




The study of artificial intelligence has witnessed transformative developments in reasoning and understanding complex tasks. The most innovative developments are large language models (LLMs) and multimodal large language models (MLLMs). These systems can process textual and visual data, allowing them to analyze intricate tasks. Unlike traditional approaches that base their reasoning skills on verbal means, multimodal systems attempt to mimic human cognition by combining textual reasoning with visual thinking and, therefore, could be used more effectively to solve more varied challenges.
The problem so far is that these models cannot interlink textual and visual reasoning together in dynamic environments. Models developed for reasoning perform well on text-based or image-based inputs but cannot execute simultaneously when both are input. Spatial reasoning tasks like maze navigation or the interpretation of dynamic layouts show weaknesses in these models. Integrated reasoning capabilities cannot be catered to within these models. Thus, it creates limitations in the models’ adaptability and interpretability, especially where the task is to understand and manipulate visual patterns and the instructions given in words.
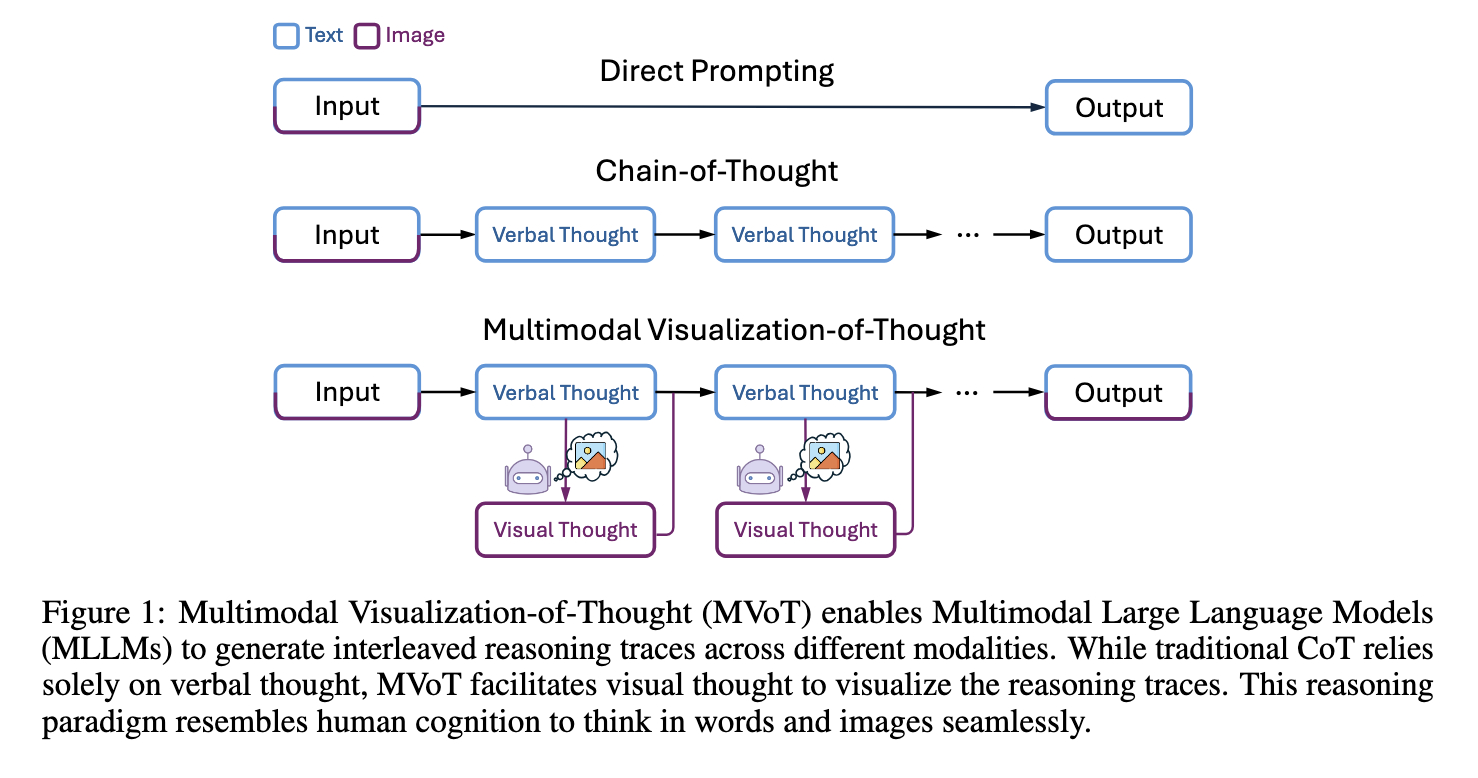
Several approaches have been proposed to deal with these issues. Chain-of-thought (CoT) prompting improves reasoning by producing step-by-step textual traces. It is inherently text-based and does not handle tasks requiring spatial understanding. Other approaches are visual input methods through external tools such as image captioning or scene graph generation, allowing models to process visual and textual data. While effective to some extent, these methods rely heavily on separate visual modules, making them less flexible and prone to errors in complex tasks.
Researchers from Microsoft Research, the University of Cambridge, and the Chinese Academy of Sciences introduced the Multimodal Visualization-of-Thought (MVoT) framework to address these limitations. This novel reasoning paradigm enables models to generate visual reasoning traces interleaved with verbal ones, offering an integrated approach to multimodal reasoning. MVoT embeds visual thinking capabilities directly into the model’s architecture, thus eliminating the dependency on external tools making it a more cohesive solution for complex reasoning tasks.

Using Chameleon-7B, an autoregressive MLLM fine-tuned for multimodal reasoning tasks, the researchers implemented MVoT. This method involves token discrepancy loss to close the representational gap between text and image tokenization processes for outputting quality visuals. MVoT processes multimodal inputs step-by-step through creating verbal and visual reasoning traces. For instance, in spatial tasks such as maze navigation, the model produces intermediate visualizations corresponding to the reasoning steps, enhancing both its interpretability and performance. This native visual reasoning capability, integrated into the framework, makes it more similar to human cognition, thus providing a more intuitive approach to understanding and solving complex tasks.
MVoT outperformed the state-of-the-art models in extensive experiments on multiple spatial reasoning tasks, including MAZE, MINI BEHAVIOR, and FROZEN LAKE. The framework reached a high accuracy of 92.95% on maze navigation tasks, which surpasses traditional CoT methods. In the MINI BEHAVIOR task that requires understanding interaction with spatial layouts, MVoT reached an accuracy of 95.14%, demonstrating its applicability in dynamic environments. In the FROZEN LAKE task, which is well-known for being complex due to fine-grained spatial details, MVoT’s robustness reached an accuracy of 85.60%, surpassing CoT and other baselines. MVoT consistently improved in challenging scenarios, especially those involving intricate visual patterns and spatial reasoning.
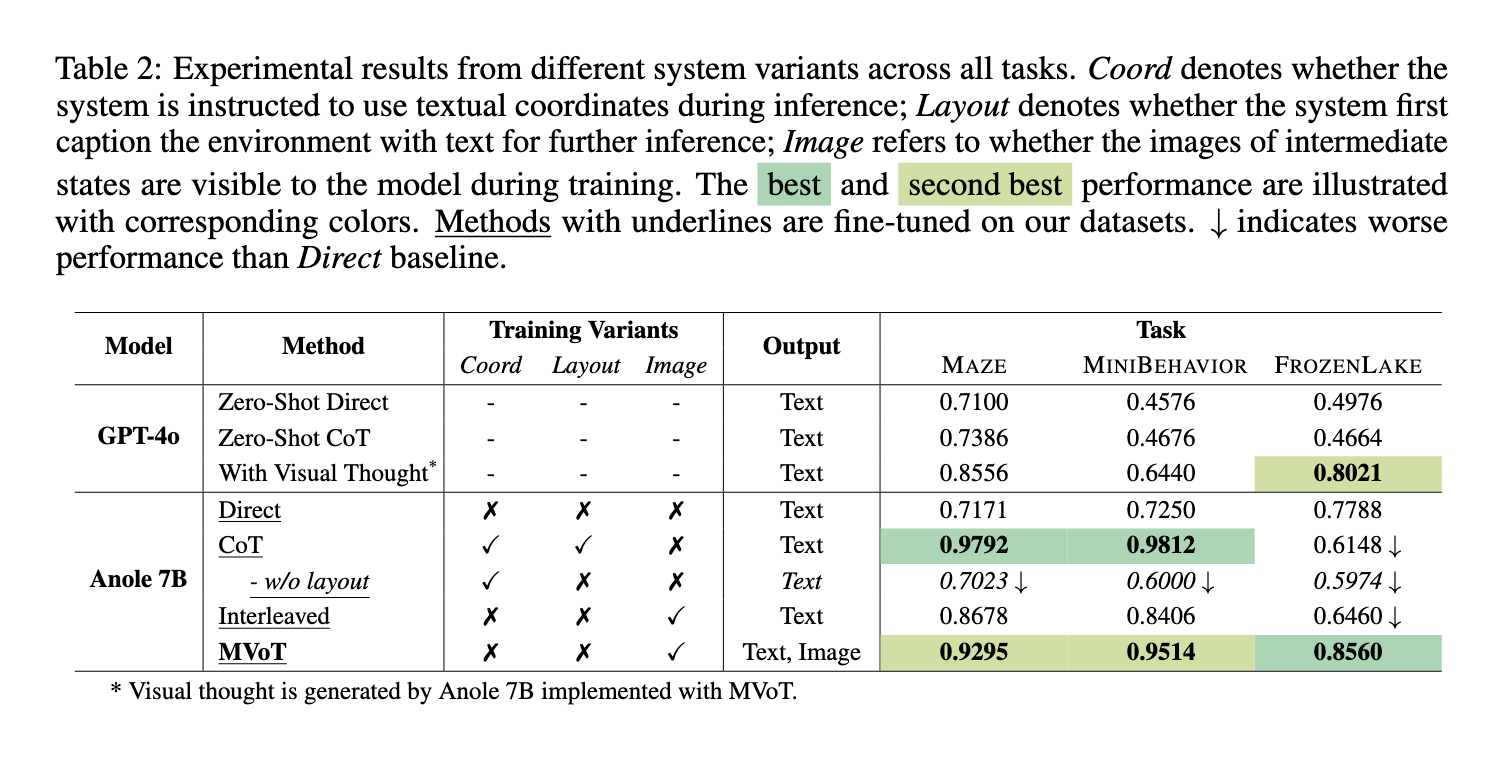
In addition to performance metrics, MVoT showed improved interpretability by generating visual thought traces that complement verbal reasoning. This capability allowed users to follow the model’s reasoning process visually, making it easier to understand and verify its conclusions. Unlike CoT, based only on the textual description, MVoT’s multimodal reasoning approach reduced errors caused by poor textual representation. For example, in the FROZEN LAKE task, MVoT sustained stable performance at increased complexity concerning its environment, thereby demonstrating robustness and reliability.

This study, therefore, redefines the scope of reasoning capabilities of artificial intelligence with MVoT by integrating text and vision into reasoning tasks. Using token discrepancy loss ensures visual reasoning aligns seamlessly with textual processing. This will bridge the critical gap in current methods. Superior performance and better interpretability will mark MVoT as a landmark step toward multimodal reasoning that can open doors to more complex and challenging AI systems in real-world scenarios.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.
 Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
The post Microsoft AI Research Introduces MVoT: A Multimodal Framework for Integrating Visual and Verbal Reasoning in Complex Tasks appeared first on MarkTechPost.
Source: Read MoreÂ
