




Large language models (LLMs) have recently been enhanced through retrieval-augmented generation (RAG), which dynamically integrates external knowledge sources to improve response quality for open-domain questions and specialized tasks. However, RAG systems face several significant challenges that limit their effectiveness. The real-time retrieval process introduces latency in response generation, while document selection and ranking errors can compromise the quality of outputs. Moreover, integrating separate retrieval and generation components increases system complexity, requiring careful calibration and substantial maintenance overhead. These limitations have prompted researchers to explore alternative approaches, that can maintain the benefits of knowledge augmentation.
Various research approaches have explored solutions to the challenges faced by RAG systems using advances in long-context LLMs. These models can process and reason over extensive textual inputs within a single inference step, making them effective for document comprehension, multi-turn dialogue, and text summarization tasks. State-of-the-art models like GPT-4, GPT-o1, and Claude 3.5 have demonstrated superior performance in processing large amounts of retrieved data compared to traditional RAG systems. While some methods have utilized precomputed KV caching to improve efficiency, these solutions still struggle with retrieval failures and require complex position ID rearrangements, indicating the need for a more robust approach to knowledge augmentation.
Researchers from the Department of Computer Science, National Chengchi University, Taipei, Taiwan, and the Institute of Information Science Academia Sinica, Taipei, Taiwan have proposed a novel cache-augmented generation (CAG) method that utilizes extended context windows of modern LLMs to eliminate the need for real-time retrieval. The approach preloads all relevant documents into the LLM’s extended context and caches runtime parameters when the knowledge base is of manageable size. This innovative method allows the model to generate responses using preloaded parameters without additional retrieval steps, effectively addressing the key challenges of retrieval latency and errors while maintaining high context relevance and achieving comparable or superior results to traditional RAG systems.
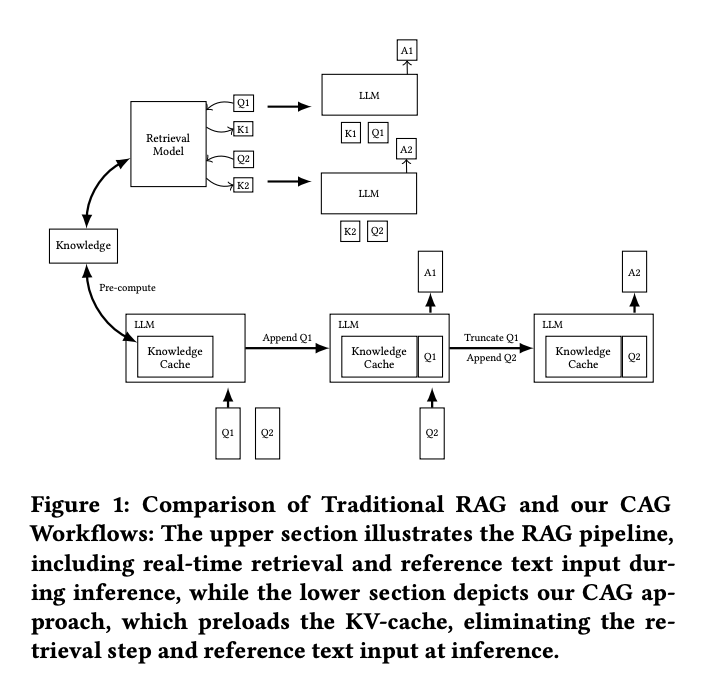
The CAG framework utilizes long-context LLMs to achieve retrieval-free knowledge integration, overcoming the limitations of traditional retrieval-augmented generation (RAG) systems. It addresses computational inefficiencies in real-time retrieval by preloading external knowledge sources and precomputing a key-value cache. The CAG framework’s architecture operates in three phases: External Knowledge Preloading, Inference, and Cache Reset. Moreover, with advancements in LLMs, the framework’s ability to process larger knowledge collections and extract relevant information from extended contexts will improve. This makes the CAG a versatile and robust solution for handling complex knowledge-intensive tasks across diverse applications.
Experimental results show the superior performance of CAG compared to traditional RAG systems, with the approach achieving higher BERTScore metrics across most test scenarios. Its effectiveness is evident in its ability to eliminate retrieval errors through comprehensive context preloading, enabling holistic reasoning over all relevant information. While dense retrieval methods like OpenAI Indexes outperform sparse retrieval approaches such as BM25, both fall short of CAG’s capabilities due to their dependence on retrieval accuracy. Further, performance comparisons with standard in-context learning reveal that CAG significantly reduces generation time, especially with longer reference texts due to its efficient KV-cache preloading mechanism.
In conclusion, researchers provide a significant advancement, in knowledge integration for LLMs through the CAG framework, presenting an alternative to traditional RAG systems for specific use cases. While the primary focus has been on eliminating retrieval latency and associated errors, the findings suggest the potential for hybrid implementations that combine preloaded contexts with selective retrieval mechanisms. This approach effectively balances efficiency with adaptability in scenarios that require comprehensive context understanding and flexibility for specific queries. As LLMs evolve with expanded context capabilities, the CAG framework establishes a foundation for more efficient and reliable knowledge-intensive applications.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.
 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
The post Cache-Augmented Generation: Leveraging Extended Context Windows in Large Language Models for Retrieval-Free Response Generation appeared first on MarkTechPost.
Source: Read MoreÂ

