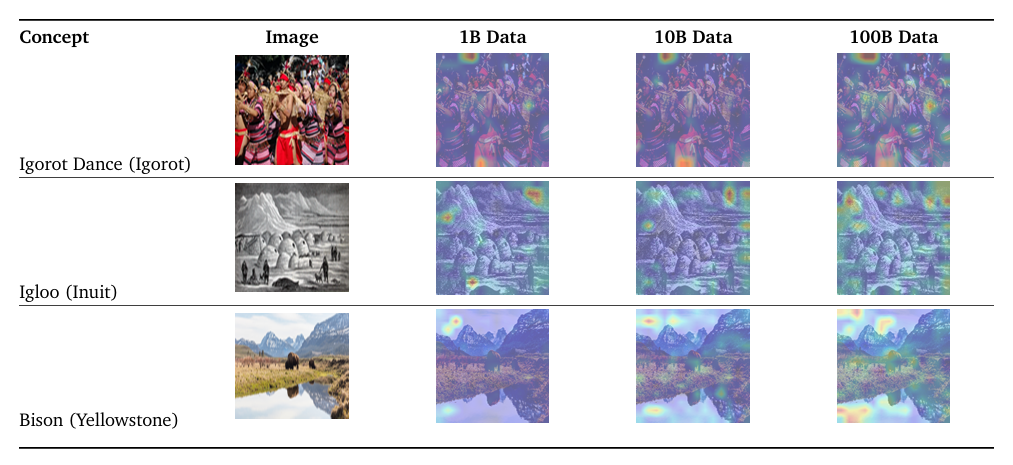
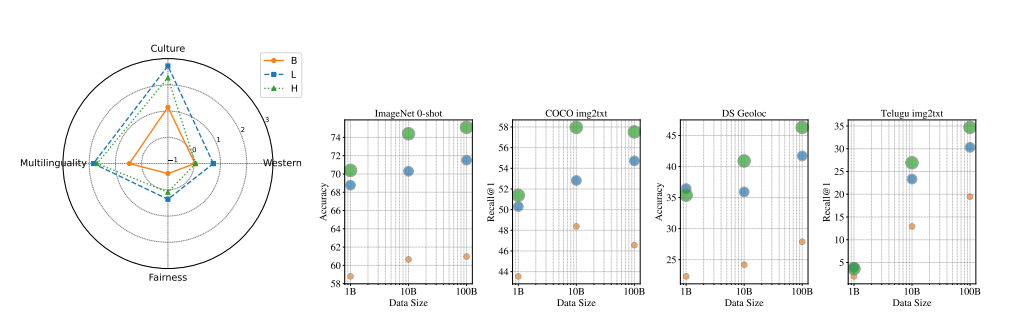
Researchers created a quality-filtered 5B dataset and a language-rebalanced version to upsample low-resource languages. Using the SigLIP model, they trained on different dataset sizes (1B, 10B, and 100B) with ViT architectures and a contrastive learning approach. The evaluation covered zero-shot and few-shot classification tasks such as ImageNet, CIFAR–100, and COCO Captions, cultural diversity benchmarks like Dollar Street and GeoDE, and multilingual retrieval using Crossmodal-3600. Results indicated that increasing the dataset size from 10B to 100B had minimal impact on Western-centric benchmarks but led to improvements in cultural diversity tasks and low-resource language retrieval. Bias analysis revealed persistent gender-related representation and association biases despite performance disparity improving alongside diversity gains. Finally, researchers assessed model transferability to generative tasks using PaliGemma, testing frozen and unfrozen settings for downstream vision-language applications.
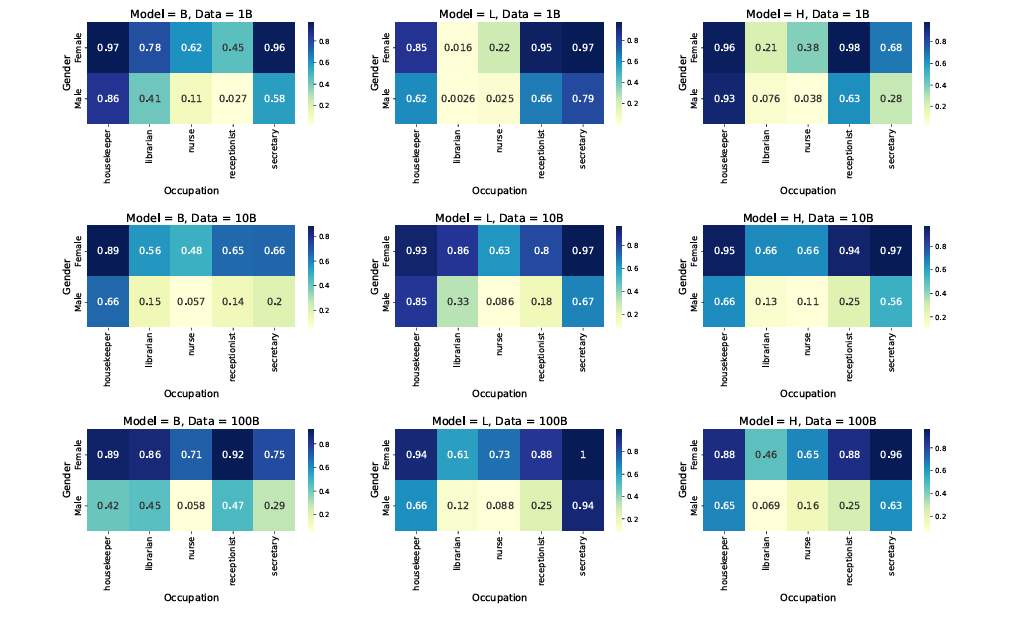
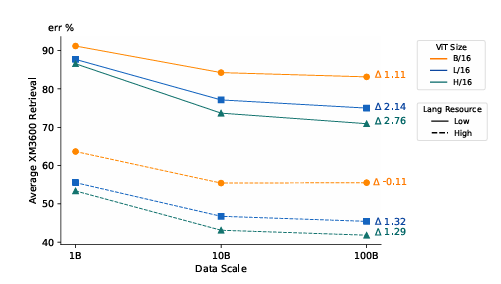
In conclusion, scaling vision-language pre-training datasets to 100 billion image-text pairs improved inclusivity by enhancing cultural diversity and multilinguality, and reducing performance disparity across subgroups, even though traditional benchmarks showed limited gains. While quality filters like CLIP improved performance on standard tasks, they often reduced data diversity. This work can serve as a reference for future research by stimulating the creation of filtering algorithms that maintain diversity and training strategies that promote inclusivity without needing extra data and informing future improvements on balancing performance, diversity, and fairness in vision-language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)
Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)The post Google DeepMind Research Introduces WebLI-100B: Scaling Vision-Language Pretraining to 100 Billion Examples for Cultural Diversity and Multilingualit appeared first on MarkTechPost.
Source: Read MoreÂ

