




The generation of synthetic tabular data has become increasingly crucial in fields like healthcare and financial services, where privacy concerns often restrict the use of real-world data. While autoregressive transformers, masked transformers, and diffusion models with transformers, have shown significant success in generating high-quality synthetic data with strong fidelity, utility, and privacy guarantees, they face important limitations. Unlike their counterparts in computer vision and natural language processing, which uses domain-specific priors to enhance performance, current transformer models for tabular data generation largely ignore these valuable inductive biases. Moreover, Tabular data generation models have yet to incorporate such domain-specific architectural enhancements effectively.
Early approaches to tabular data generation depend heavily on MLPs and CNNs as backbone architectures, utilizing GANs and VAEs as generation methods. The field then progressed to transformer-based solutions, introducing models like TabMT, which uses masked transformers with ordered embedding, and TabSyn, which employs diffusion models in latent space. While these approaches demonstrated improved utility and fidelity, they failed to account for crucial inductive biases specific to tabular data, such as non-smoothness and low-correlated features. In parallel, tree-based gradient boosting algorithms like XGBoost, LightGBM, and CatBoost have dominated traditional tabular data tasks due to their natural ability to understand feature relationships.
Researchers from the Asian Institute of Digital Finance, National University of Singapore, Betterdata AI, Singapore, Tufts University, Massachusetts, United States, and the Department of Electrical and Computer Engineering, Singapore have proposed TabTreeFormer, an innovative hybrid transformer architecture. The model integrates a tree-based component that preserves tabular-specific inductive biases, focusing on non-smooth and low-correlated patterns through its discrete and non-rotationally invariant design. A key innovation is the dual-quantization tokenizer, which effectively captures multimodal continuous distributions and enhances the learning of numerical value distributions. This novel architecture improves data generation quality and shows a significant reduction, in model size by limiting vocabulary size and sequence length.
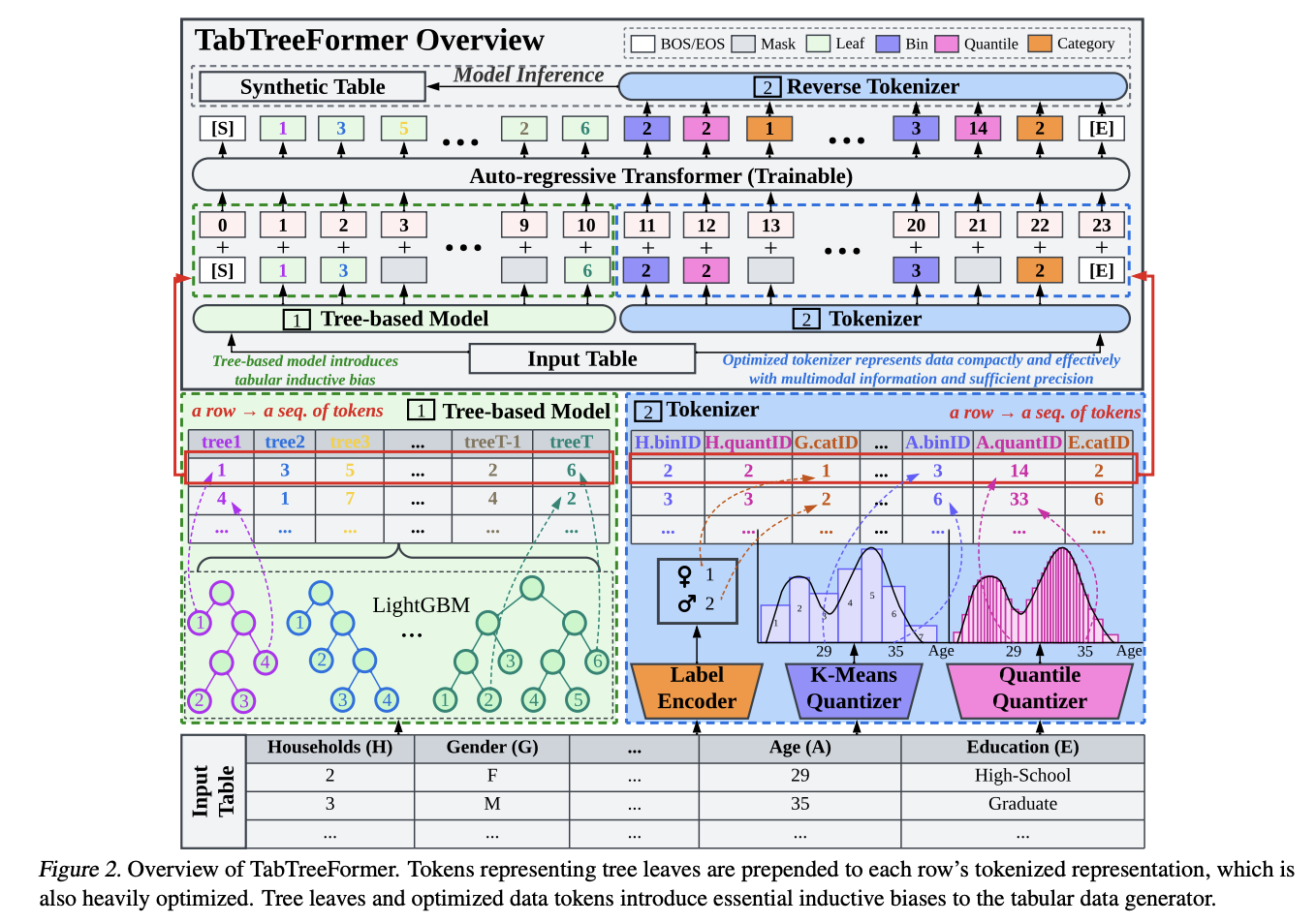
The TabTreeFormer architecture integrates LightGBM as its tree-based component, with hyperparameters optimized using Optuna, and employs Distill-GPT2 as its transformer backbone. The model comes in three configurations: Small (1M parameters), Medium (5M parameters), and Large (40M parameters), offering flexibility in deployment based on computational resources and performance requirements. The implementation was tested on an NVIDIA RTX 4090 and evaluated across 10 diverse datasets from OpenML, including adult, bank, breast, credit, diabetes, iris, etc. The model’s performance was benchmarked against a comprehensive range of existing methods, including ARF, CTAB-GAN+, CTGAN, TVAE, TabDDPM, TabSyn, GReaT, and REaLTabFormer.
TabTreeFormer shows exceptional performance across multiple evaluation metrics. In terms of fidelity, it achieves comparable results in marginal density distribution (Shape) while showing superior capability in capturing multimodal distributions compared to other autoregressive transformers. The model significantly outperforms all baselines in pair-wise correlation (Trend) metrics, excelling in handling correlations involving categorical features and showing marked improvement on datasets with larger feature sets. In utility evaluations measured by Machine Learning Efficiency (MLE), TabTreeFormer-S matches the performance of leading baselines like REaLTabFormer and TabSyn. At the same time, the Medium and Large versions surpass them by approximately 40%.
In this paper, researchers introduced TabTreeFormer which represents a significant advancement in synthetic tabular data generation, successfully combining tree-based models’ inductive biases with transformer architecture while introducing an innovative dual-quantization tokenizer for optimized numerical value representation. The comprehensive evaluation across multiple datasets and metrics shows its superior performance in fidelity, utility, and privacy compared to existing approaches. The model’s ability to capture complex data distributions and inter-feature relationships while maintaining a smaller footprint makes it a promising solution for practical applications in privacy-preserving data generation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
The post TabTreeFormer: Enhancing Synthetic Tabular Data Generation Through Tree-Based Inductive Biases and Dual-Quantization Tokenization appeared first on MarkTechPost.
Source: Read MoreÂ

