




Large Language Models (LLMs) have become increasingly reliant on Reinforcement Learning from Human Feedback (RLHF) for fine-tuning across various applications, including code generation, mathematical reasoning, and dialogue assistance. However, a significant challenge has emerged in the form of reduced output diversity when using RLHF. Research has identified a critical trade-off between alignment quality and output diversity in RLHF-trained models. When these models align highly with desired objectives, they show limited output variability. This limitation poses concerns for creative open-ended tasks such as story generation, data synthesis, and red-teaming, where diverse outputs are essential for effective performance.
Existing approaches to LLM alignment have focused on enhancing instruction following, safety, and reliability through RLHF, but these improvements often come at the cost of output diversity. Various methods have been developed to address this challenge, including the use of f-divergence with DPO/PPO algorithms, which attempt to balance diversity and alignment. Other approaches integrate evaluation metrics like SelfBLEU and Sentence-BERT into RL fine-tuning to boost diversity, particularly for red-teaming tasks. Moreover, some researchers have explored curiosity-driven reinforcement learning methods, ranging from count-based approaches to prediction error-based techniques. Despite these efforts, the fundamental trade-off between alignment quality and output diversity remains a significant challenge.
Researchers from Baidu have proposed a novel framework called Curiosity-driven Reinforcement Learning from Human Feedback (CD-RLHF) to address the diversity-alignment trade-off in language models. This approach incorporates curiosity as an intrinsic reward mechanism during the RLHF training stage, working alongside traditional extrinsic rewards from the reward model. CD-RLHF uses forward dynamics to compute prediction errors of state representations, which helps estimate curiosity levels. A key feature of this approach is that frequently visited states gradually become less interesting to the model. This dual reward system aims to maintain high alignment quality while promoting diverse outputs through varied token choices at each decision point.
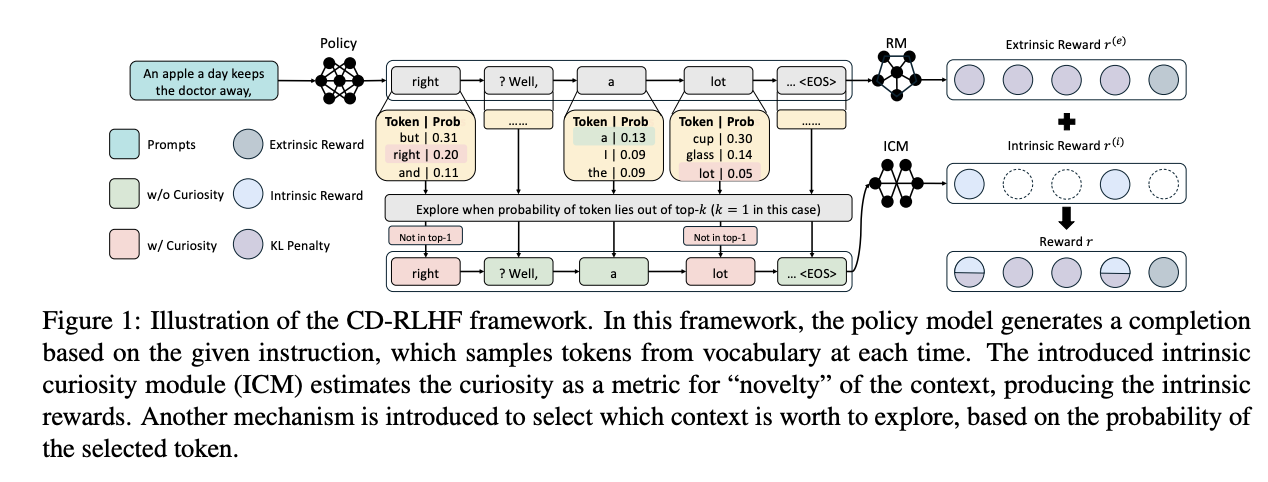
The implementation and evaluation of CD-RLHF encompasses multiple components and datasets. The architecture was tested on two primary datasets: TL;DR for text summarization, containing 93k human-annotated preference pairs, and UltraFeedback for instruction following, with 61.1k training pairs. The framework was implemented using various base models including Gemma-2B, Gemma-7B, Llama-3.2-1B, and Llama-3.2-3B, all trained within the DeepSpeed-Chat framework. The training data was distributed across SFT, RM, and PPO stages in a 20/40/40 ratio. For comparison, baseline methods including vanilla RLHF and Sent-Rewards are implemented, which use SelfBLEU and Sentence-BERT scores as additional rewards during training.
The experimental results demonstrate CD-RLHF’s superior performance across multiple evaluation metrics and models. In the TL;DR summarization task, CD-RLHF achieves significant improvements in output diversity showing gains of 16.66% and 6.22% on Gemma-2B and Gemma-7B respectively compared to the RLHF baseline. For the UltraFeedback instruction-following task, the method shows even more impressive results, with diversity improvements ranging from 7.35% to 14.29% across different models while maintaining strong alignment quality. External validation through GPT-4 evaluation showed CD-RLHF achieving win rates of up to 58% against the PPO baseline on TL;DR and an average of 62% on UltraFeedback.
In conclusion, researchers introduced CD-RLHF which represents a significant advancement in addressing the diversity-alignment trade-off in language model training. The framework combines curiosity-driven exploration with traditional extrinsic rewards to enhance output diversity while maintaining alignment quality, as shown through extensive testing on TL;DR summarization and UltraFeedback instruction-following tasks. Despite these achievements, several challenges remain, including the need to balance different reward scales and the persistent gap between the output diversity of SFT, and RLHF-trained models. While CD-RLHF mitigates the trade-off between diversity and alignment, further research is needed to fully bridge this gap and achieve optimal performance across both metrics.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.
 Meet IntellAgent: An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System (Promoted)
Meet IntellAgent: An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System (Promoted)
The post Curiosity-Driven Reinforcement Learning from Human Feedback CD-RLHF: An AI Framework that Mitigates the Diversity Alignment Trade-off In Language Models appeared first on MarkTechPost.
Source: Read MoreÂ

