




Large Language Models (LLMs) have demonstrated remarkable capabilities in complex reasoning tasks, particularly in mathematical problem-solving and coding applications. Research has shown a strong correlation between the length of reasoning chains and improved accuracy in problem-solving outcomes. However, they face significant challenges: while extended reasoning processes enhance problem-solving capabilities, they often lead to inefficient solutions. Models tend to generate unnecessarily lengthy reasoning chains even for simple questions that could be solved more directly. This one-size-fits-all approach to reasoning length creates computational inefficiency and reduces the practical utility of these systems in real-world applications.
Various methodologies have emerged to enhance LLMs’ reasoning capabilities, with Chain-of-Thought (CoT) being a foundational approach that improves problem-solving by breaking down reasoning into discrete steps. Building upon CoT, researchers have developed more complex techniques such as extended CoT with additional steps, self-reflection mechanisms, multi-turn reasoning, and multi-agent debate systems. Recent developments have focused on scaling up reasoning length, as demonstrated by models like OpenAI-o1 and DeepSeek-R1. However, they generate extensive reasoning chains regardless of the problem’s complexity. This inefficient approach increases computational costs and larger carbon footprints.
Researchers from Meta AI and The University of Illinois Chicago have proposed an innovative approach to address the inefficiencies in LLM reasoning by developing a system that automatically adjusts reasoning trace lengths based on query complexity. While previous heuristic methods have attempted to improve token efficiency for better accuracy with reduced overhead, this new research takes a reinforcement learning (RL) perspective. Instead of explicitly modeling response lengths or balancing intrinsic and extrinsic rewards, the researchers have developed a grouping methodology, that involves categorizing responses into distinct groups based on their characteristics, creating a comprehensive framework to cover the entire response space while maintaining efficiency.
The proposed methodology employs a sequence-level notation system that simplifies the complex transition probabilities and intermediate rewards by treating each response as a complete unit. The architecture divides responses into two primary groups, one for regular-length Chain-of-Thought responses and the other for extended responses, each with distinct inference costs. The system operates through a bi-level optimization framework, where resource allocation constraints are defined within a convex polytope that limits the density mass of each group. Moreover, the algorithm uses an iterative approach, solving the upper-level problem through gradient updates while directly addressing the lower-level optimization at each iteration.
The experimental results demonstrate significant performance improvements across different implementations of the proposed methodology. The supervised fine-tuning (SFT) constructions, SVSFT and ASV-SFT-1, achieve enhanced pass@1 metrics, though at the cost of increased inference requirements. More notably, the ASV-IuB-q+ formulation with parameters set at 50% and 75% show remarkable efficiency improvements, reducing costs by 4.14% at 2.16 times and 5.74% at 4.32 times respectively, matching the performance of SCoRe, a leading RL-based self-correction method. The findings also reveal a noteworthy limitation of prompting-based and SFT-based methods in both absolute improvement and efficiency metrics, suggesting that self-correction capabilities emerge more effectively through RL.
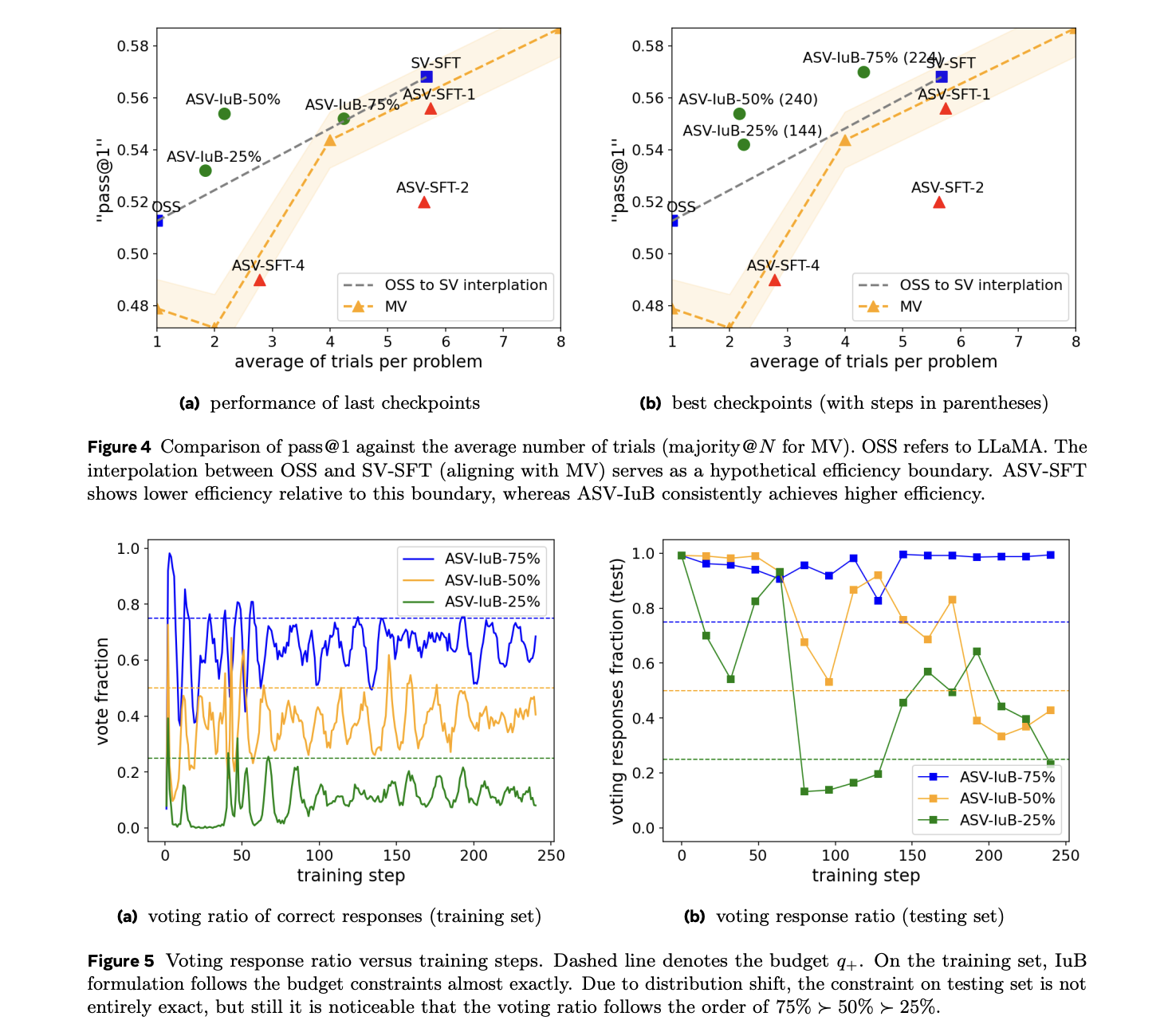
In conclusion, researchers introduced a method to overcome the inefficiencies in LLM reasoning. Moreover, they introduced IBPO, a constrained policy optimization framework that implements a weighted Supervised Fine-Tuning update mechanism. This approach determines optimal weights through an integer linear programming solution, in each iteration, built upon the CGPO framework. While the system shows effective constraint adherence and dynamic inference budget allocation in mathematical reasoning tasks, computational resource limitations can be addressed through sample accumulation across multiple steps. Future research directions include expanding the framework’s applicability across different LLM applications and scaling up experimental implementations to test its full potential in various contexts.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)
Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)The post Adaptive Inference Budget Management in Large Language Models through Constrained Policy Optimization appeared first on MarkTechPost.
Source: Read MoreÂ

