




Lexicon-based embeddings are one of the good alternatives to dense embeddings, yet they face numerous challenges that restrain their wider adoption. One key problem is tokenization redundancy, whereby subword tokenization breaks semantically equivalent tokens, causing inefficiencies and inconsistencies in embeddings. The other limitation of causal LLMs is unidirectional attention; this means tokens cannot fully leverage the surrounding context while pretraining. These challenges confine the adaptability and efficiency of lexicon-based embeddings, especially in tasks beyond information retrieval, thereby making it necessary to utilize a stronger approach than the previous ones to make them more useful.
Several techniques have been proposed to investigate the possibility of usages through lexicon-based embeddings. SPLADE uses bidirectional attention and aligns the embeddings with language modeling objectives, while PromptReps utilizes prompt engineering to produce lexicon-based embeddings in causal LLMs. SPLADE is limited to smaller models and a specific retrieval task, limiting its applicability. The PromptReps model lacks contextual understanding with unidirectional attention, and the performance obtained is suboptimal. This class of methods often has very high computational complexity, inefficiency due to fragmenting tokenization, and lacks scope for larger applications such as clustering and classification.
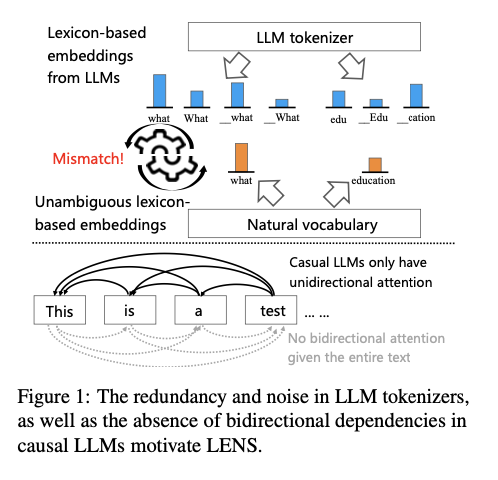
Researchers from the University of Amsterdam, the University of Technology Sydney, and Tencent IEG propose LENS (Lexicon-based EmbeddiNgS), a groundbreaking framework designed to address the limitations of current lexicon-based embedding techniques. Through applying KMeans for the clustering of semantically analogous tokens, LENS effectively amalgamates token embeddings, thereby minimizing redundancy and dimensionality. This streamlined representation facilitates the creation of embeddings characterized by reduced dimensions, all the while maintaining semantic depth. In addition, bidirectional attention is used to overcome the contextual constraints imposed by unidirectional attention used by causal LLMs. It allows tokens to fully utilize their context on both sides. Several experimental experiments showed that max-pooling works the best among pooling strategies for word embeddings. Finally, LENS is used along with dense embeddings. The hybrid embedding uses the best features of the two approaches. Hence, it performs better over a wide range of tasks. These enhancements make LENS a versatile and efficient framework for producing interpretable and contextually-aware embeddings that can be used for clustering, classification, and retrieval applications.
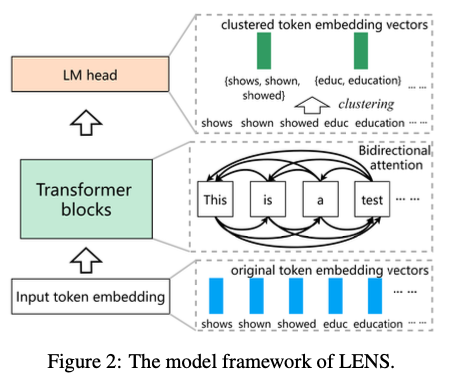
LENS uses clustering to replace the original token embeddings with cluster centroids in the language modeling head, removing redundancy and the dimensionality of the embedding. The embeddings are then 4,000 or 8,000 dimensional and as efficient and scalable as dense embeddings. In the fine-tuning stage, the model incorporates bidirectional attention that improves contextual understanding since tokens can make informed decisions based on their full context. The framework is based on the Mistral-7B model; the datasets are public and include tasks such as retrieval, clustering, classification, and semantic textual similarity. The training methodology is optimized using a streamlined single-stage pipeline and InfoNCE loss for enhancing embeddings. This methodology guarantees ease of use, the ability to scale, and strong performance on tasks, thereby rendering the framework suitable for a range of applications.
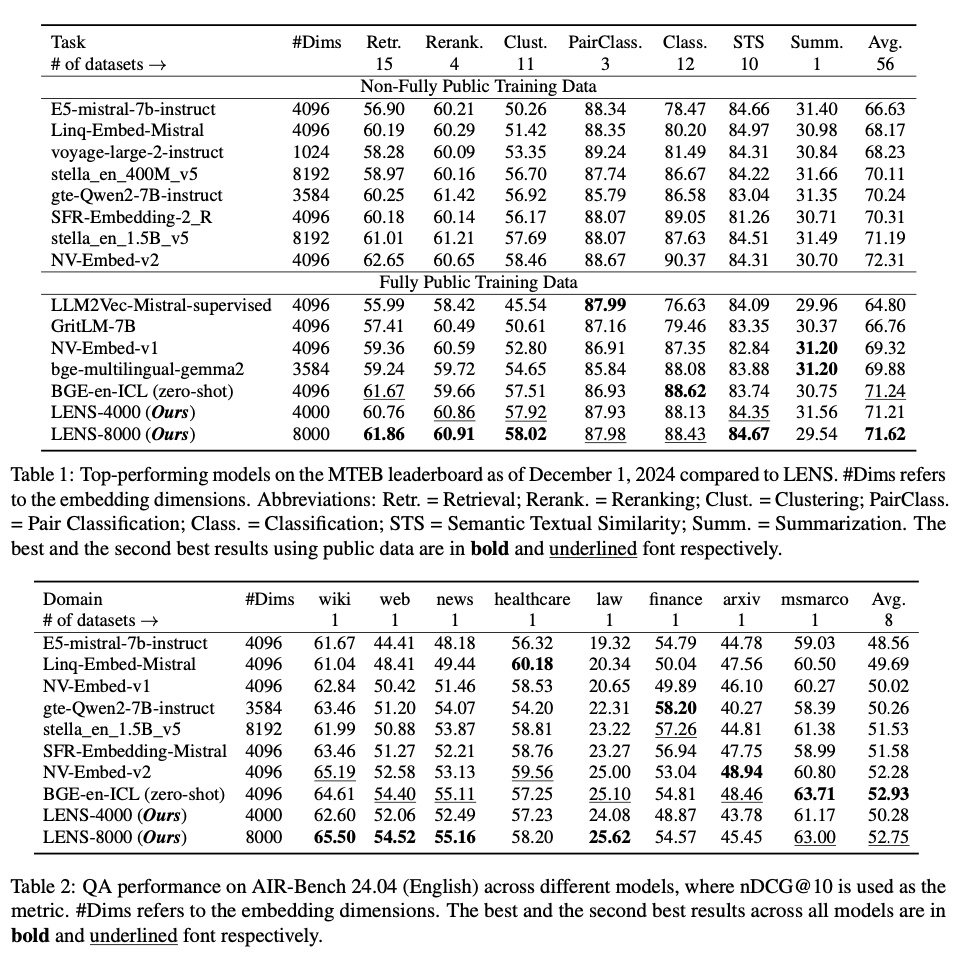
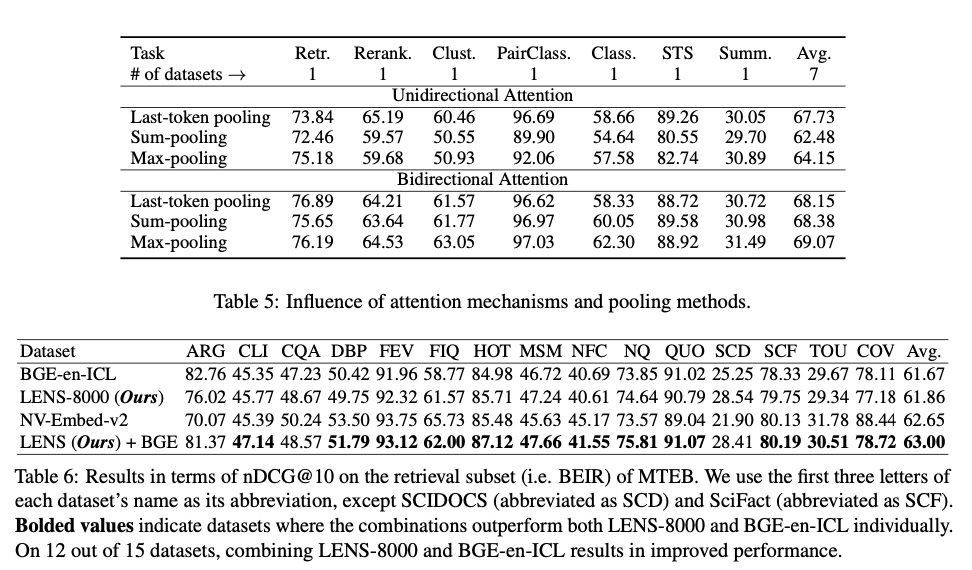
LENS exhibits remarkable efficacy across various benchmarks, such as the Massive Text Embedding Benchmark (MTEB) and AIR-Bench. Within the MTEB framework, LENS-8000 attains the highest mean score among models trained publicly, outpacing dense embeddings in six of seven task classifications. The more compact LENS-4000 model also demonstrates competitive performance, highlighting its scalability and efficiency. With dense embeddings, LENS shows strong advantages, establishing new baselines in retrieval tasks and uniformly providing improvements over a range of datasets. Qualitative evaluations demonstrate that LENS flawlessly achieves semantic associations, reduces noise in tokenization, and yields very compact and informative embeddings. The solid generalization capabilities of the framework and competitive performance in out-of-domain tasks further establish its versatility and applicability for a wide variety of tasks.
LENS is an exciting step forward for lexicon-based embedding models because they address tokenization redundancy while being more effective than other approaches that improve contextual representations through bidirectional attention mechanisms. The compactness, efficiency, and interpretability of the model are seen across a wide spectrum of tasks: from retrieval to clustering and classification tasks, which demonstrate superior performance against traditional approaches. Moreover, this effectiveness in dense environments points towards its revolutionary possibility in text representation. Future studies may extend this study by adding multi-lingual datasets and bigger models to augment its significance and relevance within the domain of artificial intelligence.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.

The post Enhancing Lexicon-Based Text Embeddings with Large Language Models appeared first on MarkTechPost.
Source: Read MoreÂ

