
Top News
Google unveils a next-gen AI reasoning model

Google has introduced Gemini 2.5, a new generation of AI reasoning models, with the first release being Gemini 2.5 Pro Experimental. This multimodal reasoning AI model, available on Google AI Studio and the Gemini app, is touted as Google’s most intelligent model to date. The model uses additional computing power and time to fact-check and reason through problems before providing an answer, a technique that has proven beneficial in math and coding tasks. Gemini 2.5 Pro has outperformed several leading AI models in benchmarks, excelling in creating visually compelling web apps and coding applications. However, it underperformed Anthropic’s Claude 3.7 Sonnet in a software development abilities test. The model can process approximately 750,000 words at once, with plans to double this capacity soon.
OpenAI rolls out image generation powered by GPT-4o to ChatGPT

OpenAI has integrated a new image generation feature, known as “Images in ChatGPT”, into its ChatGPT platform. This feature, powered by GPT-4o, allows users to generate images within the chat itself and is available across all subscription tiers. The new model offers significant improvements in “binding”, the ability of AI image generators to maintain correct relationships between attributes and objects, and text rendering, making it easier to generate coherent text without typos on an image. The system uses an autoregressive approach, generating images sequentially from left to right and top to bottom, which may contribute to its improved text rendering and binding capabilities. Despite taking longer to generate images, OpenAI believes the enhanced quality and capabilities justify the additional wait time.
Tencent’s Hunyuan T1 AI reasoning model rivals DeepSeek in performance and price
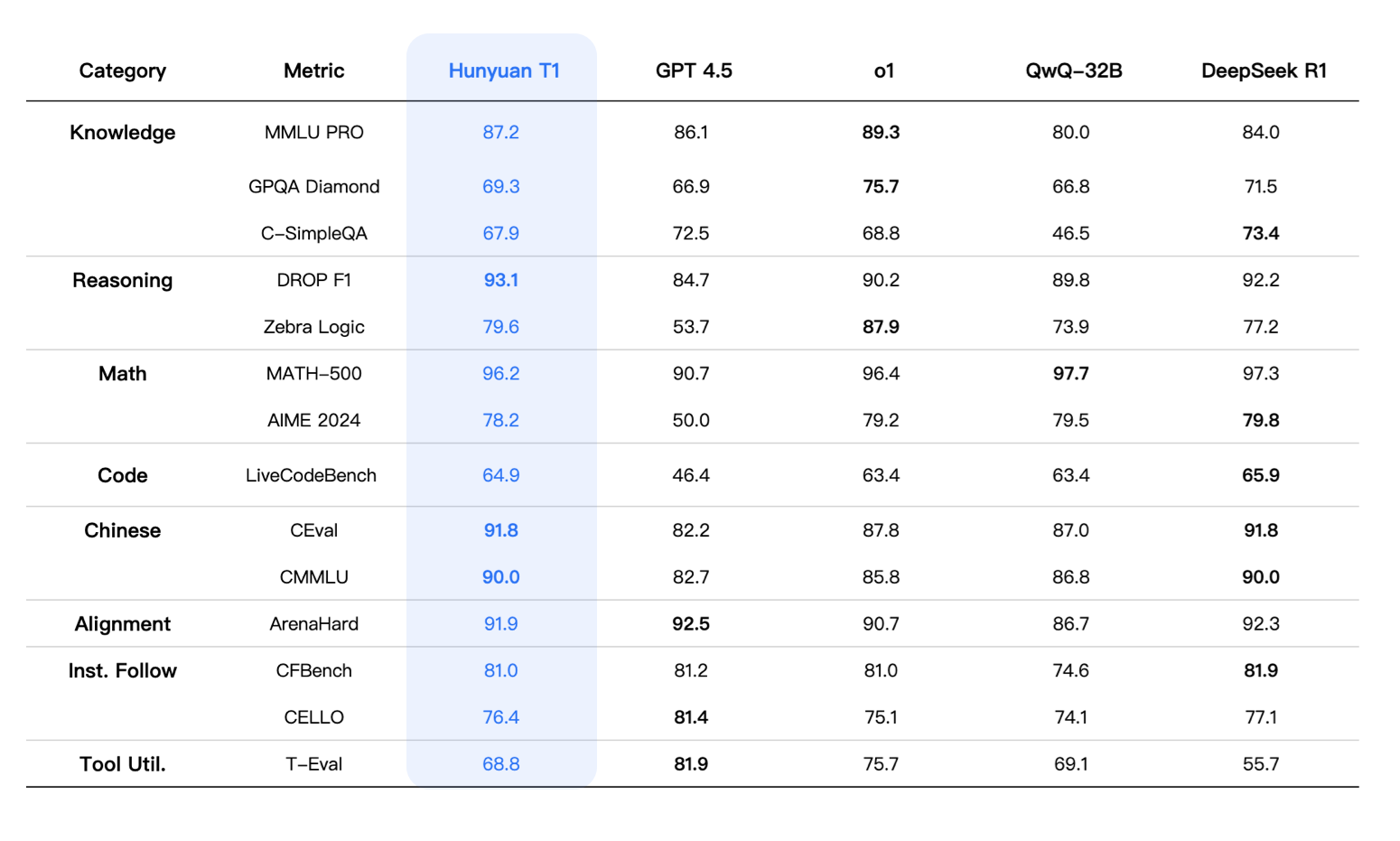
Tencent has launched its Hunyuan T1 AI reasoning model, which uses large-scale reinforcement learning, similar to DeepSeek’s R1 reasoning model. The T1 model scored 87.2 points on the Massive Multitask Language Understanding (MMLU) Pro benchmark, surpassing DeepSeek-R1’s 84 points but falling short of OpenAI’s o1’s 89.3 points. The T1 model also performed well in other benchmarks, including the American Invitational Mathematics Examination (AIME) 2024 and the C-Eval suite evaluation for Chinese language capabilities. In terms of pricing, T1 charges 1 yuan per 1 million tokens of input and 4 yuan per million tokens of output, competitive with DeepSeek’s pricing. Tencent’s T1 model uses a hybrid architecture combining Google’s Transformer and Mamba, which reportedly reduces training and inference costs by cutting memory usage.
Judge Allows ‘New York Times’ Copyright Case Against OpenAI to Go Forward

A federal judge has allowed a copyright lawsuit by The New York Times against OpenAI to proceed. The lawsuit alleges that OpenAI exploited the newspaper’s content without permission or payment to train its artificial intelligence service, ChatGPT. The New York Times, along with other publishers, argue that OpenAI violated copyright laws by using their articles as a significant source of copyrighted text. OpenAI, however, maintains that its mass data scraping is protected under the “fair use” legal doctrine, which allows for material to be reused without permission in certain instances. The case, which is yet to have a trial date set, could have significant implications for both the news industry and the future of AI tools.
Other News
Tools

New Reve Image Generator Beats AI Art Heavyweights MidJourney and Flux at a Penny Per Image – Reve Image 1.0, an affordable AI image generator, excels in prompt adherence and visual quality, offering a cost-effective alternative to established tools like MidJourney and Flux, despite lacking some advanced editing features.
Google is rolling out Gemini’s real-time AI video features – Google has begun implementing Gemini’s real-time AI video features for some Google One AI Premium subscribers, allowing the AI to interpret screens and camera feeds and answer questions in real-time.
Alibaba Releases Qwen2.5 Omni, Adds Voice and Video Modes to Qwen Chat – Alibaba’s Qwen2.5-Omni-7B model introduces advanced multimodal capabilities, enabling real-time voice and video chat in Qwen Chat, and is open-sourced under the Apache 2.0 license.
Ideogram presents version 3.0 of its AI image generation system – Ideogram’s version 3.0 enhances AI image generation with a style reference system, improved image quality, and new editing tools, positioning it as a leader in photorealism and professional image creation.
DeepSeek V3-0324 tops non-reasoning AI models in open-source first – DeepSeek V3-0324’s achievement as the top non-reasoning AI model underscores the growing competitiveness of open-source AI solutions against proprietary systems in real-time applications.
OpenAI adopts rival Anthropic’s standard for connecting AI models to data – OpenAI plans to integrate Anthropic’s Model Context Protocol (MCP) into its products to enhance AI models’ ability to access and utilize data from various sources, fostering better responses and broader application support.
Business
")
Pony.ai wins first permit for fully driverless taxi operation in the center of China’s Silicon Valley – Pony.ai has become the first company in China to receive a permit to charge for fully driverless taxi rides in Shenzhen’s Nanshan district, marking a significant milestone in the development of its robotaxi business.
Netflix’s Reed Hastings Gives $50 Million to Bowdoin for A.I. Program – Reed Hastings has donated $50 million to Bowdoin College to establish a research initiative focused on exploring the risks and consequences of artificial intelligence and its impact on humanity.
Apple Joins AI Data Center Race After Siri Mess – Apple is investing in AI data centers with a $1 billion order for Nvidia systems, partnering with Dell and Super Micro Computer, after delays and challenges with its AI-enabled Siri prompted a strategic shift.
Research
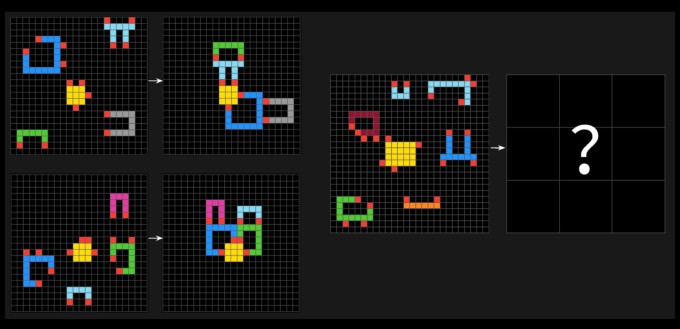
A new, challenging AGI test stumps most AI models – ARC-AGI-2, a new test by the Arc Prize Foundation, challenges AI models to solve visual pattern puzzles efficiently, revealing their limitations in general intelligence compared to human performance.
Inside-Out: Hidden Factual Knowledge in LLMs – A framework reveals that large language models encode more factual knowledge internally than they express externally, highlighting limitations in their generation capabilities and the challenges of improving performance through repeated answer sampling.
Reasoning to Learn from Latent Thoughts – Explicitly modeling and inferring latent thoughts during language model pretraining can enhance data efficiency and improve performance, especially in data-constrained environments.
Challenging the Boundaries of Reasoning: An Olympiad-Level Math Benchmark for Large Language Models – OlymMATH is a new bilingual benchmark designed to evaluate the mathematical reasoning capabilities of large language models using Olympiad-level problems, revealing significant challenges and performance gaps, especially in multilingual contexts.
Variance Control via Weight Rescaling in LLM Pre-training – Introducing the Layer Index Rescaling and Target Variance Rescaling techniques, the study demonstrates improved downstream task performance and reduced activation extremes in LLM pre-training through better variance management.
Qwen2.5-Omni Technical Report – Qwen2.5-Omni is an advanced multimodal model that excels in processing and generating text and speech across various modalities using innovative architectures like Thinker-Talker and TMRoPE, achieving state-of-the-art results on benchmarks.
Video-T1: Test-Time Scaling for Video Generation – Video-T1 introduces a framework for test-time scaling in video generation, enhancing video quality by expanding the search space during inference, with the Tree-of-Frames (ToF) method offering efficient computation and significant improvements across various video generation models.
Wan: Open and Advanced Large-Scale Video Generative Models – Wan is an open-source suite of advanced video generative models that excels in performance, efficiency, and versatility, offering significant improvements in video generation through innovative techniques and scalable pre-training strategies.
Lumina-Image 2.0: A Unified and Efficient Image Generative Framework – Lumina-Image 2.0 introduces a unified text-to-image generative framework with a novel joint self-attention mechanism and a dedicated captioning system, significantly enhancing image generation fidelity and efficiency.
Concerns

ChatGPT is turning everything into Studio Ghibli art — and it got weird fast – OpenAI’s “Images for ChatGPT” allows users to generate Studio Ghibli-style art, leading to controversial creations and raising concerns about copyright and ethical use.
Brainrot’ AI on Instagram Is Monetizing the Most Fucked Up Things You Can Imagine (and Lots You Can’t) – AI-generated content on Instagram is gaining popularity by monetizing shockingly disturbing and offensive imagery, including racist and sexualized depictions.
Policy
U.S. blacklists over 50 Chinese companies in bid to curb Beijing’s AI, chip capabilities – The U.S. has blacklisted over 50 Chinese tech companies to restrict their access to advanced AI and computing technologies, citing national security concerns and their alleged support of China’s military advancements.
Anthropic Scores Win in AI Copyright Dispute With Record Labels – Anthropic scored a win this week after a U.S. court denied an injunction that Universal Music Group and other record labels had sought to prevent the artificial-intelligence company from using copyrighted lyrics to train its AI models
Source: Read MoreÂ

