


Amazon Aurora, a relational database service from Amazon Web Services (AWS), provides unparalleled high performance and availability at global scale, making it a preferred choice for organizations seeking a competitive database solution. As a database built for the cloud, Aurora is engineered to utilize cloud infrastructure capabilities, offering enterprise-level resilience, performance, and scalability for two of the most trusted open source database engines: MySQL and PostgreSQL. A key factor in the success of Aurora is its innovative architecture, which features a decoupled storage cluster distributed across multiple Availability Zones, resulting in a unique and resilient solution while reducing overall costs. While customers often anticipate cost savings when migrating from commercial databases to Aurora, many are pleasantly surprised to discover similar financial advantages when transitioning from self-managed MySQL and PostgreSQL.
In this post, we highlight often overlooked architectural designs and the inherent features of Aurora that optimize costs when deploying an open source database. The following sections examine various use cases, contrasting typical self-managed database configurations and their associated costs with the equivalent solution on Aurora, highlighting potential cost savings and operational efficiencies. We provide detailed cost comparisons based on the specific criteria defined in each use case using on-demand pricing in the US East (Ohio) region, and they are valid as of the date when this post was published. We encourage readers to consult the AWS pricing calculator or their account teams for current rates and personalized cost analyses.
Use case: Fundamental resilient database architecture with scaled reads
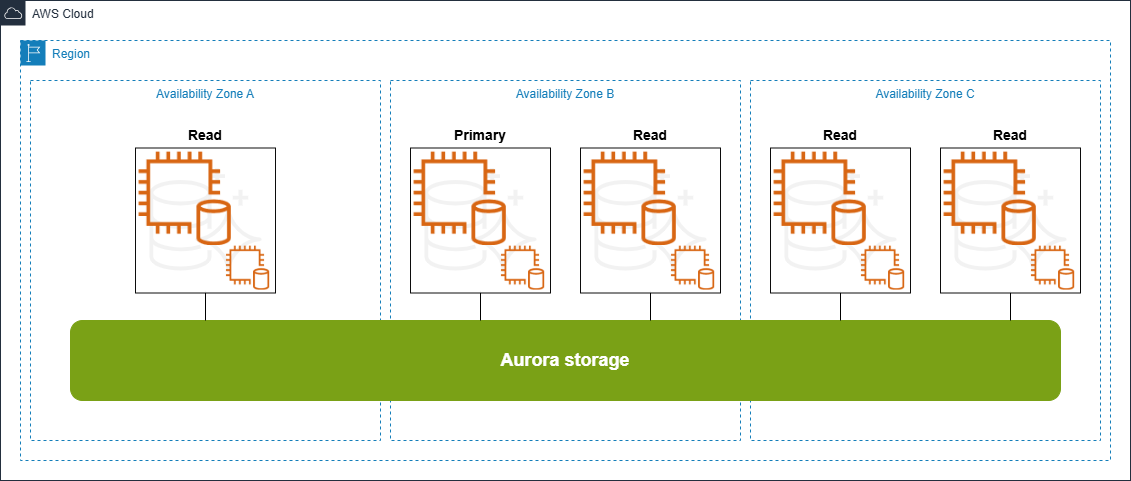
One of the most common use cases is based on a fundamental resilient architecture with scaled reads. The below self-managed architecture provides for a primary instance serving read/write traffic, a secondary logical replica that serves dual purposes – offering high availability with a low recovery point objective (RPO) while also acting as a replication source for downstream read replicas, and two read-only instances where read traffic can be diverted and scaled horizontally. This topology optimizes read scalability by distributing read workloads across multiple replicas while avoiding replication overhead on the primary, as the secondary replica handles the replication stream to downstream read replicas. The secondary replica can be promoted to primary during failover scenarios, maintaining business continuity, while the read replicas continue to serve read traffic, now replicating from the newly promoted primary. This architecture specifically uses the secondary instance as the failover target, as industry practices typically avoid using read replicas for failover in MySQL and PostgreSQL due to potential replication lag and data loss during the promotion process. This limitation necessitates the additional secondary instance, effectively increasing the overall cost of the solution.
Self-managed architecture:

The following Amazon Aurora architecture demonstrates how the same workload can be maintained with similar or improved performance while simplifying architecture and reducing resources, ultimately lowering costs. Aurora’s architecture incorporates specific features designed to enhance availability and facilitate disaster recovery. Unlike traditional self-managed open source databases, where achieving zero RPO typically increases both costs and performance overhead, Aurora inherently provides zero RPO failover capabilities. This is achieved through its innovative design, which allows read replicas to serve as high availability failover targets without additional configuration or performance impact.
Aurora architecture:

In this use case, this architectural advantage eliminates the need for a dedicated secondary instance solely for failover replication purposes. As a result, by migrating from the self-managed architecture to Aurora, the cluster footprint is reduced from four nodes to three. While this reduction in compute resources does offer some cost savings, it’s not the primary source of economic benefit in this scenario. The majority of cost efficiencies come from Aurora’s revolutionary storage architecture.
In contrast to traditional database setups where each node typically has its own independent storage containing a separate copy of the data, replicated from the source instance, Aurora employs a fundamentally different approach. While the self-managed architecture not only decreases performance capacity due to replication overhead, it also quadruples the storage costs in this use case. In contrast, all Aurora instances—both primary and read replicas—connect to the same shared storage volume. This Aurora storage cluster inherently provides resilience by distributing six copies of data across three Availability Zones. Customers are then charged for only a single copy of the data, effectively reducing the storage cost in this architecture from four to one.
Assuming similar instance types (r6g.xlarge, db.r6g.xlarge) between the self-managed and Aurora architectures, with 2 TB of io2 provisioned input/output operations per second (IOPS) SSD storage at 64,000 IOPS in the self-managed architecture and Aurora I/O-Optimized (a storage option designed for improved price performance and predictability for I/O-intensive applications) for the Aurora architecture, the cost differences become apparent. Let’s compare the monthly costs of the self-managed architecture versus the Aurora solution:
| Architecture | # DB Nodes (w/ writer) |
Instance Type | Storage Size per Volume |
# Storage Volumes |
Total Cost |
|---|---|---|---|---|---|
| Self-Managed | 4 | r6g.xlarge | 2 Tb | 4 | $15,756.67 |
| Amazon Aurora | 3 | db.r6g.xlarge | 2 Tb | 1 | $1,939.05 |
As we can see, the self-managed architecture, requiring four compute nodes and separate storage for each, totals $15,756.67 per month. In contrast, the Aurora solution with three compute nodes and unified storage comes to $1,939.05 per month, representing an 87.7% reduction in costs. This reduction is driven by Aurora’s efficient storage architecture, which eliminates the need for redundant storage copies while maintaining high availability and performance.
While not the focus of this blog, it’s worth mentioning Amazon Relational Database Service (Amazon RDS), a managed database service that simplifies database administration tasks. RDS Multi-AZ with two readable standbys eliminates the need for a dedicated secondary/standby instance. While this deployment option requires independent storage volumes, each containing a separate copy of the data, it provides a robust high-availability solution. Aurora’s unique storage architecture offers additional cost optimization benefits through its shared storage model, which is why we’re focusing on Aurora’s capabilities in this post.
Use case: Variable read loads
Now let’s examine a scenario where applications experience fluctuations in read traffic, with peak loads potentially requiring considerably more capacity than the baseline resilient architecture can efficiently provide. The following self-managed architectural design manages variable read traffic through four read-only instances. This configuration is sized for peak demand periods, a standard practice in traditional architectures. The setup uses pre-provisioned resources that handle periodic surges in read traffic but remain underutilized during normal operations. This static approach ensures readiness for high-traffic scenarios at the cost of idle capacity and increased expenses during non-peak periods, creating an opportunity for optimization in database management strategies.
Self-managed architecture:

The below figure shows the Aurora architecture for this use case. Like the first use case, we can demonstrate cost savings through strategic architectural design changes that are inherent to Aurora. Thanks to Aurora’s shared storage architecture and ability for any replica to be promoted to writer with zero data loss (zero RPO), we can eliminate the dedicated secondary instance traditionally needed for high availability. After a cross-Availability Zone failover, Aurora automatically creates a replacement read replica to replace the former primary instance, maintaining the desired capacity for the cluster.
As with most use cases, Aurora’s read replica architecture enables more efficient read scaling through its shared storage model, which eliminates the need for data replication between instances. For this use case, this efficiency is complemented by the Amazon Aurora Auto Scaling with Aurora Replicas feature, a dynamic alternative to maintaining persistent read-only instances. When auto-scaling is configured, the system automatically provisions and deprovisions instances based on workload demand, and can scale down to a single read replica during periods of low activity. This adaptive approach optimizes resource utilization, reduces costs associated with idle capacity, and ensures you only pay for the resources you need.
Aurora architecture:

Let’s apply similar assumptions as in our first use case: comparable instance types and sizes (r6g.xlarge, db.r6g.xlarge), with the self-managed architecture using 2 TB of io2 provisioned IOPS SSD storage at 64,000 IOPS, and for the Aurora architecture we’ll use Aurora I/O-Optimized. We chose Aurora I/O-Optimized for this scenario due to its ability to handle high-performance transactional workloads with consistent low-latency I/O, which aligns well with the requirements implied by the use of io2 storage in the self-managed configuration.
Let’s compare the monthly costs of the self-managed cluster with fixed instances versus the Aurora architecture with auto-scaling enabled:
| Architecture | Avg # DB Nodes (w/ writer) |
Instance Type | Storage Size per Volume |
# Storage Volumes |
Total Cost |
|---|---|---|---|---|---|
| Self-Managed | 6 | r6g.xlarge | 2 Tb | 6 | $23,635.01 |
| Amazon Aurora | 4 | db.r6g.xlarge (w/ Auto-Scaled Reads) |
2 Tb | 1 | $2,431.80 |
As shown above, the traditional cluster with 6 r6g.xlarge instances and associated storage costs totals $23,635.01 per month. In contrast, the Aurora architecture, even maintaining a writer plus an average of three out of four read replicas actively provisioned throughout a given month, comes to $2,431.80 per month—an 89.7% cost reduction. This demonstrates the financial benefits of Aurora’s auto-scaling capabilities. These savings increase as we reduce the monthly average of active read replicas. For instance, scaling down to an average of two read replicas decreases costs further, with savings exceeding 90%. During periods of low activity, scaling to an average of one read replica reduces costs even more, demonstrating the flexibility and cost-effectiveness of Aurora’s architecture.
As an alternative architecture for this use case, Amazon Aurora Serverless v2 offers a versatile solution for handling unpredictable traffic patterns, automatically adjusting both read and write capacity in real-time to meet fluctuating demands.
Alternative Aurora architecture:
Aurora Serverless v2 offers an optimal solution for managing variable workloads, ensuring resource efficiency without compromising performance. This innovative architecture, shown in the preceding figure, dynamically allocates only the necessary resources, maintaining consistent speed and performance regardless of demand fluctuations. In contrast to the self-managed architecture’s six pre-provisioned instances, this optimized Aurora configuration can decrease the average monthly resource allocation for both the read replicas and the primary instance. This streamlined configuration not only simplifies management but also enhances cost-effectiveness. During periods of low or no demand, Aurora Serverless v2 supports scaling capacity down to zero, reducing costs. Furthermore, Aurora offers the versatility to combine serverless and provisioned instances within a single cluster, enabling precise tailoring of resources to meet diverse workload requirements. This adaptive approach allows you to achieve a balance between performance and economy, effectively putting considerable savings back into your budget while helping to ensure that your application is responsive and efficient at all times.
Use case: Optimized reads
In this use case, we will highlight consistent read heavy workloads where auto-scaling may not provide a cost-effective solution due to the static nature of the workload. In the self-managed architecture for this use case (shown in the following figure), the application requires large read instances (for example: r6g.8xlarge) to meet specific performance demands. These instances, each providing 256 GB of memory, offer capacity for this particular use case’s requirements of low latency data caching and large in-memory table joins. The 256 GB memory footprint allows for keeping frequently accessed data in RAM, reducing I/O operations and improving query response times. Additionally, it provides space for executing complex queries involving large table joins without resorting to disk-based operations, which slow down performance. This configuration ensures that the database can handle intensive read operations, maintaining responsiveness even under heavy analytical workloads.
Self-managed architecture:

AWS has introduced Amazon Aurora Optimized Reads to address specific performance challenges for in-memory, read heavy database operations. This feature is used in the architecture shown in the following figure and offers improvements for Aurora, delivering up to eight times faster query latency and the potential for cost savings for applications dealing with large datasets that exceed the database instance’s memory capacity. Additionally, Aurora supports Optimized Reads on instance types equipped with locally attached NVMe storage, allowing you to enable this feature for enhanced read performance. See Overview of Aurora Optimized Reads in PostgreSQL for more details, and Use cases for Aurora Optimized Reads to see a list of application examples.
Aurora architecture:

For this example use case, we demonstrate how Aurora Optimized Reads with local NVMe storage can support the reduction of read-only instance sizes. While Aurora supports instance sizes equivalent to the self-managed architecture (db.r6g.8xlarge, db.r6gd.8xlarge), this example explores a cost-optimization approach using smaller instances. Specifically, we’re changing from r6g.8xlarge (32 vCPU, 256 GB memory) to db.r6gd.2xlarge (8 vCPU, 64 GB memory). This instance type change is possible because Aurora Optimized Reads provides 64 GB of primary memory plus 474 GB of NVMe-based tiered cache—delivering a combined total of 538 GB, more than double the 256 GB available with the original 8xlarge instances. This approach is particularly effective for read-intensive open source databases when the working dataset exhibits the following characteristics:
- The “hot” data (frequently accessed) fits within 20-30% of the original memory size (about 50-75 GB in this case).
- The entire working set is 2-3 times larger than the original memory (500-750 GB).
- Read patterns show temporal locality, with 80-90% of reads targeting the hot data.
In such scenarios, the 64 GB of primary memory can efficiently cache the most critical data, while the 474 GB of NVMe storage acts as a high-performance extension of the memory hierarchy, effectively compensating for the reduction in primary memory. However, it’s crucial to note that this configuration reduces available CPU from 32 vCPUs to 8 vCPUs per instance. While the memory and storage architecture can support the workload requirements, careful performance testing should be conducted to ensure the reduced CPU capacity meets your specific workload demands.
Let’s examine the monthly costs when comparing the traditional architecture against Aurora with Optimized Reads enabled, maintaining the same configuration assumptions as in our previous examples:
| Architecture | # DB Nodes (w/ writer) |
Instance Type | Storage Size per Volume |
# Storage Volumes |
Total Cost |
|---|---|---|---|---|---|
| Self-Managed | 5 | r6g.8xlarge | 2 Tb | 5 | $24,846.72 |
| Amazon Aurora | 4 | db.r6gd.2xlarge (w/ Optimized Reads) |
2 Tb | 1 | $5,197.04 |
As demonstrated above, the traditional architecture with r6g.8xlarge instances costs $24,846.72 per month, while the Aurora architecture with db.r6gd.2xlarge instances and Optimized Reads comes to $5,197.04 per month—representing a 79.1% cost reduction. These savings are achieved while maintaining or improving the required performance and latency levels through Aurora’s efficient memory tiering and optimized read capabilities, particularly for workloads that align with the access patterns described above.
Additional Cost-Optimizing Features of Amazon Aurora
As we round out our discussion of Aurora’s cost optimization capabilities, it’s valuable to examine several additional features that merit attention. In this section, we’ll introduce each of these functionalities, highlighting their benefits and operational advantages. These features not only showcase Aurora’s comprehensive approach to database management but also contribute to cost savings when compared to self-managed solutions.
Aurora Global Database
Aurora Global Database extends Aurora’s capabilities across multiple AWS Regions, enabling applications to read data with local latency and providing disaster recovery for region-wide outages. In traditional MySQL and PostgreSQL deployments, multi-region setups require custom-built replication solutions, multiple copies of data in each region, and ongoing maintenance of complex infrastructure. Aurora Global Database eliminates these requirements through built-in cross-region replication with lag times under 1 second, while charging only for the actual data volume once per region.
Aurora automates cross-Region replication and provides fully automated regional failover when initiated by the user. This automation, combined with independent scaling of read capacity in each region, reduces both operational overhead and infrastructure costs compared to self-managed solutions. Traditional setups often require uniform infrastructure across regions and multiple data copies for high availability, leading to over-provisioning and increased costs. Aurora Global Database’s architecture eliminates these additional expenses while maintaining high availability and disaster recovery capabilities.
Aurora cloning and blue/green deployments
Database cloning and blue/green deployments are industry practices used for creating database copies and managing updates with minimal risk. Aurora implements these concepts with unique advantages over self-managed MySQL and PostgreSQL environments.
Aurora cloning creates new database instances using a copy-on-write protocol at the storage layer, where new instances initially point to the same underlying data as the source. This approach minimizes additional storage costs by only storing incremental changes, and eliminates performance impact on the source database. In contrast, self-managed solutions often require time-consuming full data copies and incur additional storage costs.
Aurora blue/green deployments feature enables database updates and schema changes with minimal interruption, typically seconds during the final cutover. If issues are detected during the switchover window that prevent a complete transition to the green environment, the feature allows for immediate rollback to the blue environment. While the deployment does create duplicate compute infrastructure, it utilizes the same copy-on-write protocol as Aurora cloning, meaning the green environment initially points to the same underlying data as the blue environment and only stores incremental changes. Traditional database updates in self-managed environments often require extensive downtime or complex replication setups that incur additional costs.
Together, Aurora cloning and blue/green deployments enhance management efficiency, accelerate development cycles, and optimize resource utilization, reducing operational risks compared to self-managed deployments while providing a managed solution for database updates.
Aurora zero-ETL integration
Extract, Transform, and Load (ETL) processes integrate data between operational databases and analytics platforms. Traditional MySQL and PostgreSQL implementations require custom change data capture (CDC) infrastructure, dedicated development teams for pipeline creation and maintenance, additional compute resources for data extraction, ongoing monitoring of data flows, and manual intervention for schema changes.
Aurora zero-ETL integration automates data movement between Aurora and supported AWS analytics services (such as Amazon Redshift), providing built-in CDC, schema synchronization, near real-time data updates, and native integration with AWS analytics services. This approach reduces CDC infrastructure costs, removes pipeline development expenses, reduces compute resources for data movement, and decreases operational overhead on Aurora. The integration maintains clear separation of operational and analytical workloads, with analytical queries executing on the target platform rather than Aurora, preserving database performance while enabling timely analytics access. These features combine to reduce both infrastructure and operational costs compared to maintaining similar capabilities in self-managed environments.
Conclusion
In this post, we’ve unveiled the cost advantages of deploying and migrating to Amazon Aurora. Our analysis challenged the common assumption that self-managed, open source solutions offer peak economic value. Through specific use cases, we demonstrated how Aurora’s unique features reduce costs across a wide range of scenarios. The innovative design combines commercial-grade versatility with competitive pricing for organizations optimizing their database operations. As database needs evolve, Aurora delivers both performance and cost-efficiency.
We encourage businesses to reassess their current database design and operations, and explore how Aurora can enhance their operational efficiency and bottom line. For a personalized assessment of potential savings from migrating to Aurora, reach out to our AWS account teams and Partners.
For more information about pricing, and to see examples of cost estimates, see Amazon Aurora Pricing.
You can start using Amazon Aurora today by visiting the Amazon RDS console. For more information, see the Aurora User Guide.
About the Author
 Chris Riggin is a Senior Specialist Solutions Architect at Amazon Web Services. He is committed to helping customers maximize their cost savings by designing high-performance, resilient, and scalable architectures using AWS services.
Chris Riggin is a Senior Specialist Solutions Architect at Amazon Web Services. He is committed to helping customers maximize their cost savings by designing high-performance, resilient, and scalable architectures using AWS services.
 Cees Molenaar is a Senior Specialist Sales Representative at Amazon Web Services. He is passionate about fostering enduring partnerships with customers by offering expert guidance and reliable support in using AWS services.
Cees Molenaar is a Senior Specialist Sales Representative at Amazon Web Services. He is passionate about fostering enduring partnerships with customers by offering expert guidance and reliable support in using AWS services.
Source: Read More
