




Large Language Models (LLMs) have emerged as transformative tools in research and industry, with their performance directly correlating to model size. However, training these massive models presents significant challenges, related to computational resources, time, and cost. The training process for state-of-the-art models like Llama 3 405B requires extensive hardware infrastructure, utilizing up to 16,000 H100 GPUs over 54 days. Similarly, models like GPT-4, estimated to have one trillion parameters, demand extraordinary computational power. These resource requirements create barriers to entry and development in the field, highlighting the critical need for more efficient training methodologies for advancing LLM technology while reducing the associated computational burden.
Various approaches have been explored to address the computational challenges in LLM training and inference. Mixed Precision Training has been widely adopted to accelerate model training while maintaining accuracy, initially focusing on CNNs and DNNs before expanding to LLMs. For inference optimization, Post-Training Quantization (PTQ) and Quantization Aware Training (QAT) have achieved significant compression using 4-bit, 2-bit, and even 1-bit quantization. While differentiable quantization techniques have been proposed using learnable parameters updated through backpropagation, they face limitations in handling activation outliers effectively. Existing solutions for managing outliers depend on offline pre-processing methods, making them impractical for direct application in training scenarios.
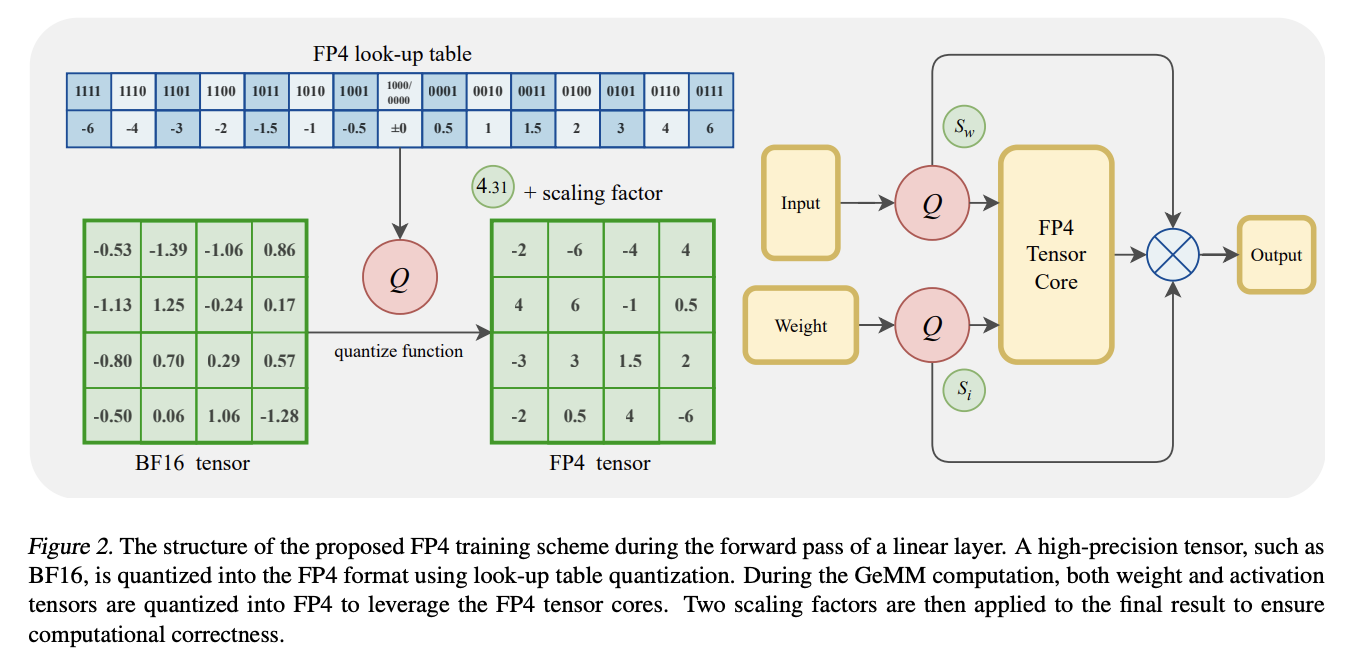
Researchers from the University of Science and Technology of China, Microsoft SIGMA Team, and Microsoft Research Asia have proposed a framework for training language models using the FP4 format, marking the first comprehensive validation of this ultra-low precision representation. The framework addresses quantization errors through two key innovations:
- A differentiable quantization estimator for weights that enhances gradient updates in FP4 computations by incorporating correction terms
- An outlier handling mechanism for activations that combines clamping with a sparse auxiliary matrix.
These techniques help to maintain model performance while enabling efficient training in ultra-low precision formats, representing a significant advancement in efficient LLM training.
The framework primarily targets General Matrix Multiplication (GeMM) operations, containing over 95% of LLM training computations. The architecture implements 4-bit quantization for GeMM operations using distinct quantization approaches: token-wise quantization for activation tensors and channel-wise quantization for weight tensors. Due to hardware limitations, the system’s performance is validated using Nvidia H-series GPUs’ FP8 Tensor Cores, which can accurately simulate FP4’s dynamic range. The framework employs FP8 gradient communication and a mixed-precision Adam optimizer for memory efficiency. The system was validated using the LLaMA 2 architecture, trained from scratch on the DCLM dataset, with carefully tuned hyperparameters including a warm-up and cosine decay learning rate schedule, and specific parameters for the FP4 method’s unique components.
The proposed FP4 training framework shows that training curves for LLaMA models of 1.3B, 7B, and 13B parameters have similar patterns between FP4 and BF16 implementations, with FP4 showing marginally higher training losses: 2.55 vs. 2.49 (1.3B), 2.17 vs. 2.07 (7B), and 1.97 vs. 1.88 (13B) after 100B tokens of training. Zero-shot evaluations across diverse downstream tasks, including Arc, BoolQ, HellaSwag, LogiQA, PiQA, SciQ, OpenbookQA, and Lambada, reveal that FP4-trained models achieve competitive or occasionally superior performance compared to their BF16 counterparts. The results demonstrate that larger models achieve higher accuracy, validating the scalability of the FP4 training approach.
In conclusion, researchers have successfully developed and validated the first FP4 pretraining framework for LLMs, marking a significant advancement in ultra-low-precision computing. The framework achieves performance comparable to higher-precision formats across various model scales through innovative solutions like the differentiable gradient estimator and outlier compensation mechanism. However, the current implementation faces a notable limitation: the lack of dedicated FP4 Tensor Cores in existing hardware necessitates simulation-based testing, which introduces computational overhead and prevents direct measurement of potential efficiency gains. This limitation underscores the need for hardware advancement to realize the benefits of FP4 computation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.

The post Optimization Using FP4 Quantization For Ultra-Low Precision Language Model Training appeared first on MarkTechPost.
Source: Read MoreÂ
