




Large language models (LLMs) struggle with precise computations, symbolic manipulations, and algorithmic tasks, often requiring structured problem-solving approaches. While language models demonstrate strengths in semantic understanding and common sense reasoning, they are not inherently equipped to handle operations that demand high levels of precision, such as mathematical problem-solving or logic-based decision-making. Traditional approaches attempt to compensate for these weaknesses by integrating external tools but lack a systematic way to determine when to rely on symbolic computing versus textual reasoning.
Researchers have identified a fundamental limitation in existing large language models (LLMs): their inability to switch between textual reasoning and code execution effectively. This issue arises because most input prompts do not explicitly indicate whether a problem is best solved using natural language or symbolic computation. While some models, such as OpenAI’s GPT series, incorporate features like code interpreters to address this, they fail to effectively guide the transition between text and code-based solutions. The challenge is not only about executing code but also about knowing when to generate code in the first place. LLMs often default to text-based reasoning without this ability, leading to inefficiencies and incorrect solutions in complex problem-solving scenarios.

Some models have incorporated external frameworks to assist LLMs in generating and executing code to address this. These include OpenAI’s Code Interpreter and multi-agent frameworks like AutoGen, which use specialized prompts to steer models toward appropriate responses. However, these approaches fail to efficiently leverage symbolic computation, as they do not systematically fine-tune LLMs to balance code execution with natural language reasoning. Existing methods provide limited adaptability, often requiring manual intervention or domain-specific tuning. As a result, models continue to perform sub-optimally on tasks that demand a hybrid of text and code-based problem-solving.
Researchers from the Massachusetts Institute of Technology (MIT), Harvard University, the University of Illinois Urbana-Champaign, and the MIT-IBM Watson AI Lab have introduced a novel framework called CodeSteer, designed to guide LLMs in effectively switching between text-based reasoning and symbolic computing. CodeSteer fine-tunes language models to optimize code generation and textual reasoning. The approach utilizes a newly developed benchmark called SymBench, which comprises 37 symbolic tasks, enabling researchers to measure and refine the model’s ability to handle structured problem-solving. The framework integrates a fine-tuned version of the Llama-3-8B model with multi-round supervised fine-tuning (SFT) and direct preference optimization (DPO), making it highly adaptable across various problem domains.
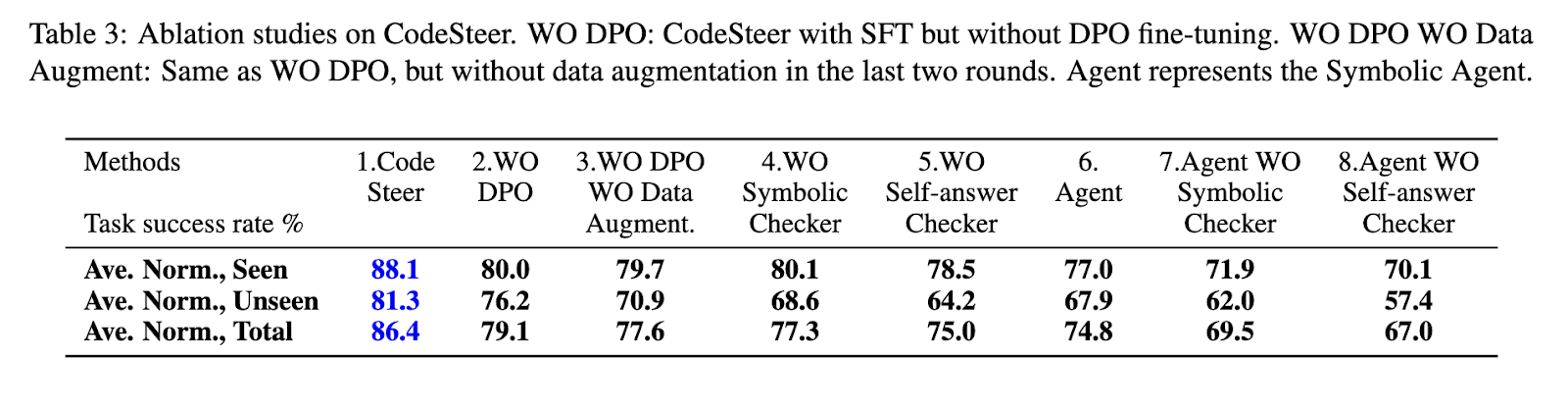
The CodeSteer framework introduces a multi-step methodology to enhance the reasoning capabilities of LLMs. The first step involves the development of SymBench, a benchmark containing symbolic reasoning tasks such as mathematical problem-solving, logical deduction, and optimization. CodeSteer uses this dataset to generate a synthetic collection of 12,000 multi-round guidance/generation trajectories and 5,500 guidance comparison pairs. Next, the researchers employ multi-round supervised fine-tuning and direct preference optimization on the Llama-3-8B model, allowing it to adjust its decision-making approach dynamically. The framework is further enhanced by adding a symbolic checker and a self-answer checker, which verify the correctness and efficiency of generated solutions. These mechanisms ensure that models do not rely solely on text-based reasoning when code execution is the more effective approach.
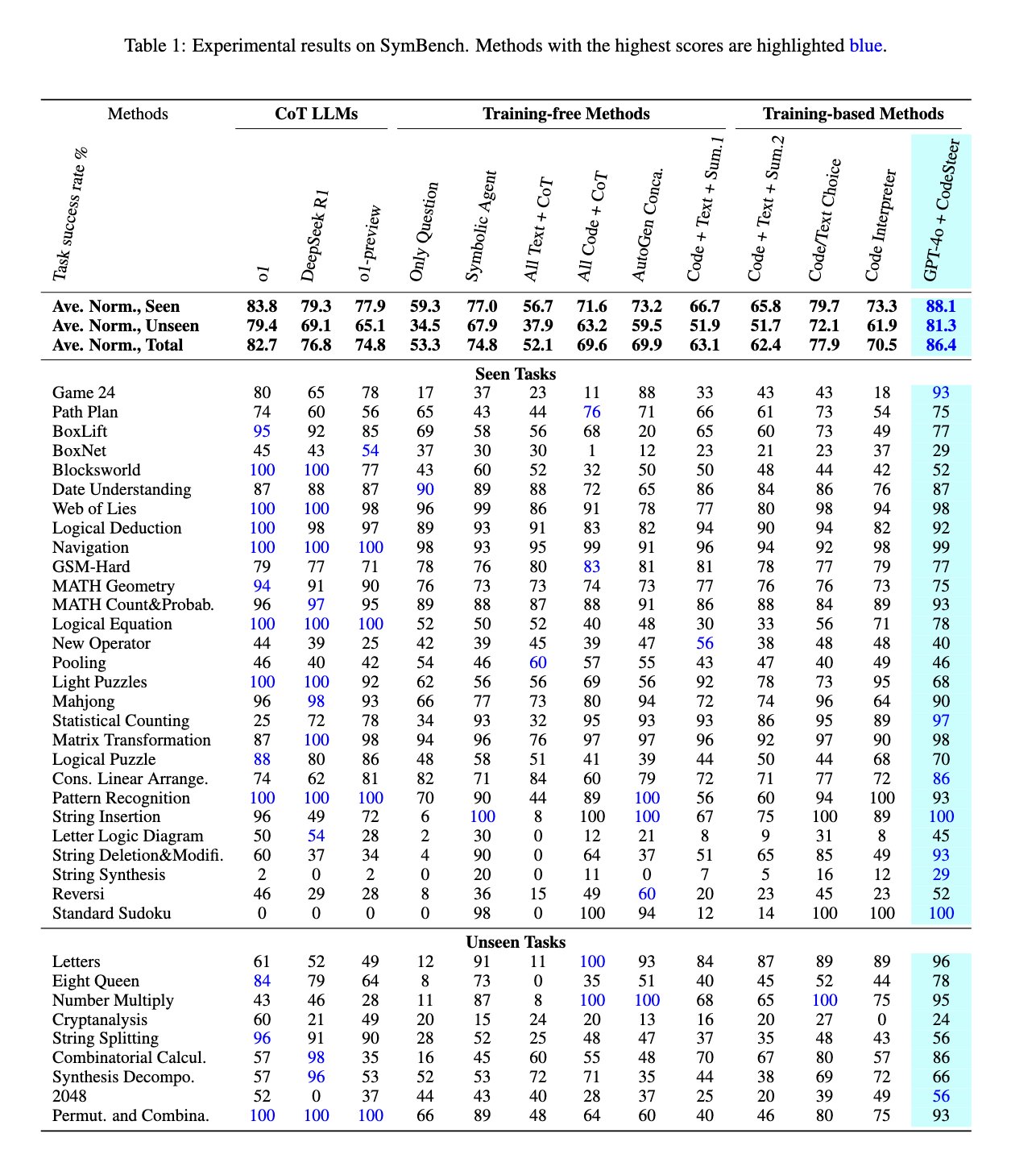
Performance evaluations of CodeSteer demonstrate substantial improvements over existing LLMs. When integrated with GPT-4o, the framework increased the model’s average performance score from 53.3 to 86.4 across 37 symbolic tasks. It also outperformed OpenAI’s o1 model, which scored 82.7, and DeepSeek R1, which scored 76.8. CodeSteer consistently demonstrated a 41.8% improvement in evaluations involving unseen tasks over the Claude-3-5-Sonnet, Mistral-Large, and GPT-3.5 models. By leveraging symbolic computing, CodeSteer enables LLMs to maintain high performance even on highly complex problem-solving tasks. The benchmark results indicate that the framework enhances accuracy and reduces inefficiencies associated with text-based iterative reasoning.

The research highlights the importance of guiding LLMs in determining when to use symbolic computing versus natural language reasoning. The proposed framework successfully overcomes the limitations of existing models by introducing a structured, multi-round approach to decision-making. With CodeSteer, researchers have developed a system that significantly enhances the effectiveness of large language models, making them more reliable in handling complex problem-solving tasks. By integrating symbolic computing more effectively, this research marks a critical step forward in improving AI-driven reasoning and planning.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)
Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)The post This AI Paper Introduces CodeSteer: Symbolic-Augmented Language Models via Code/Text Guidance appeared first on MarkTechPost.
Source: Read MoreÂ

