




Open-vocabulary object detection (OVD) aims to detect arbitrary objects with user-provided text labels. Although recent progress has enhanced zero-shot detection ability, current techniques handicap themselves with three important challenges. They heavily depend on expensive and large-scale region-level annotations, which are hard to scale. Their captions are typically short and not contextually rich, which makes them inadequate in describing relationships between objects. These models also lack strong generalization to new object categories, mainly aiming to align individual object features with textual labels instead of using holistic scene understanding. Overcoming these limitations is essential to pushing the field further and developing more effective and versatile vision-language models.
Previous methods have tried to enhance OVD performance by making use of vision-language pretraining. Models such as GLIP, GLIPv2, and DetCLIPv3 combine contrastive learning and dense captioning approaches to promote object-text alignment. However, these techniques still have important issues. Region-based captions only describe a single object without considering the entire scene, which confines contextual understanding. Training involves enormous labeled datasets, so scalability is an important issue. Without a way to understand comprehensive image-level semantics, these models are incapable of detecting new objects efficiently.

Researchers from Sun Yat-sen University, Alibaba Group, Peng Cheng Laboratory, Guangdong Province Key Laboratory of Information Security Technology, and Pazhou Laboratory propose LLMDet, a novel open-vocabulary detector trained under the supervision of a large language model. This framework introduces a new dataset, GroundingCap-1M, which consists of 1.12 million images, each annotated with detailed image-level captions and short region-level descriptions. The integration of both detailed and concise textual information strengthens vision-language alignment, providing richer supervision for object detection. To enhance learning efficiency, the training strategy employs dual supervision, combining a grounding loss that aligns text labels with detected objects and a caption generation loss that facilitates comprehensive image descriptions alongside object-level captions. A large language model is incorporated to generate long captions describing entire scenes and short phrases for individual objects, improving detection accuracy, generalization, and rare-class recognition. Additionally, this approach contributes to multi-modal learning by reinforcing the interaction between object detection and large-scale vision-language models.
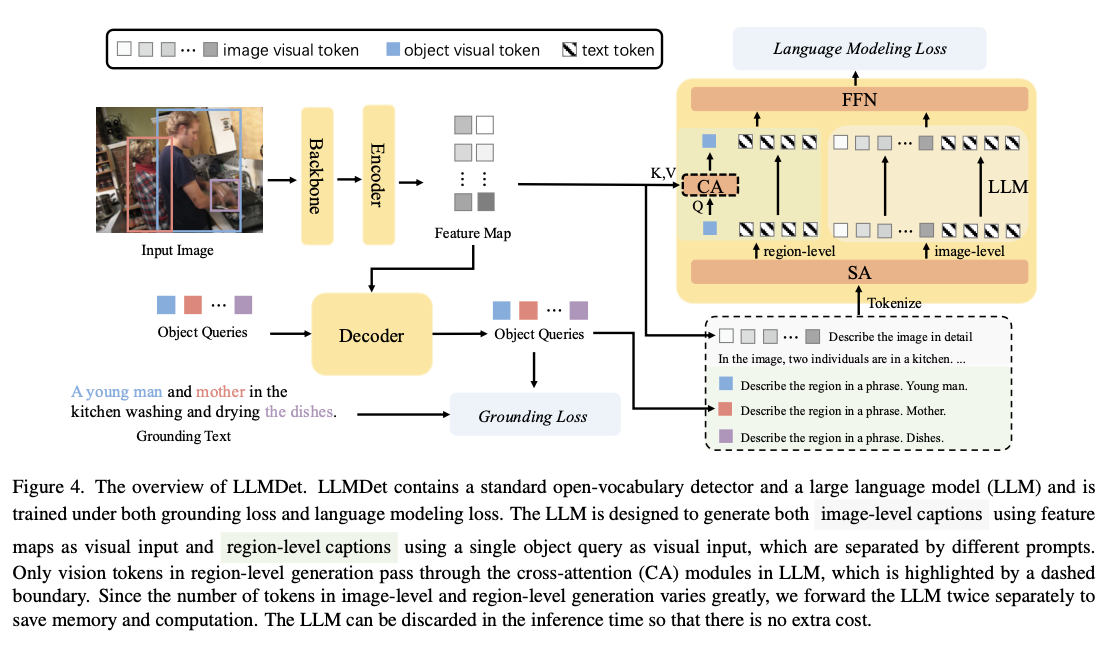
The training pipeline consists of two primary stages. First, a projector is optimized to align the object detector’s visual features with the feature space of the large language model. In the next stage, the detector undergoes joint fine-tuning with the language model using a combination of grounding and captioning losses. The dataset used for this training process is compiled from COCO, V3Det, GoldG, and LCS, ensuring that each image is annotated with both short region-level descriptions and extensive long captions. The architecture is built on the Swin Transformer backbone, utilizing MM-GDINO as the object detector while integrating captioning capabilities through large language models. The model processes information at two levels: region-level descriptions categorize objects, while image-level captions capture scene-wide contextual relationships. Despite incorporating an advanced language model during training, computational efficiency is maintained as the language model is discarded during inference.
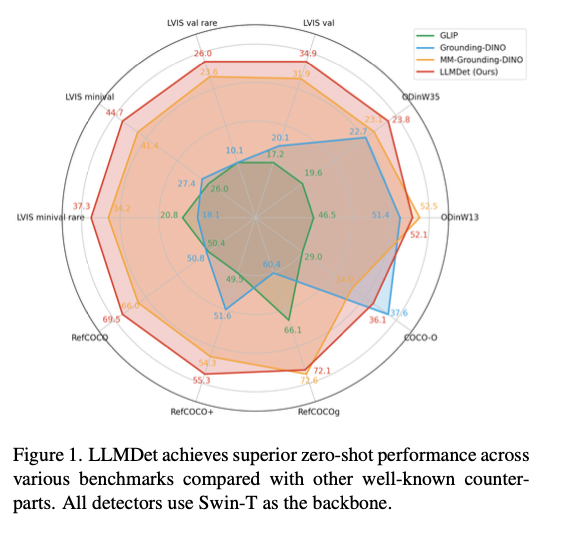
This approach attains state-of-the-art performance over a range of open-vocabulary object detection benchmarks, with greatly improved detection accuracy, generalization, and robustness. It surpasses prior models by 3.3%–14.3% AP on LVIS, with clear improvement in the identification of rare classes. On ODinW, a benchmark for object detection over a range of domains, it shows better zero-shot transferability. Robustness to domain transition is also confirmed through its improved performance on COCO-O, a dataset measuring performance under natural variations. In referential expression comprehension tasks, it attains the best accuracy on RefCOCO, RefCOCO+, and RefCOCOg, affirming its capacity for textual description alignment with object detection. Ablation experiments show that image-level captioning and region-level grounding in combination make significant contributions to performance, especially in object detection for rare objects. As well, incorporating the learned detector into multi-modal models improves vision-language alignment, suppresses hallucinations, and advances accuracy in visual question-answering.
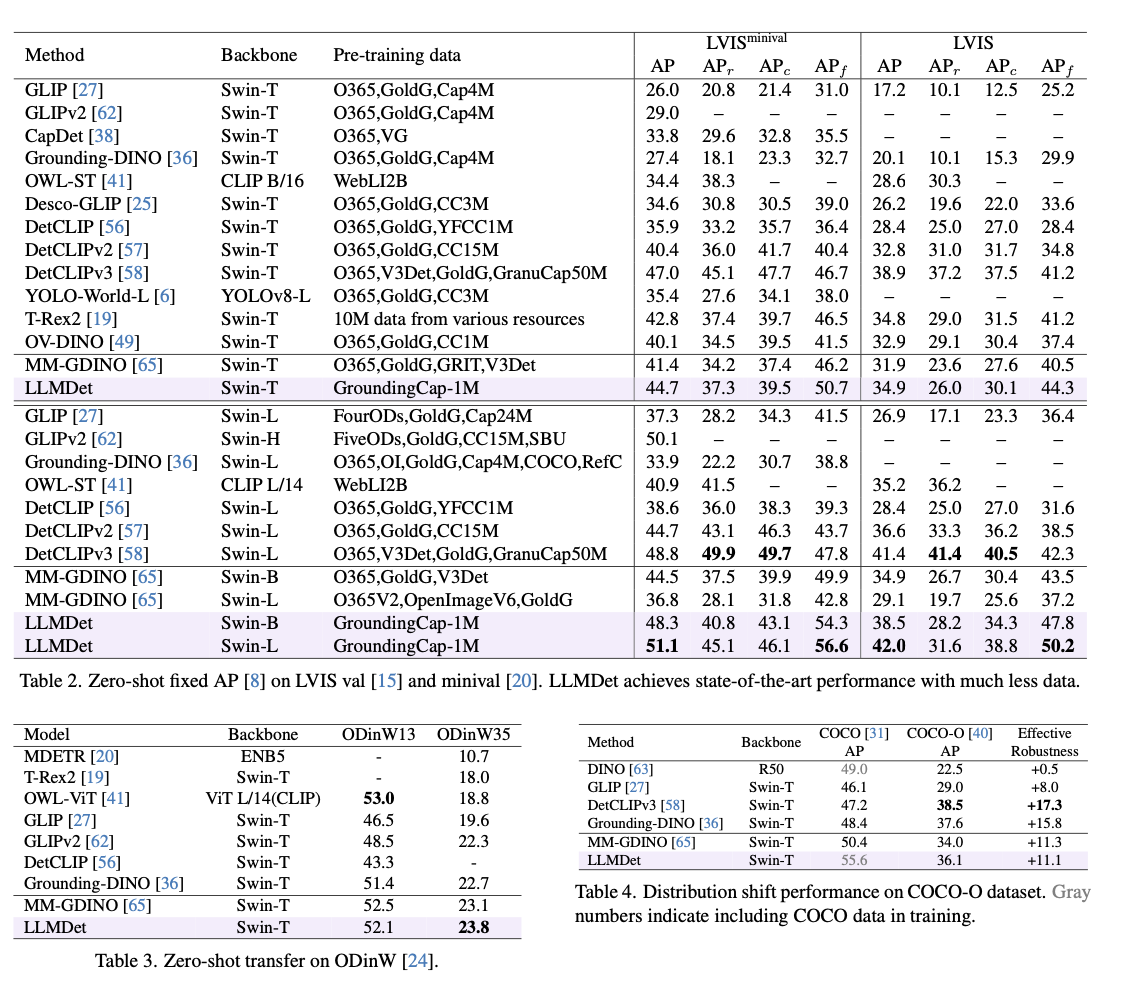
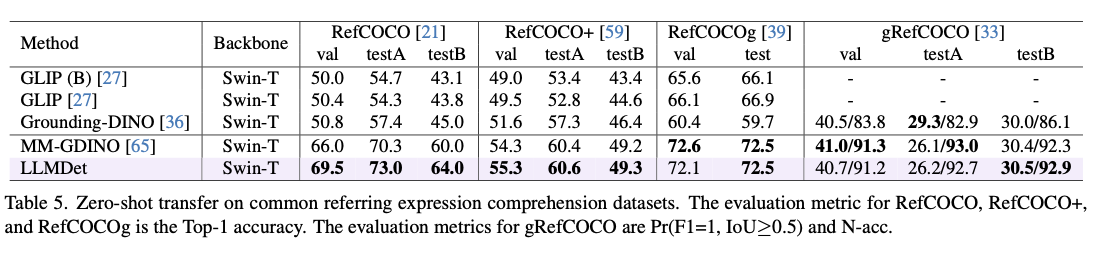
By using large language models in open-vocabulary detection, LLMDet provides a scalable and efficient learning paradigm. This development remedies the primary challenges to existing OVD frameworks, with state-of-the-art performance on several detection benchmarks and improved zero-shot generalization and rare-class detection. Vision-language learning integration promotes cross-domain adaptability and enhances multi-modal interactions, showing the promise of language-guided supervision in object detection research.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)
Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)The post LLMDet: How Large Language Models Enhance Open-Vocabulary Object Detection appeared first on MarkTechPost.
Source: Read MoreÂ

