




Edge devices like smartphones, IoT gadgets, and embedded systems process data locally, improving privacy, reducing latency, and enhancing responsiveness, and AI is getting integrated into these devices rapidly. But, deploying large language models (LLMs) on these devices is difficult and complex due to their high computational and memory demands.
LLMs are massive in size and power requirements. With billions of parameters, they demand significant memory and processing capacity that exceeds the capabilities of most edge devices. While quantization techniques reduce model size and power consumption, conventional hardware is optimized for symmetric computations, limiting support for mixed-precision arithmetic. This lack of native hardware support for low-bit computations restricts deployment across mobile and embedded platforms.
Prior methods for running LLMs on edge devices use high-bit precision formats like FP32 and FP16, which improve numerical stability but require significant memory and energy. Some approaches use lower-bit quantization (e.g., int8 or int4) to reduce resource demands, but compatibility issues arise with existing hardware. Another technique, dequantization, re-expands compressed models before computation but introduces latency and negates efficiency gains. Also, traditional matrix multiplication (GEMM) requires uniform precision levels, which makes performance optimization across different hardware architectures complex.
Microsoft researchers introduced a series of advancements to enable efficient low-bit quantization for LLMs on edge devices. Their approach includes three major innovations:
These techniques aim to overcome hardware limitations by facilitating mixed-precision general matrix multiplication (mpGEMM) and reducing computational overhead. With these solutions, researchers propose a practical framework that supports efficient LLM inference without requiring specialized GPUs or high-power accelerators.
The Ladder data type compiler’s first component bridges the gap between low-bit model representations and hardware constraints. It converts unsupported data formats into hardware-compatible representations while maintaining efficiency. This approach ensures modern deep learning architectures can utilize custom data types without sacrificing performance.
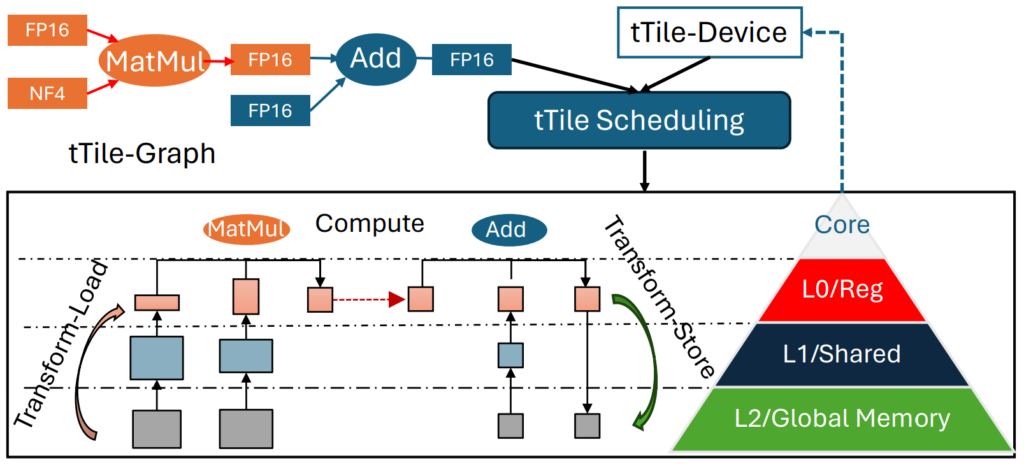
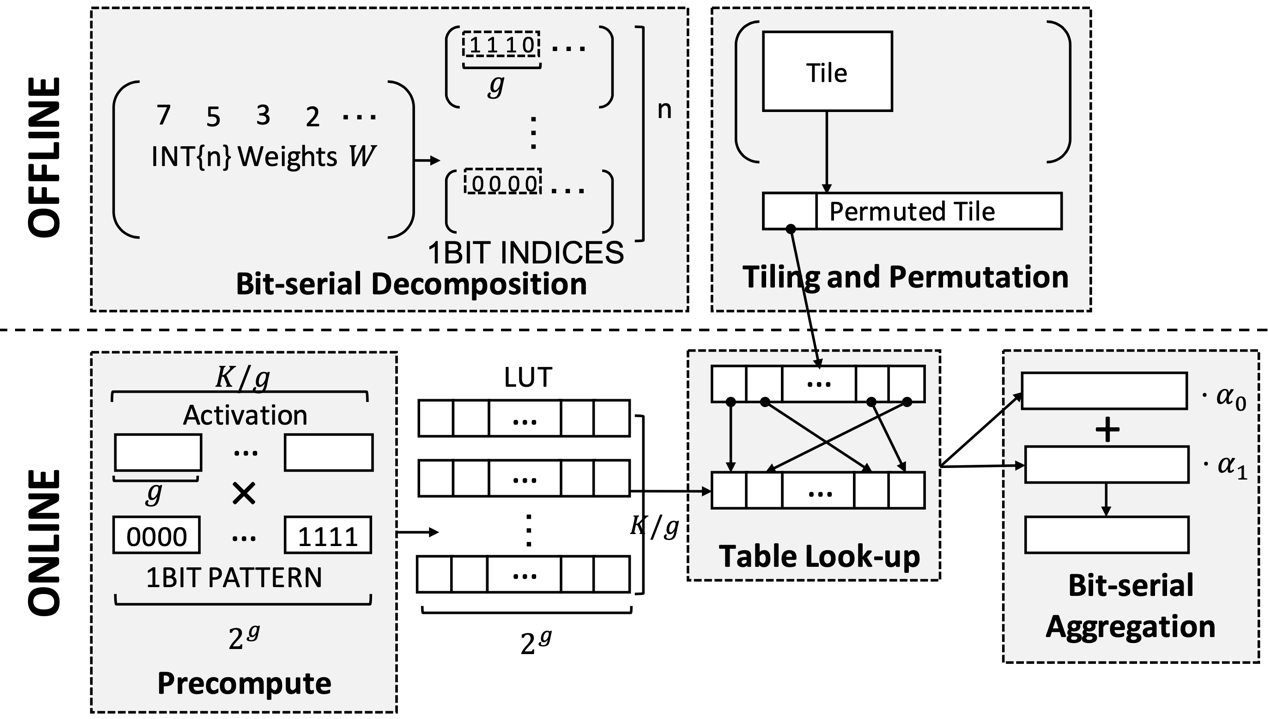
The T-MAC mpGEMM library optimizes mixed-precision computations using a lookup table (LUT)–based method instead of traditional multiplication operations. This innovation eliminates the need for dequantization and significantly enhances CPU computational efficiency.
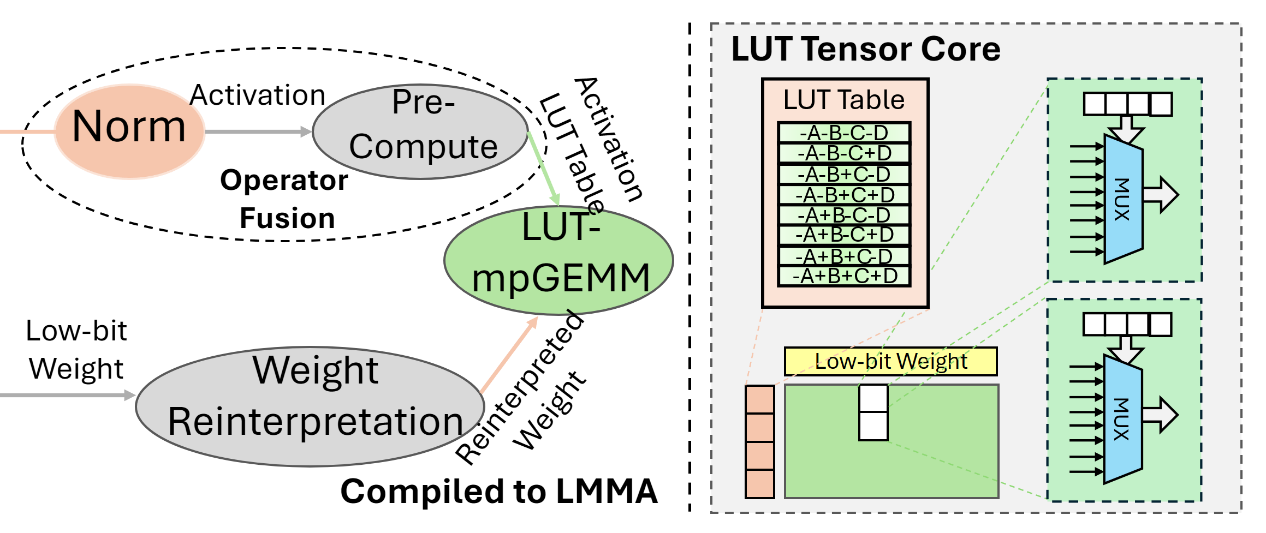
Also, the LUT Tensor Core hardware architecture introduces a specialized accelerator designed for low-bit quantization. It leverages an optimized instruction set to improve performance while reducing power consumption.
In evaluations, the Ladder data type compiler outperforms conventional deep neural network (DNN) compilers by up to 14.6 times for specific low-bit computations. When tested on edge devices like the Surface Laptop 7 with the Qualcomm Snapdragon X Elite chipset, the T-MAC library achieved 48 tokens per second for the 3B BitNet-b1.58 model, outperforming existing inference libraries. On lower-end devices such as the Raspberry Pi 5, it achieved 11 tokens per second, demonstrating significant efficiency improvements. Meanwhile, the LUT Tensor Core hardware achieved an 11.2-fold increase in energy efficiency and a 20.9-fold boost in computational density.
Several key takeaways from the research by Microsoft include:
- Low-bit quantization reduces model size, enabling efficient execution on edge devices.
- The T-MAC library enhances inference speed by eliminating traditional multiplication operations.
- The Ladder compiler ensures seamless integration of custom low-bit data formats with existing hardware.
- Optimized techniques reduce power usage, making LLMs feasible for low-energy devices.
- These methods allow LLMs to operate effectively on a wide range of hardware, from high-end laptops to low-power IoT devices.
- These innovations achieve 48 tokens per second on Snapdragon X Elite, 30 tokens per second on 2-bit 7B Llama, and 20 tokens per second on 4-bit 7B Llama.
- They also enable AI-driven applications across mobile, robotic, and embedded AI systems by making LLMs more accessible.
In conclusion, the study highlights the importance of hardware-aware quantization techniques for deploying LLMs on edge devices. The proposed solutions effectively address the long-standing challenges of memory consumption, computational efficiency, and hardware compatibility. By implementing Ladder, T-MAC, and LUT Tensor Core, researchers have paved the way for next-generation AI applications that are faster, more energy-efficient, and more scalable across various platforms.
Check out the Details and Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)
Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)The post Microsoft AI Researchers Introduce Advanced Low-Bit Quantization Techniques to Enable Efficient LLM Deployment on Edge Devices without High Computational Costs appeared first on MarkTechPost.
Source: Read MoreÂ

