




Developing AI systems that learn from their surroundings during execution involves creating models that adapt dynamically based on new information. In-Context Reinforcement Learning (ICRL) follows this approach by allowing AI agents to learn through trial and error while making decisions. However, this method has significant challenges when applied to complex environments with various tasks. It works effectively in simple cases but fails to scale to more complex ones since adapting across different domains depends on how well an agent generalizes from past experiences. These systems fail to work in the real world without proper upgrades in current scenarios and limit their practical application.
Currently, pre-training methods for cross-domain action models follow two main approaches. One approach uses all available data and conditions policies on return-to-go targets, while the other relies on expert demonstrations but ignores reward signals. These methods struggle with scaling to diverse tasks and complex environments. The first approach depends on predicting future rewards, which becomes unreliable in unpredictable settings. The second approach focuses on imitating expert actions but lacks adaptability since it does not use real-time feedback. Both methods fail to generalize well across domains, making them less effective for real-world applications.
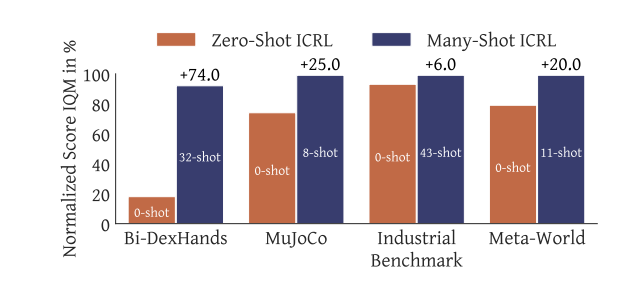
To address these issues, researchers from Dunnolab AI proposed Vintix, a model leveraging Algorithm Distillation for in-context reinforcement learning. Unlike conventional reinforcement learning methods that rely on pre-trained policies or fine-tuning, Vintix employs a decoder-only transformer for next-action prediction, trained on learning histories from base RL algorithms. The model incorporates Continuous Noise Distillation (ADϵ), where noise is gradually reduced in action selection and cross-domain training, utilizing data from 87 tasks across four benchmarks: MuJoCo, Meta-World, Bi-DexHands, and Industrial-Benchmark. This enables Vintix to generalize across diverse environments while refining policies dynamically.
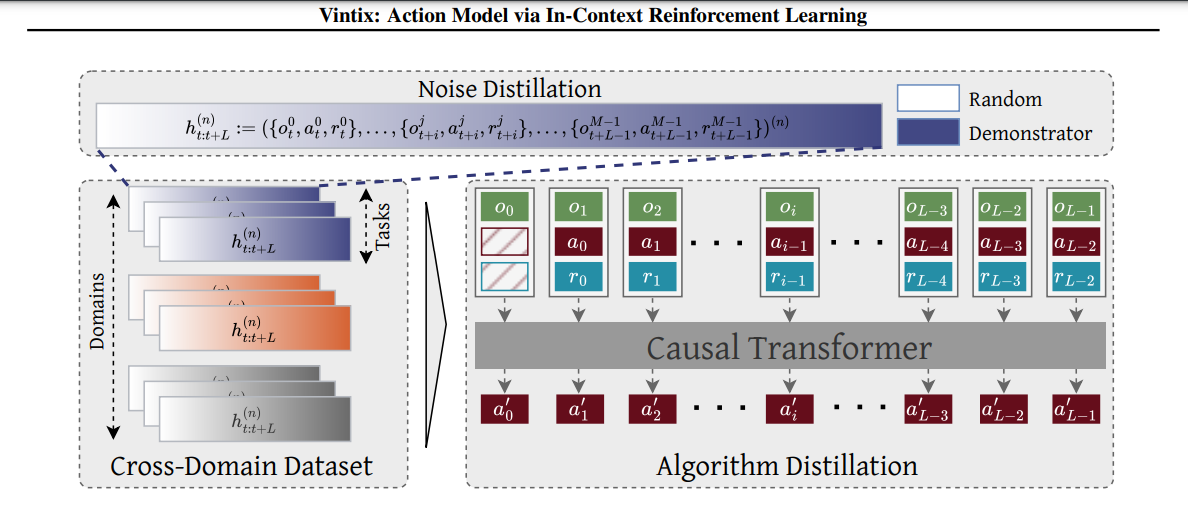
The framework comprises a 300M–parameter model with 24 layers and a transformer backbone (TinyLLama). It processes input sequences using an optimized tokenization strategy to expand context length. Training is conducted on 8 H100 GPUs, optimizing with MSE loss. At inference, the model starts without prior context but dynamically self-improves over time. Results demonstrated gradual policy refinement and strong cross-domain generalization, highlighting the effectiveness of in-context learning for reinforcement learning tasks.
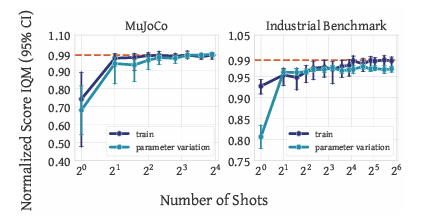
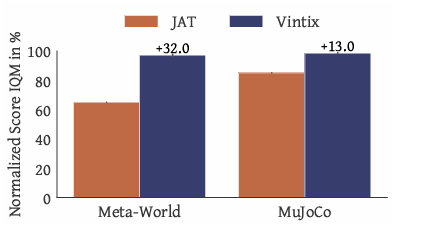
Researchers assessed Vintix’s inference-time self-correction, comparing it to related models and analyzing generalization. On training tasks, Vintix improved through self-correction, reaching near-demonstrator performance. It outperformed JAT by +32.1% in Meta-World and +13.5% in MuJoCo, benefiting from Algorithm Distillation. On unseen parametric variations like viscosity and gravity in MuJoCo and new setpoints in Industrial-Benchmark, near-demonstrator performance was maintained but required more iterations. However, in entirely new tasks, it achieved 47% on Meta-World’s Door-Unlock and 31% on Bi-DexHands’ Door–Open–Inward. Still, it struggled with Bin-Picking and Hand-Kettle, highlighting adaptability in familiar settings but limitations in generalization.
In the end, the proposed method by researchers utilized In–Context Reinforcement Learning and Algorithm Distillation to enhance adaptability across domains without updating gradients at test time. The distillation of continuous noise simplified data collection and allowed for self-correction. While promising, challenges remained in expanding domains and improving generalization. This work can be a baseline for future research in scalable, reward-driven reinforcement learning and autonomous decision-making systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)
Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)The post Vintix: Scaling In-Context Reinforcement Learning for Generalist AI Agents appeared first on MarkTechPost.
Source: Read MoreÂ

