




LLM inference is highly resource-intensive, requiring substantial memory and computational power. To address this, various model parallelism strategies distribute workloads across multiple GPUs, reducing memory constraints and speeding up inference. Tensor parallelism (TP) is a widely used technique that partitions weights and activations across GPUs, enabling them to process a single request collaboratively. Unlike data or pipeline parallelism, which processes independent data batches on separate devices, TP ensures efficient scaling by synchronizing intermediate activations across GPUs. However, this synchronization relies on blocking AllReduce operations, creating a communication bottleneck that can significantly slow down inference, sometimes contributing to nearly 38% of the total latency, even with high-speed interconnects like NVLink.
Prior research has attempted to mitigate communication delays by overlapping computation with data transfer. Approaches such as writing fused GPU kernels for matrix operations and using domain-specific languages (DSLs) to optimize distributed workloads have shown promise. However, these techniques often require extensive low-level optimizations, making them difficult to implement in standard ML frameworks like PyTorch and JAX. Additionally, given the rapid evolution of hardware accelerators and interconnects, such optimizations frequently need to be re-engineered for new architectures. Alternative strategies, including sequence parallelism and fine-grained operation decomposition, have been explored to improve TP efficiency, but communication latency remains a fundamental limitation in large-scale distributed inference.
Researchers from institutions like USC, MIT, and Princeton introduced Ladder Residual, a model modification that enhances Tensor Parallelism efficiency by decoupling computation from communication. Instead of altering low-level kernels, Ladder Residual reroutes residual connections, enabling overlapping and reducing communication bottlenecks. Applied to a 70B-parameter Transformer, it achieves a 30% inference speedup across eight GPUs. Training 1B and 3B Ladder Transformer models from scratch maintains performance parity with standard transformers. Additionally, adapting Llama-3.1-8B with minimal retraining preserves accuracy. This scalable approach facilitates multi-GPU and cross-node deployment and broadly applies to residual-based architectures.
Utilizing Ladder Residual architecture, the Ladder Transformer enhances Transformer efficiency by enabling communication-computation overlap. It routes residual connections differently, allowing asynchronous operations that reduce communication bottlenecks. Testing on various model sizes, including the Llama-3 70B, shows up to a 29% speedup in inference throughput, with gains reaching 60% under slower communication settings. By incorporating Ladder Residual, the architecture achieves faster token processing and lower latency without sacrificing model accuracy. The approach proves beneficial even in cross-node setups, demonstrating over 30% improvement in large-scale models like the Llama 3.1 405B, making it effective for multi-GPU deployments.
The study evaluates Ladder Residual’s impact on model performance by training Ladder Transformers (1B and 3B) from scratch and comparing them with standard and parallel Transformers on 100B tokens from FineWeb-edu. Results show that Ladder Transformers perform similarly to standard models on a 1B scale but slightly worse at 3B. We also apply Ladder Residual to Llama-3.1-8B-Instruct’s upper layers, finding an initial performance drop in generative tasks, recoverable through fine-tuning. Post-adaptation, inference speed improves by 21% with minimal performance loss. The findings suggest Ladder Residual can accelerate models without significant degradation, with the potential for further optimization through advanced adaptation techniques.
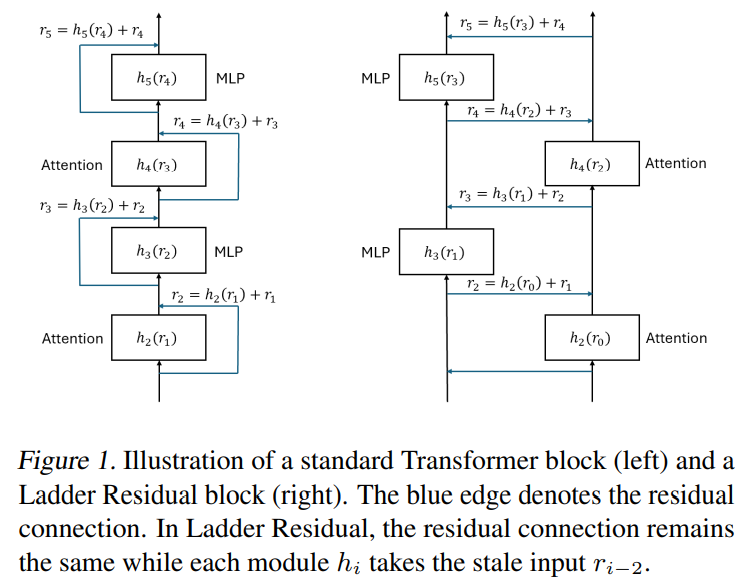
In conclusion, the study proposes Ladder Residual, an architectural modification that enables efficient communication-computation overlap in model parallelism, improving speed without compromising performance. Applied to Tensor Parallelism, it enhances large model inference by decoupling communication from computation. Testing on Ladder Transformers (1B and 3B models) shows they perform similarly to standard Transformers, achieving over 55% speedup. Applying Ladder Residual to Llama-3.1-8B requires only light retraining for a 21% inference speedup, retaining original performance. This approach reduces the need for expensive interconnects, suggesting the potential for optimizing model architectures and inference systems together. Code for replication is provided.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)
Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)The post Optimizing Large Model Inference with Ladder Residual: Enhancing Tensor Parallelism through Communication-Computing Overlap appeared first on MarkTechPost.
Source: Read MoreÂ

