




Large language models (LLMs) have become indispensable for various natural language processing applications, including machine translation, text summarization, and conversational AI. However, their increasing complexity and size have led to significant computational efficiency and memory consumption challenges. As these models grow, the resource demand makes them difficult to deploy in environments with limited computational capabilities.
The primary obstacle with LLMs lies in their massive computational requirements. Training and fine-tuning these models involve billions of parameters, making them resource-intensive and limiting their accessibility. Existing methods for improving efficiency, such as parameter-efficient fine-tuning (PEFT), provide some relief but often compromise performance. The challenge is to find an approach that can significantly reduce computational demands while maintaining the model’s accuracy and effectiveness in real-world scenarios. Researchers have been exploring methods that allow efficient model tuning without requiring extensive computational resources.

Researchers at Intel Labs and Intel Corporation have introduced an approach integrating low-rank adaptation (LoRA) with neural architecture search (NAS) techniques. This method seeks to address the limitations of traditional fine-tuning approaches while enhancing efficiency and performance. The research team developed a framework that optimizes memory consumption and computational speed by leveraging structured low-rank representations. The technique involves a weight-sharing super-network that dynamically adjusts substructures to enhance training efficiency. This integration allows the model to be fine-tuned effectively while maintaining a minimal computational footprint.
The methodology introduced by Intel Labs is centered around LoNAS (Low-rank Neural Architecture Search), which employs elastic LoRA adapters for model fine-tuning. Unlike conventional approaches that require full fine-tuning of LLMs, LoNAS enables selective activation of model substructures, reducing redundancy. The key innovation lies in the flexibility of the elastic adapters, which adjust dynamically based on model requirements. The approach is supported by heuristic sub-network searches that further streamline the fine-tuning process. By focusing only on relevant model parameters, the technique achieves a balance between computational efficiency and performance. The process is structured to allow selective activation of low-rank structures while maintaining high inference speed.
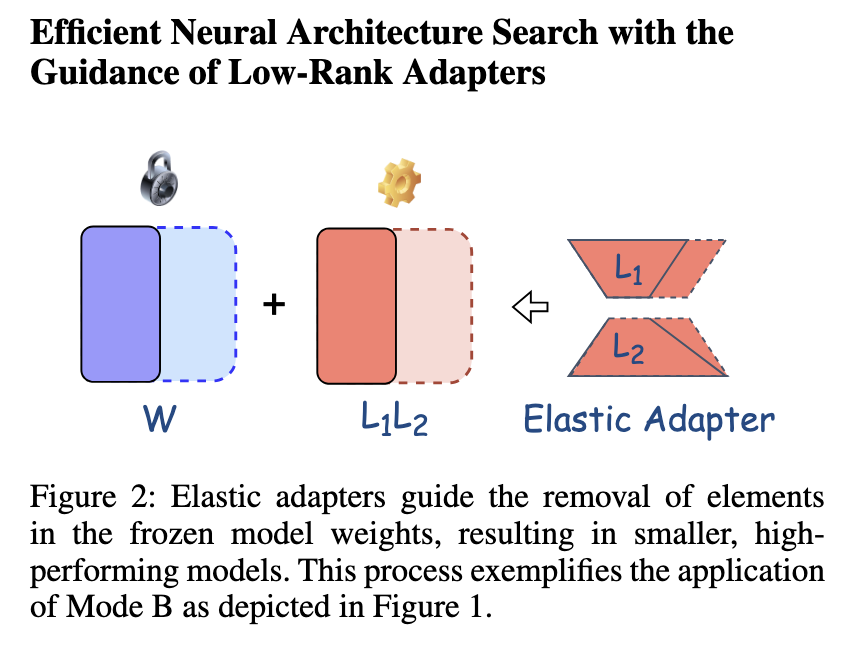
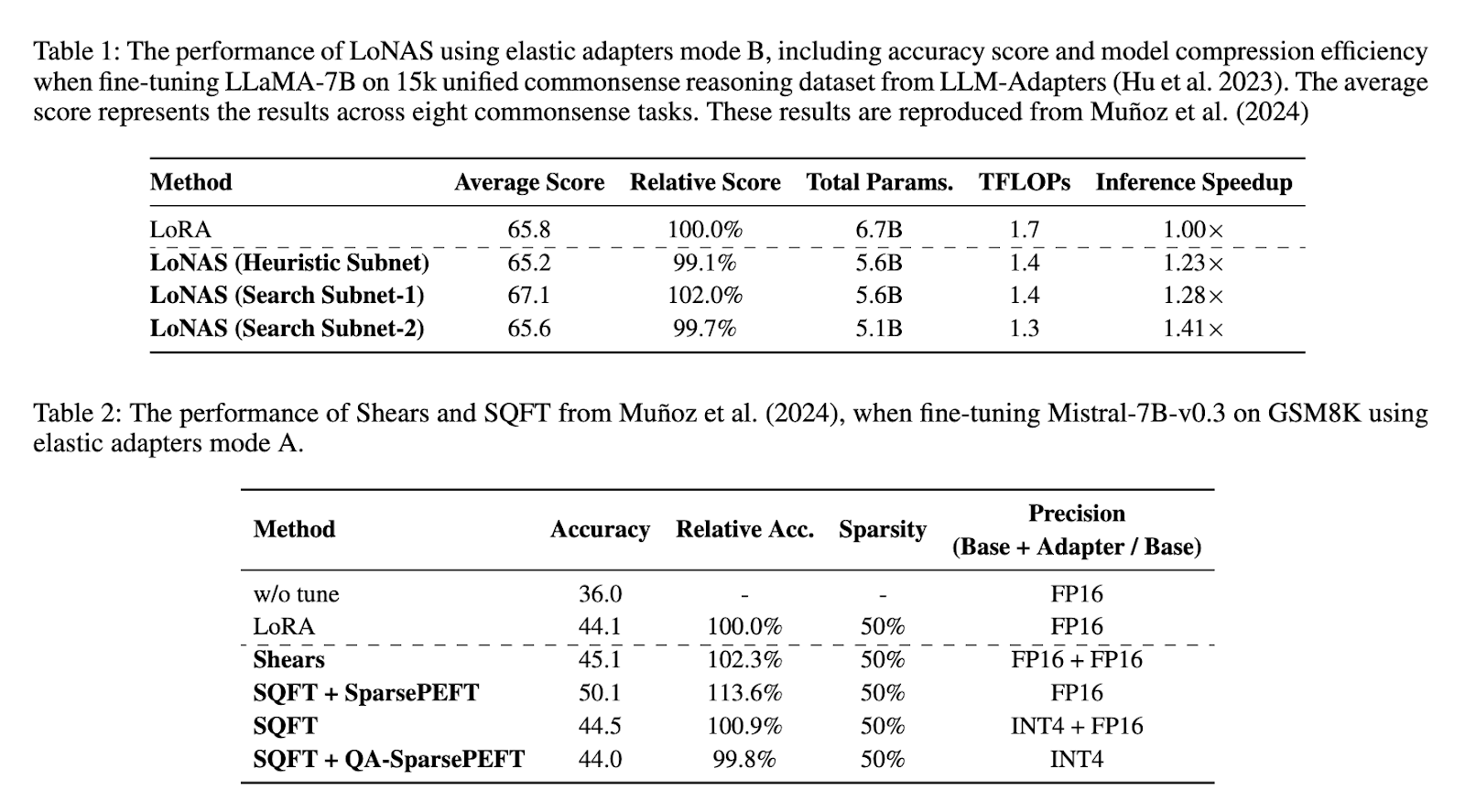
Performance evaluation of the proposed method highlights its significant improvements over conventional techniques. Experimental results indicate that LoNAS achieves an inference speedup of up to 1.4x while reducing model parameters by approximately 80%. When applied to fine-tuning LLaMA-7B on a 15k unified commonsense reasoning dataset, LoNAS demonstrated an average accuracy score of 65.8%. A comparative analysis of different LoNAS configurations showed that heuristic subnet optimization achieved an inference speedup of 1.23x, while search subnet configurations yielded speedups of 1.28x and 1.41x. Further, applying LoNAS to Mistral-7B-v0.3 in GSM8K tasks increased accuracy from 44.1% to 50.1%, maintaining efficiency across different model sizes. These findings confirm that the proposed methodology significantly enhances the performance of LLMs while reducing computational requirements.
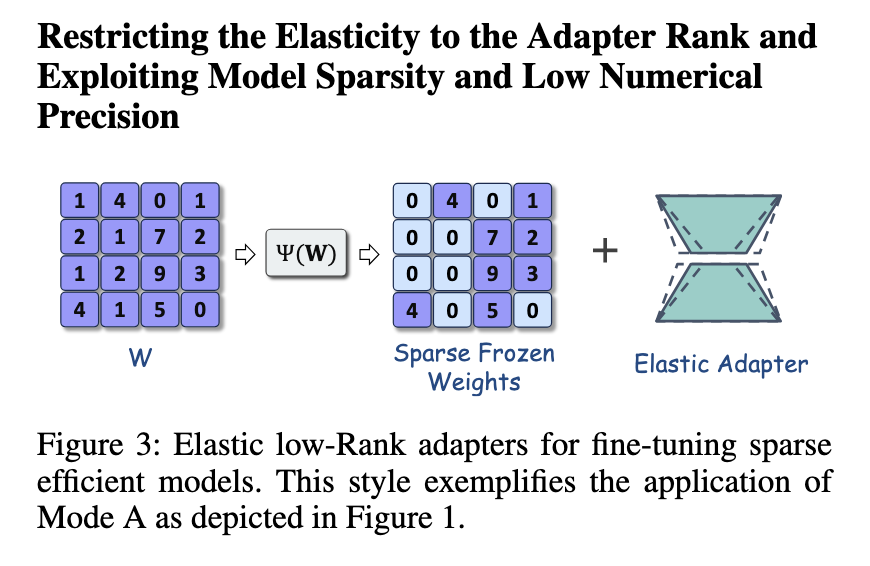
Further improvements to the framework include the introduction of Shears, an advanced fine-tuning strategy that builds on LoNAS. Shears utilize neural low-rank adapter search (NLS) to restrict elasticity to the adapter rank, reducing unnecessary computations. The approach applies sparsity to the base model using predefined metrics, ensuring that fine-tuning remains efficient. This strategy has been particularly effective in maintaining model accuracy while reducing the number of active parameters. Another extension, SQFT, incorporates sparsity and low numerical precision for enhanced fine-tuning. Using quantization-aware techniques, SQFT ensures that sparse models can be fine-tuned without losing efficiency. These refinements highlight the adaptability of LoNAS and its potential for further optimization.
Integrating LoRA and NAS offers a transformative approach to large language model optimization. By leveraging structured low-rank representations, the research demonstrates that computational efficiency can be significantly improved without compromising performance. The study conducted by Intel Labs confirms that combining these techniques reduces the burden of fine-tuning while ensuring model integrity. Future research could explore further optimizations, including enhanced sub-network selection and more efficient heuristic strategies. This approach sets a precedent for making LLMs more accessible and deployable in diverse environments, paving the way for more efficient AI models.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.
 Meet IntellAgent: An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System (Promoted)
Meet IntellAgent: An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System (Promoted)
The post Intel Labs Explores Low-Rank Adapters and Neural Architecture Search for LLM Compression appeared first on MarkTechPost.
Source: Read MoreÂ

