




Scaling the size of large language models (LLMs) and their training data have now opened up emergent capabilities that allow these models to perform highly structured reasoning, logical deductions, and abstract thought. These are not incremental improvements over previous tools but mark the journey toward reaching Artificial general intelligence (AGI).
Training LLMs to reason well is one of the biggest challenges in their creation. The approaches developed so far cannot nearly master multi-step problems or those where the solution must be coherent and logical. A principal cause is using human-annotated training data, which is expensive and inherently limited. Without enough annotated examples, these models fail to generalize across domains. This limitation presents a major barrier to exploiting LLMs for more complex, real-world problems requiring advanced reasoning.
Previous methods have found partial solutions to this problem. Researchers have explored supervised fine-tuning, reinforcement learning from human feedback (RLHF), and prompting techniques such as chain of thought. While these techniques improve LLMs’ capabilities, they are still strongly dependent on quality datasets and significant computational resources. Fine-tuning with reasoning examples or integrating step-by-step problem-solving trajectories has proved successful; however, the approaches remain computationally intensive and are not generally scalable to mass applications. Addressing these challenges, researchers began to concentrate more on methods for automated data construction and reinforcement learning frameworks that make minimal demands on human effort but maximize reasoning accuracy.
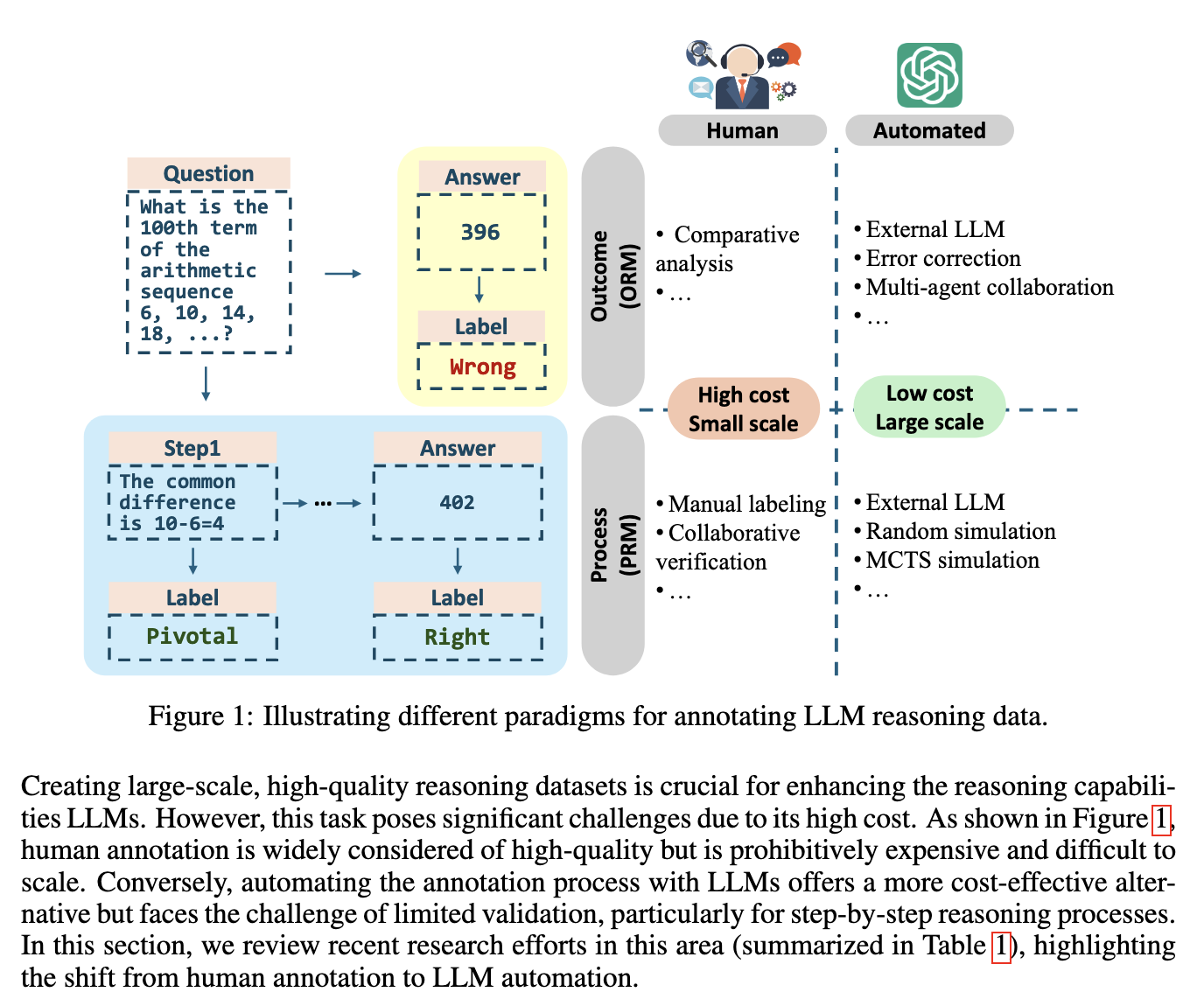
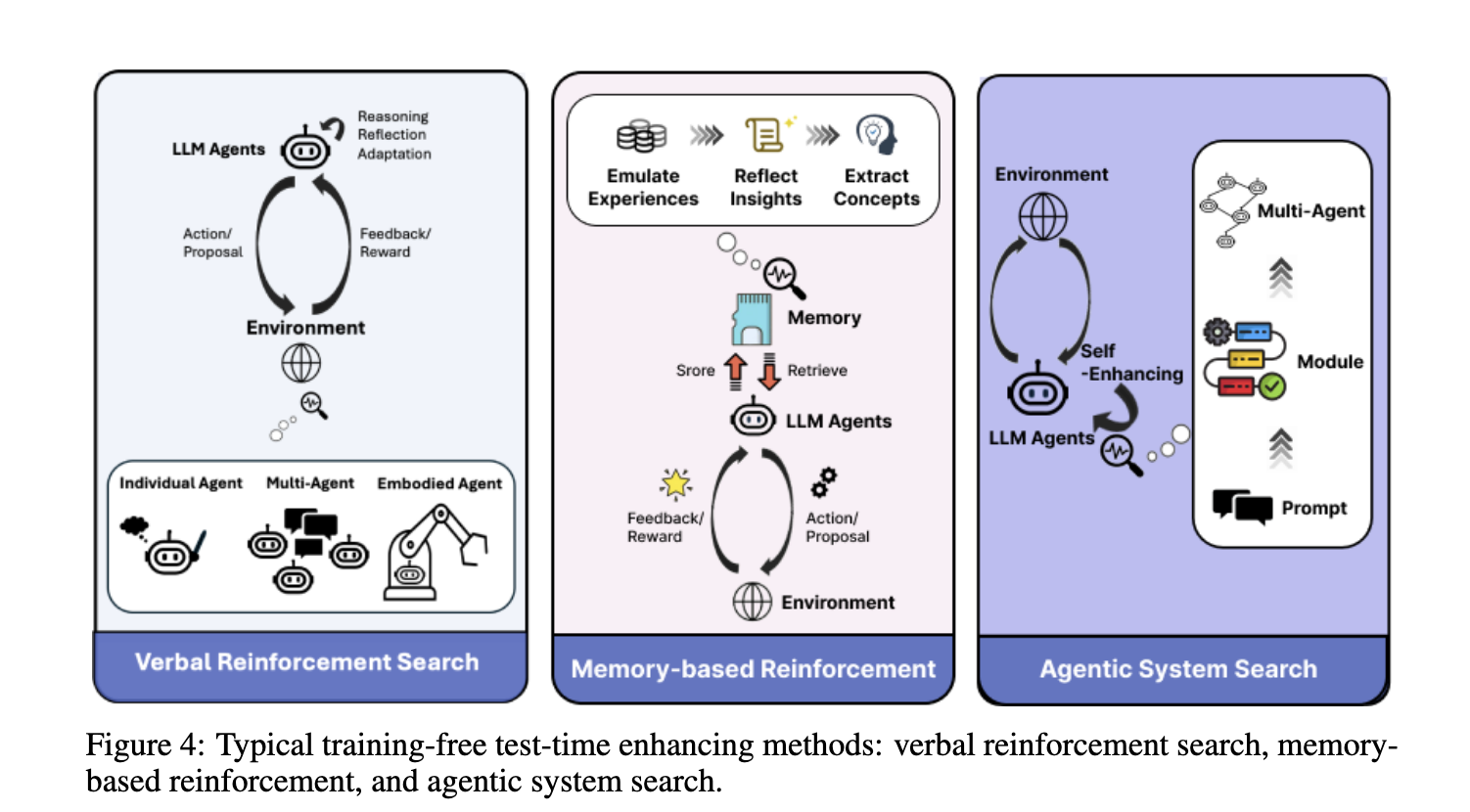
Researchers from Tsinghua University, Emory University, and HKUST introduced a reinforced learning paradigm for dealing with the challenges of training LLMs for reasoning tasks. Their approach uses Process Reward Models (PRMs) to guide intermediate steps within the reasoning process, significantly enhancing logical coherence and task performance. Using a combination of automated annotation with Monte Carlo simulations, the researchers have automatically generated high-quality reasoning data that does not rely on manual intervention. This innovative methodology eliminates reliance on human annotations about the data quality but enables models to perform advanced reasoning through iterative learning cycles. The reinforced learning method encompasses a variety of components, including PRM-guided automated reasoning trajectories and test-time reasoning.
PRMs provide step-level rewards centered around intermediate steps rather than final outcomes. The detailed guidance ensures the model can learn incrementally and refine its understanding during training. Test-time scaling further improves reasoning capabilities by dedicating more computation resources for deliberate thinking during inference. Techniques such as Monte Carlo Tree Search (MCTS) and self-refinement cycles are critical to this process, allowing the models to simulate and evaluate multiple reasoning paths efficiently. Performance results show that these methods work well.
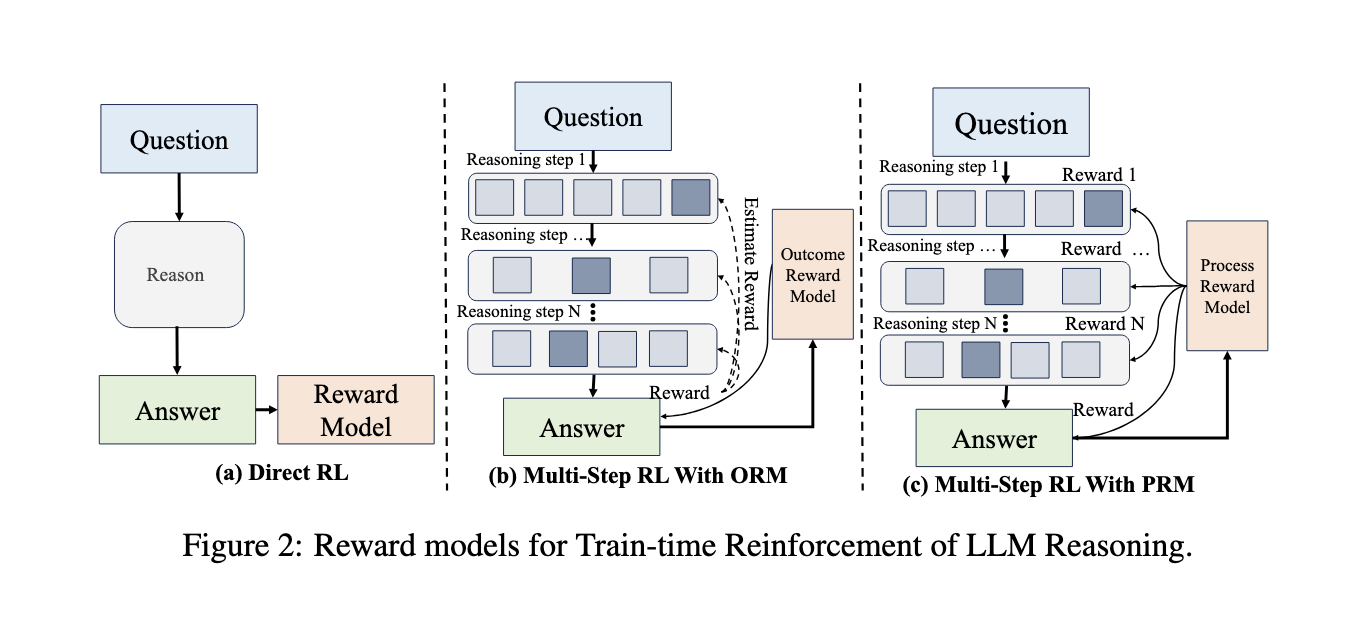
The models trained using this reinforced paradigm show significant improvement in reasoning benchmarks. The OpenAI o1 series, one of the most prominent implementations of such techniques, achieves an 83.3% success rate in competitive programming tasks by leveraging structured reasoning and logical deduction. The o1 model has also demonstrated PhD-level performance in mathematics, physics, and biology, scoring at gold-medal levels in the International Mathematics Olympiad. Systematic evaluations reveal that integrating step-level reasoning processes improves accuracy by 150% compared to earlier models. These results emphasize the ability of the model to decompose complex problems, synthesize interdisciplinary knowledge, and maintain consistency in long-horizon tasks.
The study showcases the promising perspective that LLMs can realize once endowed with advanced reinforcement learning methods and test-time scaling strategies. The cases of data annotation and the reduction of computational resources culminate in novel possibilities for reasoning-focused AI systems. This work enhances the state of LLMs and establishes a foundation for future exploration in creating models for handling highly complex tasks with minimal human intervention.
In summary, research points towards the transformational strength of the merge of reinforcement learning and test time scaling in building LLM. By addressing problems associated with traditional trAIning methods and deploying novel strategies of innovative design and application, such a model shows great promise as an effective creation for reasoning power. The methods presented by authors from Tsinghua University, Emory University, and HKUST are an enormous step in pursuing the desired goal of well-established AI and human-like reasoning systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.
 Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
The post This AI Paper Explores Reinforced Learning and Process Reward Models: Advancing LLM Reasoning with Scalable Data and Test-Time Scaling appeared first on MarkTechPost.
Source: Read MoreÂ

