




Large language models (LLMs) have demonstrated proficiency in solving complex problems across mathematics, scientific research, and software engineering. Chain-of-thought (CoT) prompting is pivotal in guiding models through intermediate reasoning steps before reaching conclusions. Reinforcement learning (RL) is another essential component that enables structured reasoning, allowing models to recognize and correct errors efficiently. Despite these advancements, the challenge remains in extending CoT lengths while maintaining accuracy, particularly in specialized domains where structured reasoning is critical.
A key issue in enhancing reasoning abilities in LLMs lies in generating long and structured chains of thought. Existing models struggle with high-complexity tasks that require iterative reasoning, such as PhD-level scientific problem-solving and competitive mathematics. Simply scaling the model size and training data does not guarantee improved CoT capabilities. Furthermore, RL-based training demands precise reward shaping, as improper reward mechanisms can result in counterproductive learning behaviors. The research aims to identify the fundamental factors influencing CoT emergence and design optimal training strategies to stabilize and improve long-chain reasoning.
Previously, researchers have employed supervised fine-tuning (SFT) and reinforcement learning to enhance CoT reasoning in LLMs. SFT is commonly used to initialize models with structured reasoning examples, while RL is applied to fine-tune and extend reasoning capabilities. However, traditional RL approaches lack stability when increasing CoT length, often leading to inconsistent reasoning quality. Verifiable reward signals, such as ground-truth accuracy, are critical for preventing models from engaging in reward hacking, where the model learns to optimize for rewards without genuinely improving reasoning performance. Despite these efforts, current training methodologies lack a systematic approach to effectively scaling and stabilizing long CoTs.
Researchers from Carnegie Mellon University and IN.AI introduced a comprehensive framework to analyze and optimize long CoT reasoning in LLMs. Their approach focused on determining the underlying mechanics of long-chain reasoning, experimenting with various training methodologies to assess their impact. The team systematically tested SFT and RL techniques, emphasizing the importance of structured reward shaping. A novel cosine length-scaling reward with a repetition penalty was developed to encourage models to refine their reasoning strategies, such as branching and backtracking, leading to more effective problem-solving processes. Further, the researchers explored incorporating web-extracted solutions as verifiable reward signals to enhance the learning process, particularly for out-of-distribution (OOD) tasks like STEM problem-solving.
The training methodology involved extensive experimentation with different base models, including Llama-3.1-8B and Qwen2.5-7B-Math, each representing general-purpose and mathematics-specialized models, respectively. The researchers used a dataset of 7,500 training sample prompts from MATH, ensuring access to verifiable ground-truth solutions. Initial training with SFT provided the foundation for long CoT development, followed by RL optimization. A rule-based verifier was employed to compare generated responses with correct answers, ensuring stability in the learning process. The team introduced a repetition penalty mechanism to refine reward shaping further, discouraging models from producing redundant reasoning paths while incentivizing efficient problem-solving. The team also analyzed data extracted from web corpora, assessing the potential of noisy but diverse supervision signals in refining CoT length scaling.

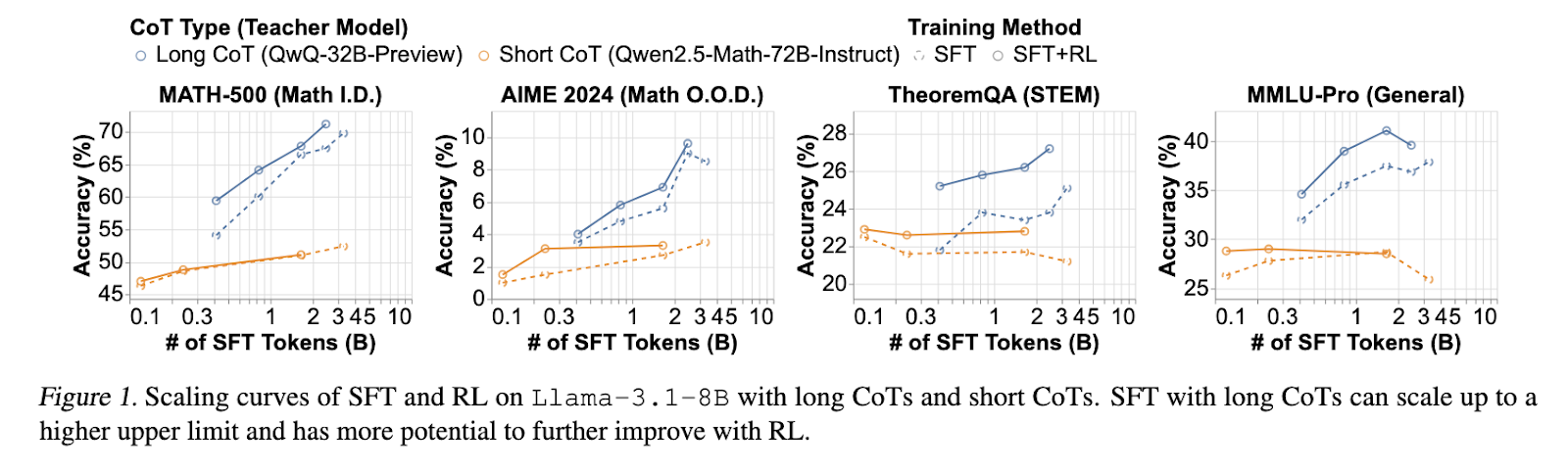
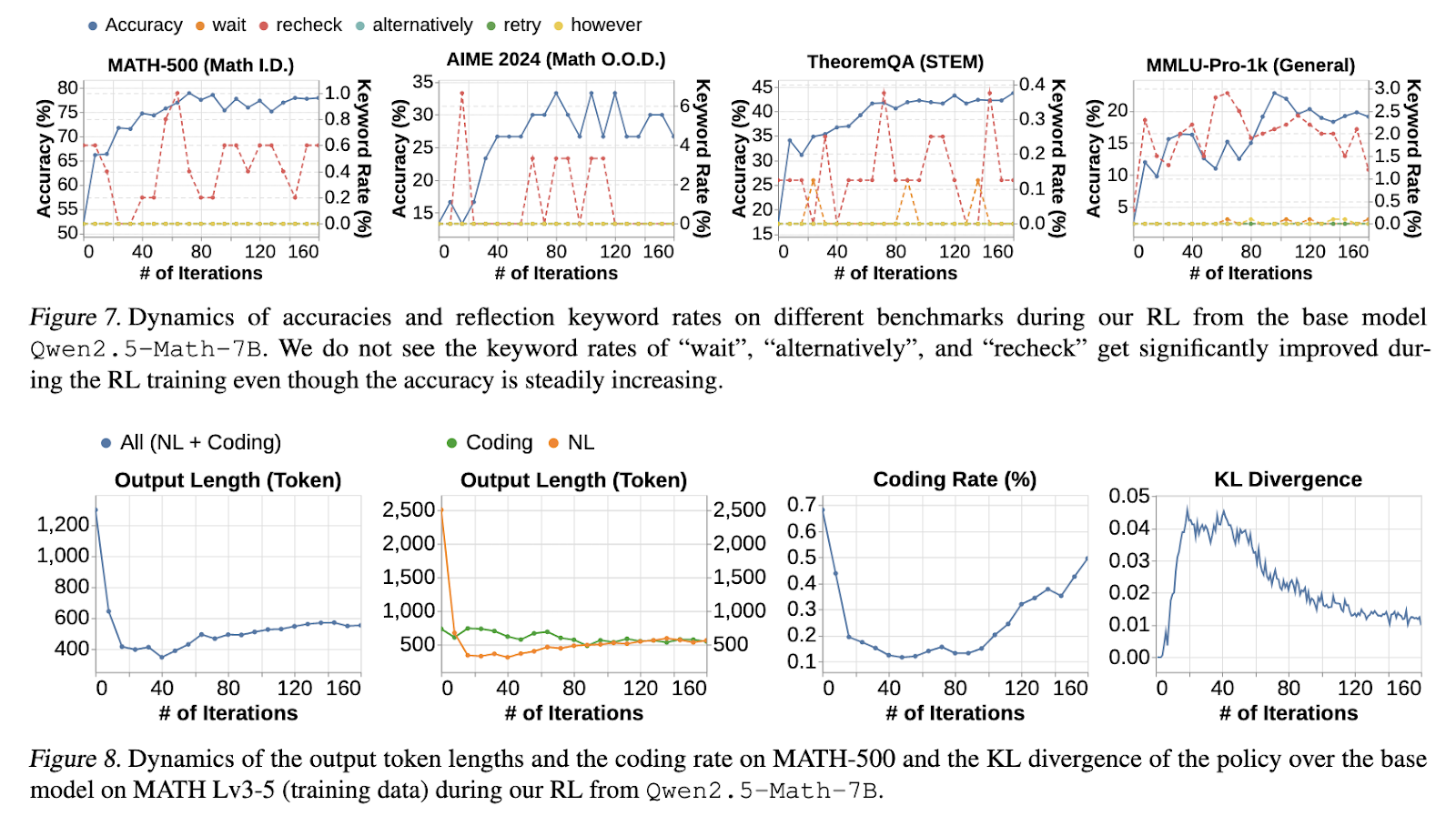
The research findings revealed several critical insights into long CoT reasoning. Models trained with long CoT SFT consistently achieved superior accuracy than those initialized with short CoT SFT. On the MATH-500 benchmark, long CoT SFT models saw a significant improvement, with accuracy exceeding 70%, while short CoT SFT models stagnated below 55%. RL fine-tuning further enhanced long CoT models, providing an additional 3% absolute accuracy gain. The introduction of the cosine length-scaling reward proved effective in stabilizing reasoning trajectories, preventing excessive or unstructured CoT growth. Moreover, models incorporating filtered web-extracted solutions demonstrated improved generalization capabilities, particularly in OOD benchmarks such as AIME 2024 and TheoremQA, where accuracy gains of 15-50% were recorded. The research also confirmed that core reasoning skills, such as error validation and correction, are inherently present in base models. Still, effective RL training is necessary to reinforce these abilities efficiently.
The study significantly advances understanding and optimizing long CoT reasoning in LLMs. The researchers successfully identified key training factors that enhance structured reasoning, emphasizing the importance of supervised fine-tuning, verifiable reward signals, and carefully designed reinforcement learning techniques. The findings highlight the potential for further research in refining RL methodologies, optimizing reward-shaping mechanisms, and leveraging diverse data sources to enhance model reasoning capabilities. The study’s contributions offer valuable insights for the future development of AI models with robust, interpretable, and scalable reasoning abilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)
Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)The post This AI Paper Explores Long Chain-of-Thought Reasoning: Enhancing Large Language Models with Reinforcement Learning and Supervised Fine-Tuning appeared first on MarkTechPost.
Source: Read MoreÂ
