




As deep learning models continue to grow, the quantization of machine learning models becomes essential, and the need for effective compression techniques has become increasingly relevant. Low-bit quantization is a method that reduces model size while attempting to retain accuracy. Researchers have been determining the best bit-width for maximizing efficiency without compromising performance. Various studies have explored different bit-width settings, but conflicting conclusions have arisen due to the absence of a standardized evaluation framework. This ongoing pursuit influences the development of large-scale artificial intelligence models, determining their feasibility for deployment in memory-constrained environments.
A major challenge in low-bit quantization is identifying the optimal trade-off between computational efficiency & model accuracy. The debate over which bit-width is most effective remains unresolved, with some arguing that 4-bit quantization provides the best balance, while others claim that 1.58-bit models can achieve comparable results. However, prior research has lacked a unified methodology to compare different quantization settings, leading to inconsistent conclusions. This knowledge gap complicates establishing reliable scaling laws in low-bit precision quantization. Moreover, achieving stable training in extremely low-bit settings poses a technical hurdle, as lower-bit models often experience significant representational shifts compared to higher-bit counterparts.
Quantization approaches vary in their implementation and effectiveness. After training a model in full precision, post-training quantization (PTQ) applies quantization, making it easy to deploy but prone to accuracy degradation at low bit-widths. Quantization-aware training (QAT), on the other hand, integrates quantization into the training process, allowing models to adapt to low-bit representations more effectively. Other techniques, such as learnable quantization and mixed-precision strategies, have been explored to fine-tune the balance between accuracy and model size. However, these methods lack a universal framework for systematic evaluation, making it difficult to compare their efficiency under different conditions.
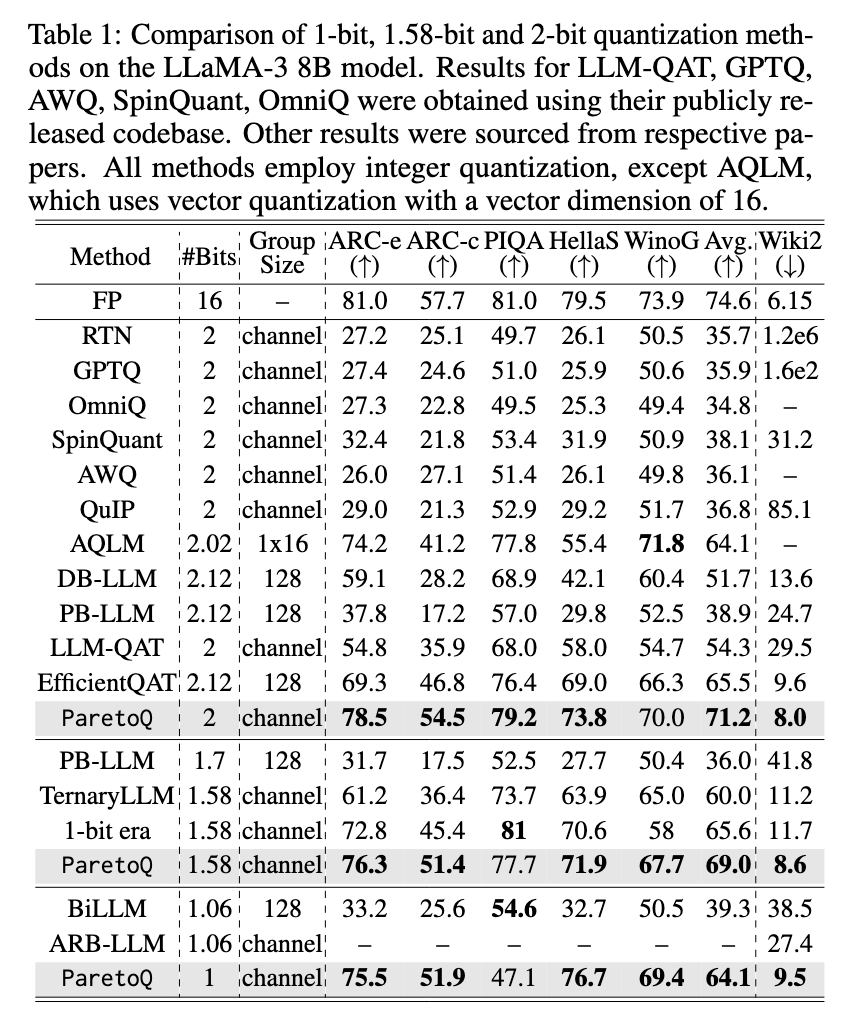
Researchers at Meta have introduced ParetoQ, a structured framework designed to unify the assessment of sub-4-bit quantization techniques. This framework allows rigorous comparisons across different bit-width settings, including 1-bit, 1.58-bit, 2-bit, 3-bit, and 4-bit quantization. By refining training schemes and bit-specific quantization functions, ParetoQ achieves improved accuracy and efficiency over previous methodologies. Unlike prior works that independently optimize for specific bit levels, ParetoQ establishes a consistent evaluation process that objectively compares quantization trade-offs.
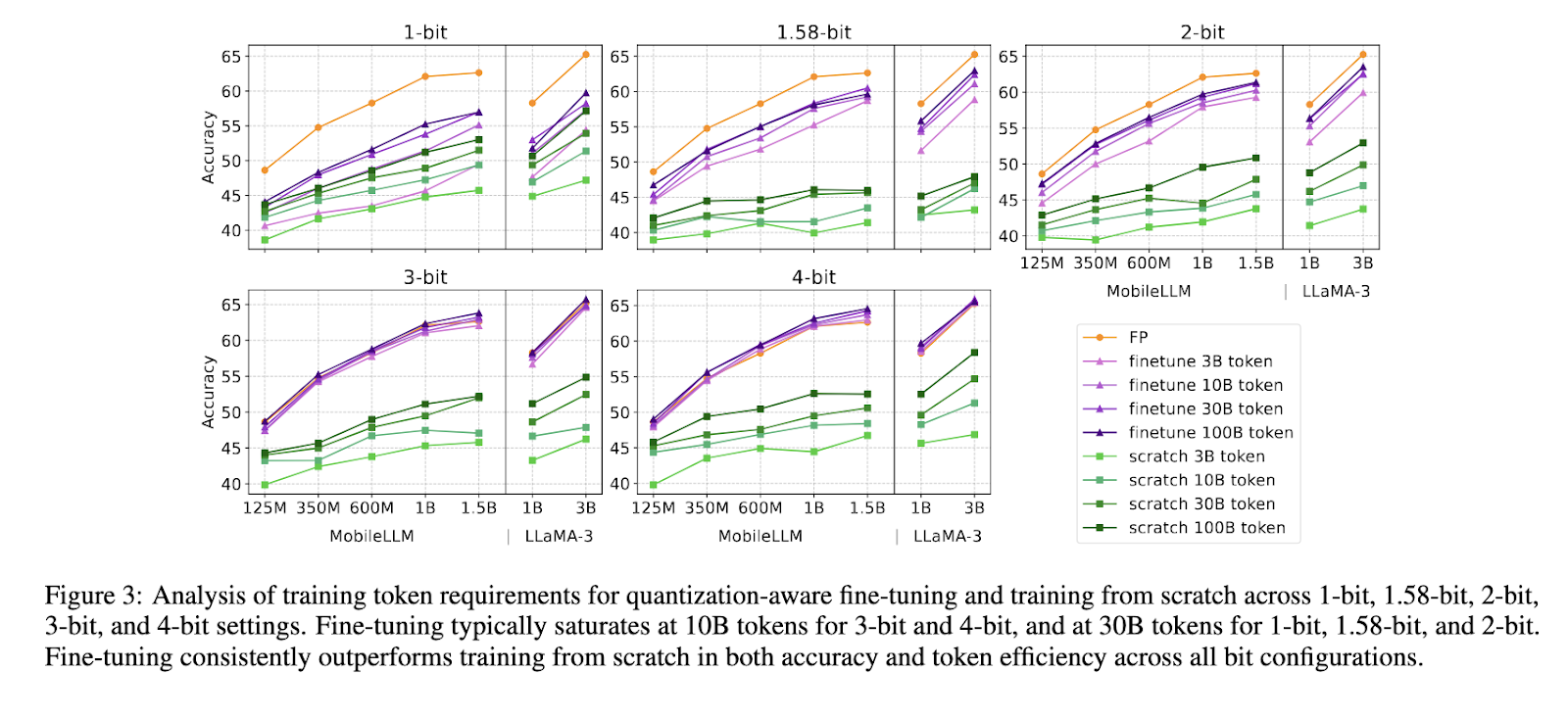
ParetoQ employs an optimized quantization-aware training strategy to minimize accuracy loss while maintaining model compression efficiency. The framework refines bit-specific quantization functions and tailors training strategies for each bit-width. A critical finding from this study is the distinct learning transition observed between 2-bit and 3-bit quantization. Models trained at 3-bit precision and higher maintain representation similarities with their original pre-trained distributions, while models trained at 2-bit or lower experience drastic representational shifts. To overcome this challenge, the framework systematically optimizes the quantization grid, training allocation, and bit-specific learning strategies.
Extensive experiments confirm the superior performance of ParetoQ over existing quantization methods. A ternary 600M-parameter model developed using ParetoQ outperforms the previous state-of-the-art ternary 3B-parameter model in accuracy while utilizing only one-fifth of the parameters. The study demonstrates that 2-bit quantization achieves an accuracy improvement of 1.8 percentage points over a comparable 4-bit model of the same size, establishing its viability as an alternative to conventional 4-bit quantization. Further, ParetoQ enables a more hardware-friendly implementation, with optimized 2-bit CPU kernels achieving higher speed and memory efficiency compared to 4-bit quantization. The experiments also reveal that ternary, 2-bit and 3-bit quantization models achieve better accuracy-size trade-offs than 1-bit and 4-bit quantization, reinforcing the significance of sub-4-bit approaches.
The findings of this study provide a strong foundation for optimizing low-bit quantization in large language models. By introducing a structured framework, the research effectively addresses the challenges of accuracy trade-offs and bit-width optimization. The results indicate that while extreme low-bit quantization is viable, 2-bit and 3-bit quantization currently offer the best balance between performance and efficiency. Future advancements in hardware support for low-bit computation will further enhance the practicality of these techniques, enabling more efficient deployment of large-scale machine learning models in resource-constrained environments.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)
Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)The post Meta AI Introduces ParetoQ: A Unified Machine Learning Framework for Sub-4-Bit Quantization in Large Language Models appeared first on MarkTechPost.
Source: Read MoreÂ

