




The automation of radiology report generation has become one of the significant areas of focus in biomedical natural language processing. This is driven by the vast and exponentially growing medical imaging data and a dependency on highly accurate diagnostic interpretation in modern health care. Advancements in artificial intelligence make image analysis combined with natural language processing the key to changing the landscape of radiology workflows regarding efficiency, consistency, and accuracy of diagnostics.
A significant challenge in this field lies in generating comprehensive and accurate reports that meet the complexities of medical imaging. Radiology reports often require precise descriptions of imaging findings and their clinical implications. Ensuring consistency in report quality while capturing subtle nuances from medical images is particularly challenging. The limited availability of radiologists and the growing demand for imaging interpretations further complicate the situation, highlighting the need for effective automation solutions.

The traditional approach to the automation of radiology reporting is based on convolutional neural networks (CNNs) or visual transformers to extract features from images. Such image-processing techniques often combine with transformers or recurrent neural networks (RNNs) to generate textual outputs. These approaches have shown promise but usually fail to maintain factual accuracy and clinical relevance. Integrating image and text data remains a technical hurdle, which opens the way for further improvements in model design and data utilization.
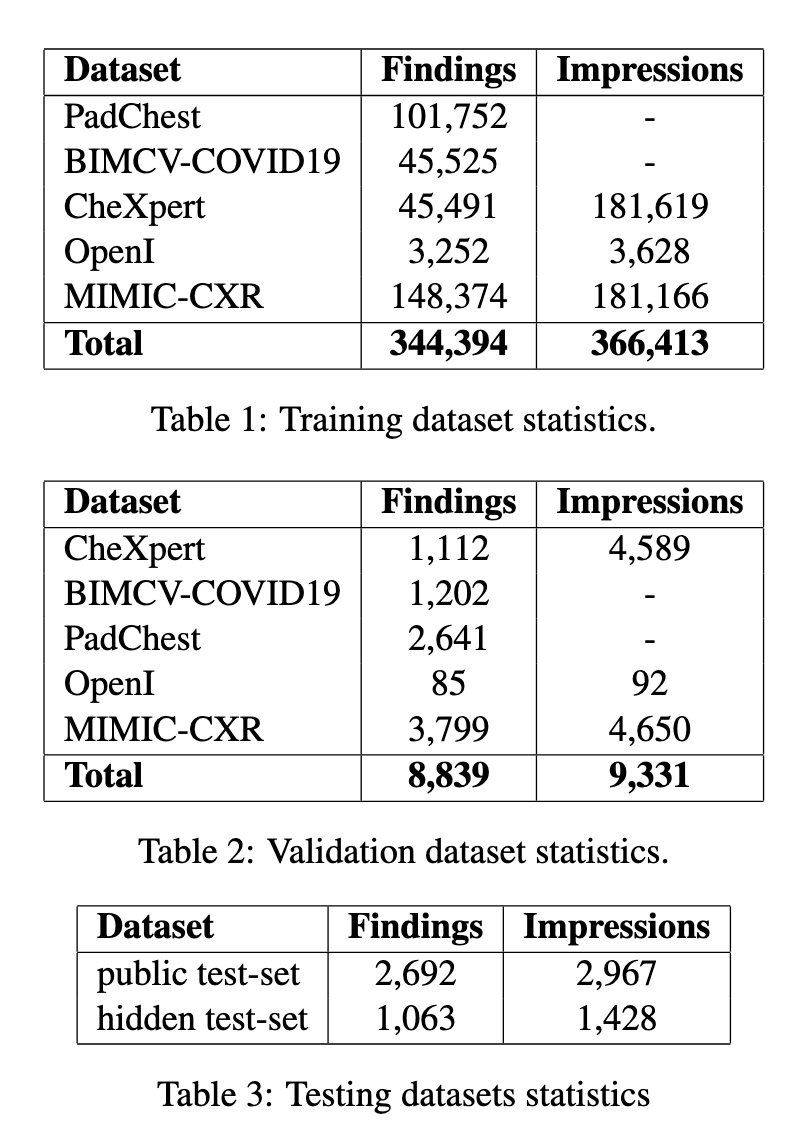
Researchers from AIRI and Skoltech brought the most advanced system that would combat all these challenges. It’s a vision encoder DINOv2 specifically trained for medical data coupled with an open biomedical large language model called OpenBio-LLM-8B. It was accomplished by using the LLaVA framework, which can ease the process of vision-language interaction. The authors relied on a PadChest dataset, BIMCV-COVID19, CheXpert, OpenI, and MIMIC-CXR datasets to train and test their model to effectively deal with many varied clinical settings.
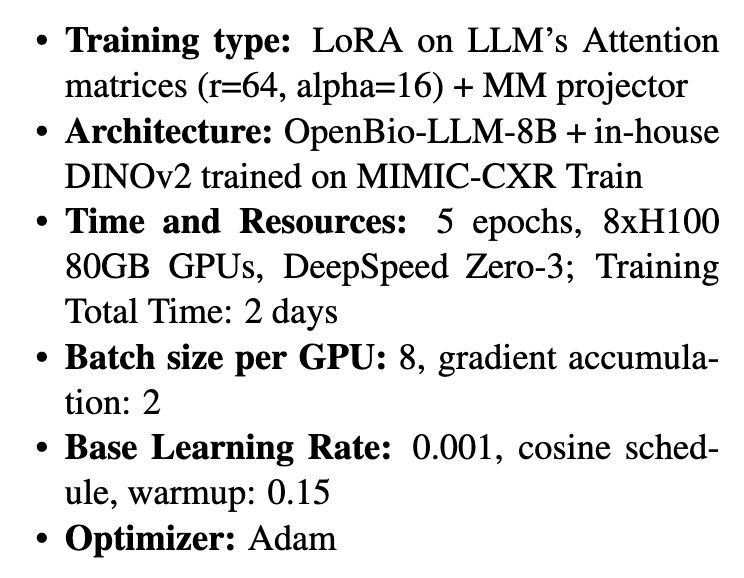
The proposed system integrates advanced methodologies for both image encoding and language generation. The DINOv2 vision encoder works on chest X-ray images, extracting nuanced features from radiological studies. These features are processed by OpenBio-LLM-8B, a text decoder optimized for the biomedical domain. Over two days, training was conducted on powerful computational resources, including 4 NVIDIA A100 GPUs. The team used a set of techniques called Low-Rank Adaptation (LoRA) fine-tuning methods to enhance learning without overfitting. Only high-quality images were included in a careful preprocessing pipeline, using the first two images from every study for evaluation.
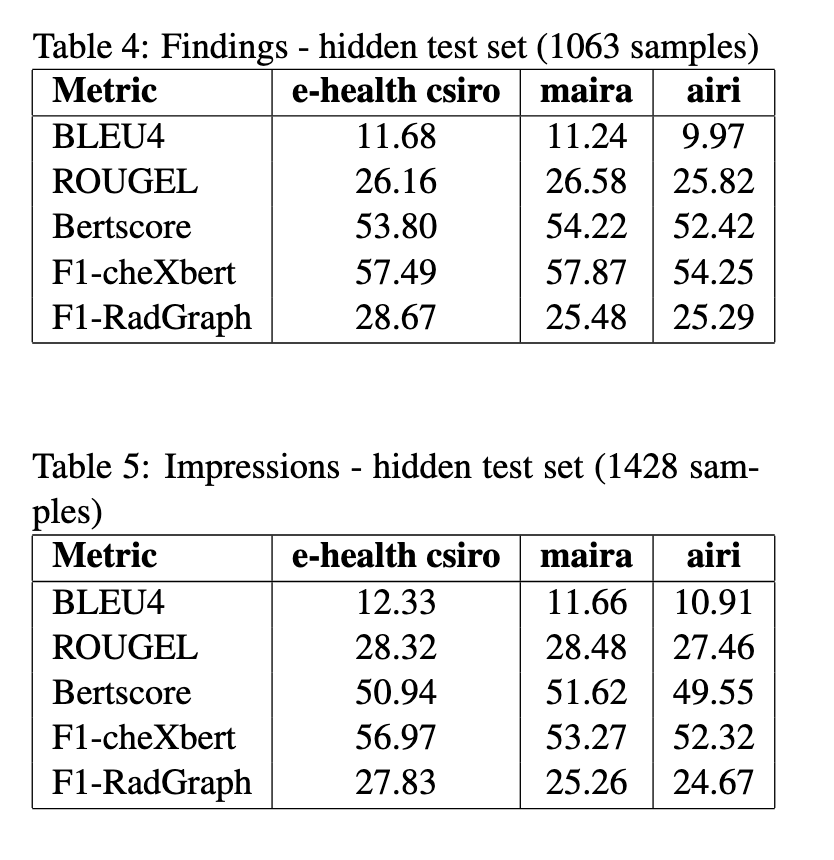
The system’s performance was impressive at all the chosen evaluation metrics; hence, it performs well in radiology report generation. On the hidden test sets, the model achieved a BLEU-4 score of 11.68 for findings and 12.33 for impressions, which reflected its precision in generating relevant textual content. In addition, the system attained an F1-CheXbert score of 57.49 for findings and 56.97 for impressions, indicating that it can capture critical medical observations accurately. The BERTScore for findings was 53.80, further validating the semantic consistency of the generated texts. Metrics like ROUGE-L and F1-RadGraph showed that the system performed better, with 26.16 and 28.67, respectively, for findings.
The researchers addressed long-standing challenges in radiology automation by leveraging a carefully curated dataset and specialized computational techniques. Their approach balanced computational efficiency with clinical precision, demonstrating the practical feasibility of such systems in real-world settings. Integrating domain-specific encoders and decoders proved instrumental in achieving high-quality outputs, setting a new benchmark for automated radiology reporting.
This research marks a major milestone in biomedical natural language processing. With the solution for the complexities of medical imaging, the AIRI and Skoltech team has demonstrated how AI can change radiology workflows. Their findings highlight the need to combine specific models with robust datasets for meaningful progress in automating diagnostic reporting.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.

The post This AI Paper Introduces a Novel DINOv2-LLaVA Framework: Advanced Vision-Language Model for Automated Radiology Report Generation appeared first on MarkTechPost.
Source: Read MoreÂ

