")


Imagine having a personal chatbot that can answer questions directly from your documents—be it PDFs, research papers, or books. With Retrieval-Augmented Generation (RAG), this is not only possible but also straightforward to implement. In this tutorial, we’ll learn how to build a chatbot that interacts with your documents, like PDFs, using Retrieval-Augmented Generation (RAG). We’ll use Groq for language model inference, Chroma as the vector store, and Gradio for the user interface.
By the end, you’ll have a chatbot capable of answering questions directly from your documents, keeping context of your conversation, and providing concise, accurate answers.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is an AI architecture that enhances the capabilities of Large Language Models (LLMs) by integrating an information retrieval system. This system fetches relevant data from external sources, providing the LLM with grounded information to generate more accurate and contextually appropriate responses. By combining the generative abilities of LLMs with real-time data retrieval, RAG reduces inaccuracies and ensures up-to-date information in AI-generated content.
Prerequisites
- Python Installation: Ensure Python 3.9+ is installed on your system.
- Groq API Key: Sign up for a Groq account and generate an API key:
- Visit Groq Console.
- Navigate to API Keys and create a new key.
- Copy your API key for use in the project.
Dependencies: Install the required libraries:
pip install langchain langchain-community langchain-groq gradio sentence-transformers PyPDF2 chromadbThese libraries will help with language processing, building the user interface, model integration, PDF handling, and vector database management.
Downloading the PDF Resource
For this tutorial, we’ll use a publicly available PDF containing information about diseases, their symptoms, and cures. Download the PDF and save it in your project directory (you are free to use any pdf).
Step 1: Extracting Text from the PDF
We’ll use PyPDF2 to extract text from the PDF:
from PyPDF2 import PdfReader
def extract_text_from_pdf(pdf_path):
reader = PdfReader(pdf_path)
text = ""
for page in reader.pages:
text += page.extract_text()
return text
pdf_path = 'diseases.pdf' # Replace with your PDF path
pdf_text = extract_text_from_pdf(pdf_path)Step 2: Split the Text into Chunks
Long documents are divided into smaller, manageable chunks for processing.
from langchain.text_splitter import RecursiveCharacterTextSplitter
def split_text_into_chunks(text, chunk_size=2000, chunk_overlap=200):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
return text_splitter.split_text(text)
text_chunks = split_text_into_chunks(pdf_text)Step 3: Create a Vector Store with Chroma
We’ll embed the text chunks using a pre-trained model and store them in a Chroma vector database.
from langchain.embeddings import SentenceTransformerEmbeddings
from langchain.vectorstores import Chroma
embedding_model = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
vector_store = Chroma(
collection_name="disease_info",
embedding_function=embedding_model,
persist_directory="./chroma_db"
)
vector_store.add_texts(texts=text_chunks)Step 4: Initialize the Groq Language Model
To use Groq’s language model, set your API key and initialize the ChatGroq instance.
import os
from langchain_groq import ChatGroq
os.environ["GROQ_API_KEY"] = 'your_groq_api_key_here' # Replace with your API key
llm = ChatGroq(model="mixtral-8x7b-32768", temperature=0.1)Step 5: Create the Conversational Retrieval Chain
With LangChain’s ConversationalRetrievalChain, we can link the language model and the vector database.
from langchain.chains import ConversationalRetrievalChain
retrieval_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=vector_store.as_retriever(topk=3),
return_source_documents=True
)Step 6: Implement the Chatbot Logic
We define the logic for maintaining conversation history and generating responses.
conversation_history = []
def get_response(user_query):
response = retrieval_chain({
"question": user_query,
"chat_history": conversation_history
})
conversation_history.append((user_query, response['answer']))
return response['answer']Step 7: Build the User Interface with Gradio
Finally, create a Gradio interface to interact with the chatbot.
import gradio as gr
def chat_interface(user_input, history):
response = get_response(user_input)
history.append((user_input, response))
return history, history
with gr.Blocks() as demo:
chatbot = gr.Chatbot()
state = gr.State([])
with gr.Row():
user_input = gr.Textbox(show_label=False, placeholder="Enter your question...")
submit_btn = gr.Button("Send")
submit_btn.click(chat_interface, inputs=[user_input, state], outputs=[chatbot, state])
Running the Code
Save the script as app.py and run
python app.pyHurray! You are done. The Gradio interface will launch, allowing you to chat with your document.
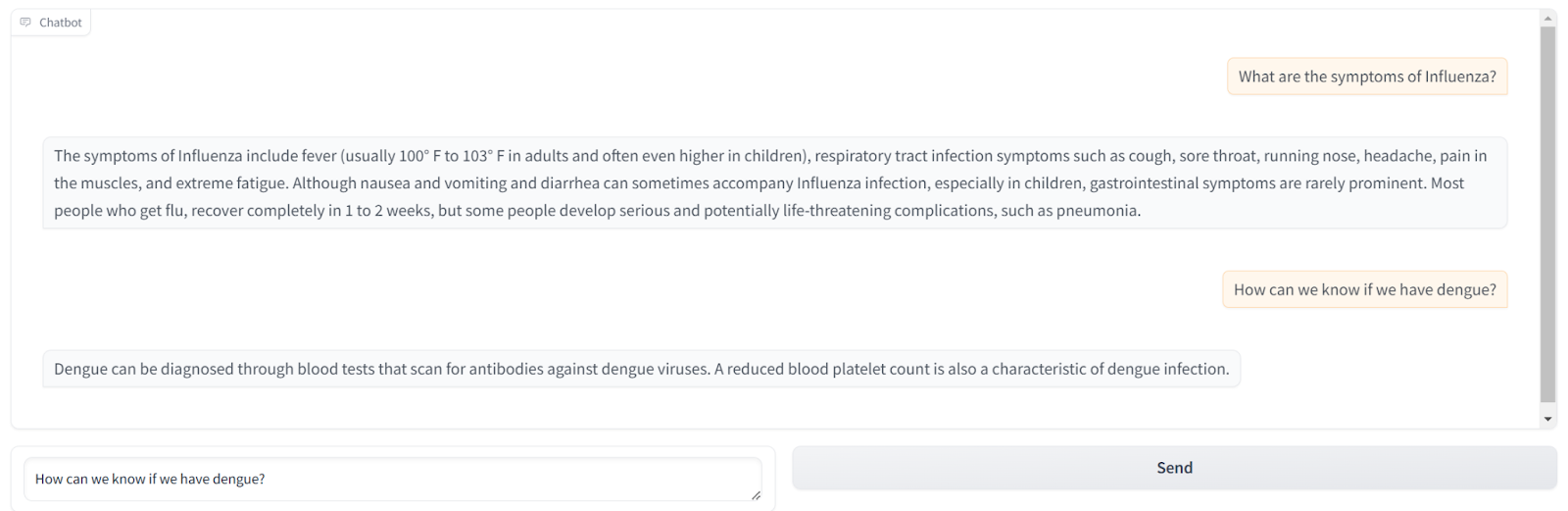
But why stop here? You can go further by trying to build any of the following functionalities in the chatbot.
- Enhanced Vector Store: Use other vector databases like Milvus or Pinecone for scalability.
- Fine-tuned Models: Experiment with fine-tuned Groq models for domain-specific accuracy.
- Multi-Document Support: Extend the system to handle multiple documents.
- Better Context Handling: Refine conversational logic to better manage longer chat histories.
- Custom UI: Design a more polished user interface with advanced styling and features.
Congratulations! You’ve successfully built a document-based chatbot using Groq and LangChain. Experiment with improvements and build something amazing! 
Resources:
- https://nios.ac.in/media/documents/SrSec314NewE/Lesson-29.pdf
- LangChain (https://www.langchain.com/)
- Groq (https://groq.com/)
Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.
 Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
The post Chat with Your Documents Using Retrieval-Augmented Generation (RAG) appeared first on MarkTechPost.
Source: Read MoreÂ

