
Key Takeaways
We achieve real-world testing by adopting release candidates (RCs) on our internal production systems before finalizing a release.
Our diverse internal workloads delivered unique insights. For instance, an internal cluster’s upgrade identified a rare MongoDB server crash and an inefficiency for a specific query shape introduced by a new MongoDB 8.0 feature.
Issues encountered while testing MongoDB 8.0 internally were fixed proactively before they went out to customers. For example, during an upgrade to an 8.0 RC, one of our internal databases crashed and the issue was fixed in the next RC.
Prerelease testing uncovered gaps in our automated testing, leading to improved coverage with additional tests.
Using MongoDB 8.0 internally on mission-critical internal systems demonstrated its reliability. This gave customers confidence that the release could handle their demanding workloads, just as it did for our own engineering teams.
Release jitters
Every software release, whether it’s a new product or an update of an existing one, comes with an inherent risk: what if users encounter a bug that the development team didn’t anticipate? With a mission-critical product like MongoDB 8.0, even minor issues can have a significant impact on customer operations, uptime, and business continuity.
Unfortunately, no amount of automated testing can guarantee how MongoDB will perform when it lands with customers. So how does MongoDB proactively identify and resolve issues in our software before customers encounter them, thereby ensuring a seamless upgrade experience and maintaining customer trust?
Catching issues before you do
To address these challenges, we employ a combination of methods to ensure reliability. One approach is to formally model our system to prove the design is correct, such as the effort we undertook to mathematically model our protocols with lightweight formal methods like TLA+. Another method is to prove reliability empirically by dogfooding.
Dogfooding (🤨)?
Eating your own dog food—aka eating your own pizza, aka “dogfooding”—refers to a development process where you put yourself in customers’ shoes by using your own product in your own production systems. In short: you’re your own customer.
Why dogfood?
Enhanced product quality: Testing in a controlled environment can’t replicate the edge cases of true-to-life workloads, so real-world scenarios are needed to ensure robustness, reliability, and performance under diverse conditions.
Early identification of issues: Testing internally surfaces issues earlier in the release process, enabling fixes to be deployed proactively before customers encounter them.
Build customer empathy: Acting as users provides direct insight into customer pain points and needs. Engineers gain firsthand understanding of the challenges of using their product, informing more customer-centric solutions. Without dogfooding, things like upgrades are taken for granted and customer pain points can be overlooked.
Boost credibility and trust: Relying on our own software to power critical internal systems reassures customers of its dependability.
Dogfooding at MongoDB
MongoDB has a strong dogfooding culture. Many internal services are built with MongoDB and hosted on MongoDB Atlas, the very same setup we provide our customers. Eating our own dog food is essential to our customer mindset. Because internal teams work alongside MongoDB engineers, acting as users bridges the gap between MongoDB engineers and their customers. Additionally, real-life workloads vet our software and processes in a way automated testing cannot.
Release dogfooding
With the release of MongoDB 8.0, the company decided to take dogfooding one step further. Driven by a company-wide focus on making 8.0 the most performant version of MongoDB yet, we embarked on an ambitious plan to dogfood the release candidates within our own infrastructure.
Before, our release process looked like this:
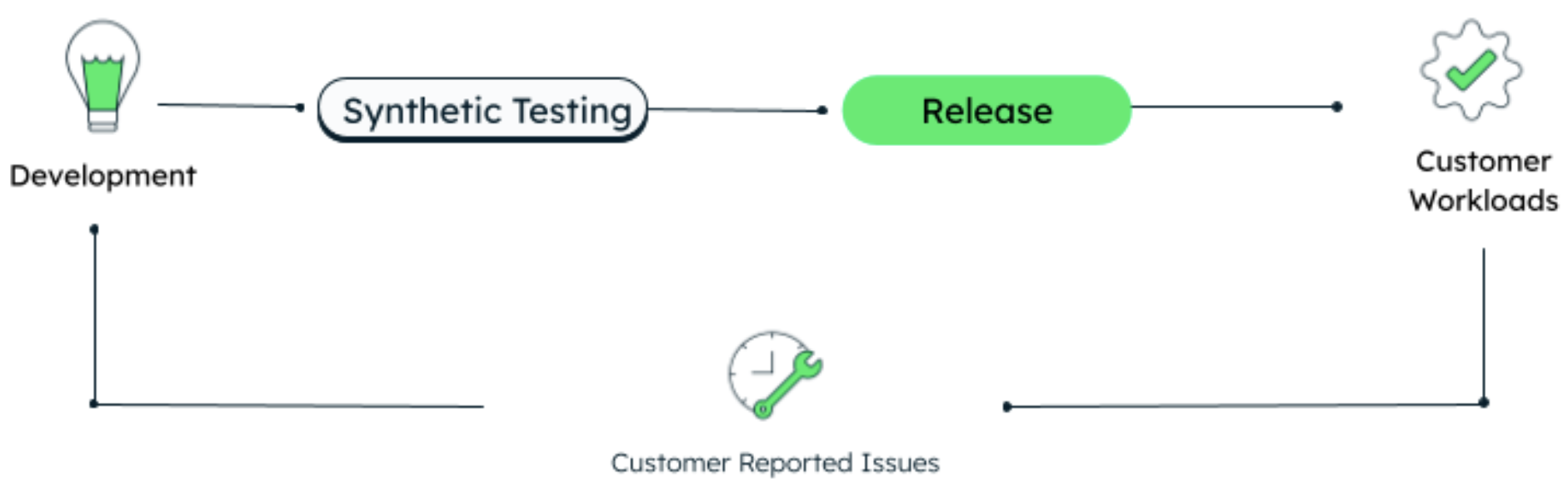
We wanted it to look more like this:
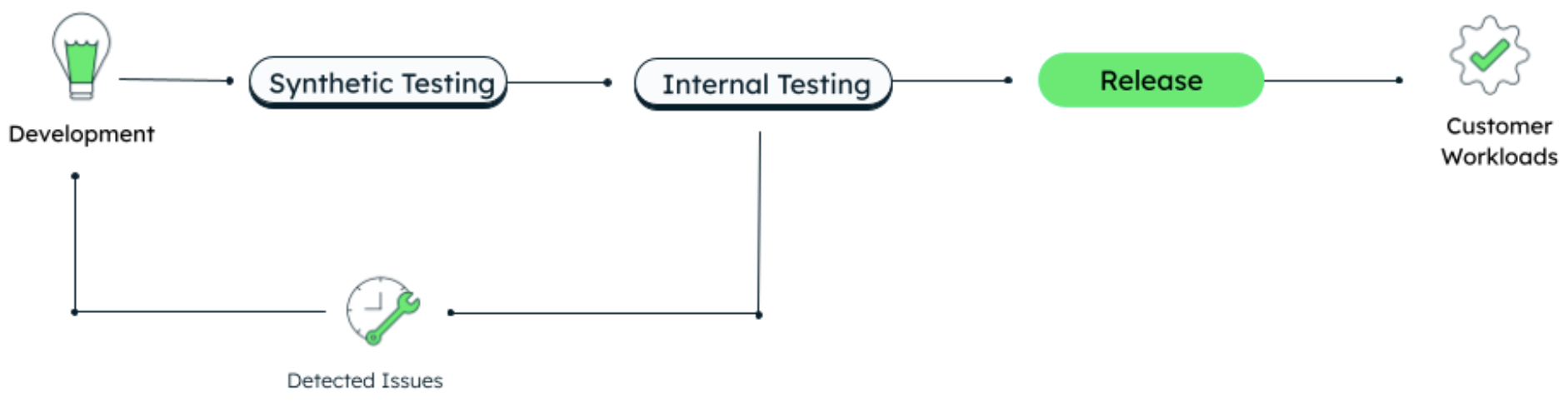
Adding internal testing to the release process allows us to iterate long before we make the product available to customers. Whereas in the past we’d release and fix issues reactively as customers encountered them, using the release internally, before it got into customers’ hands, would uncover edge cases so we could fix them proactively. By acting as our own customers, we remove our real customers from the development cycle and build confidence in the release.
The confidence team
To tackle upgrades effectively, we assembled a cross-functional team of MongoDB engineers, Atlas SREs, and internal service developers. A technical program manager (TPM) was assigned to the effort to track progress and coordinate efforts across the team. Together, we enumerated the databases, scheduled upgrade dates, and assigned directly responsible individuals (DRIs) to each upgrade.
To streamline communication, we created an internal Slack channel and invited everyone on the team to it. We agreed on a playbook: with the support of the team, the assigned DRI would upgrade their cluster and monitor for any issues. If something came up we would create a ticket in an internal Jira project and mention it in Slack for visibility. I took on the role of DRI for Evergreen database upgrades.
Evergreen
My team maintains the database clusters for Evergreen, MongoDB’s bespoke continuous integration (CI) system. Evergreen is responsible for running automated tests at scale against MongoDB, Atlas, the drivers, Evergreen itself, and many other products. At last count, each day Evergreen executes, in parallel, roughly ten years of tests per day and is on the critical path for many teams at the company. Evergreen runs on two separate clusters in Atlas: the application’s main replica set and a smaller one for our background job coordinator, Amboy. In terms of scale, the main replica set contains around 9.5TB of data and handles 1 billion CRUD operations per day, while the Amboy cluster contains about 1TB of data and handles 100 million CRUD operations per day.
Because of Evergreen’s criticality to the development cycle, historically we’ve taken a cautious approach to any operational changes and database upgrades were not a priority. The initiative to dogfood our internal clusters changed our approach—we were going to use 8.0 before it went out to customers. Enabling a feature flag in Atlas made the RC build available in our Atlas project before it was available to customers.
A showstopper
Our first target was the Amboy cluster, which handles background jobs for Evergreen. I clicked the button to upgrade our Amboy cluster and we held our collective breath. Atlas upgrades are rolling. This means an upgrade is applied iteratively to each secondary in the cluster until finally the primary is stepped down and upgraded. Usually this works well since any issues will at most affect just a secondary, but in our case it didn’t work out. The secondaries’ upgrades succeeded, but when the primary was stepped down, each node that won the election to be the next primary crashed. The result was that our cluster had no primary and the Amboy database was unavailable, which threw a monkey-wrench in our application.
We sounded the alarm and an investigation commenced ASAP. Stack traces, logs, and diagnostics were captured and the cluster was downgraded to 7.0. As it turned out, we’d hit an edge case that was triggered by a malformed TTL index specification with a combination of two irregularities:
Its
expireAfterSecondswas not an integer.It contained a weights field, which is not valid in an index that’s not a text index.
Both irregularities were previously allowed, but became invalid due to strengthened validation checks. When a node steps up to primary, it corrects these malformed index specifications, but in that 8.0 RC if there were two things wrong with an index it would go down an execution path that ended in a segfault. This bug only occurs when a node steps up to primary, which is why it brought down our cluster despite the rolling upgrade. SERVER-94487 was opened to fix the bug and the fix was rolled into the next RC. When the RC was ready, we upgraded the Amboy database again and the upgrade succeeded.
Not a showstopper
Next up was the main database cluster for the Evergreen application. We performed the upgrade, and at first all indications were that the upgrade was a success. However, on further inspection a discontinuous jump had appeared in two of the Atlas monitoring graphs. Before the upgrade our Query Executor graph usually looked like this:
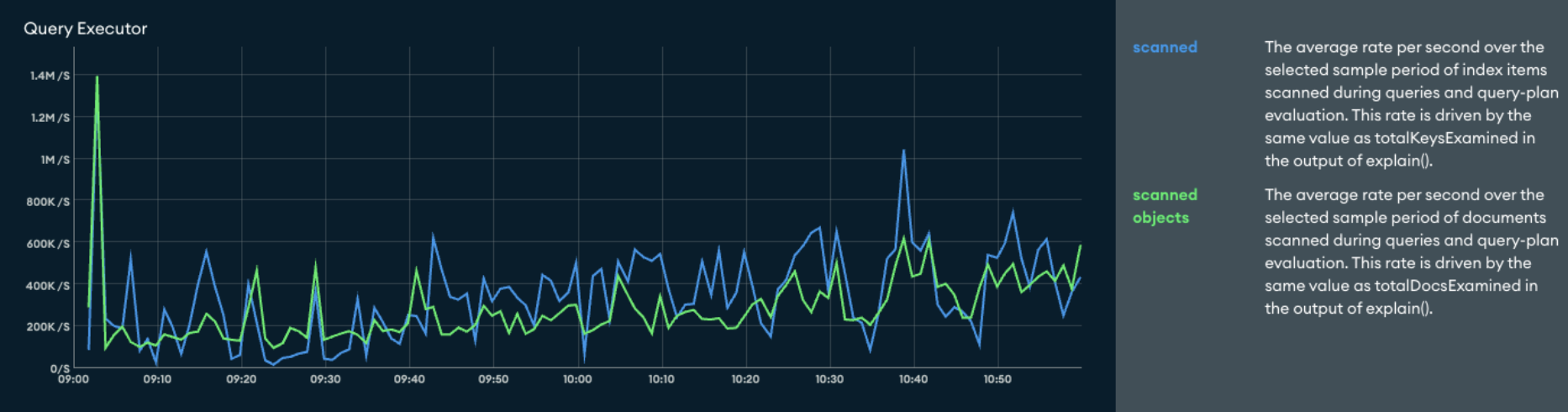
Whereas after the upgrade it looked like this:
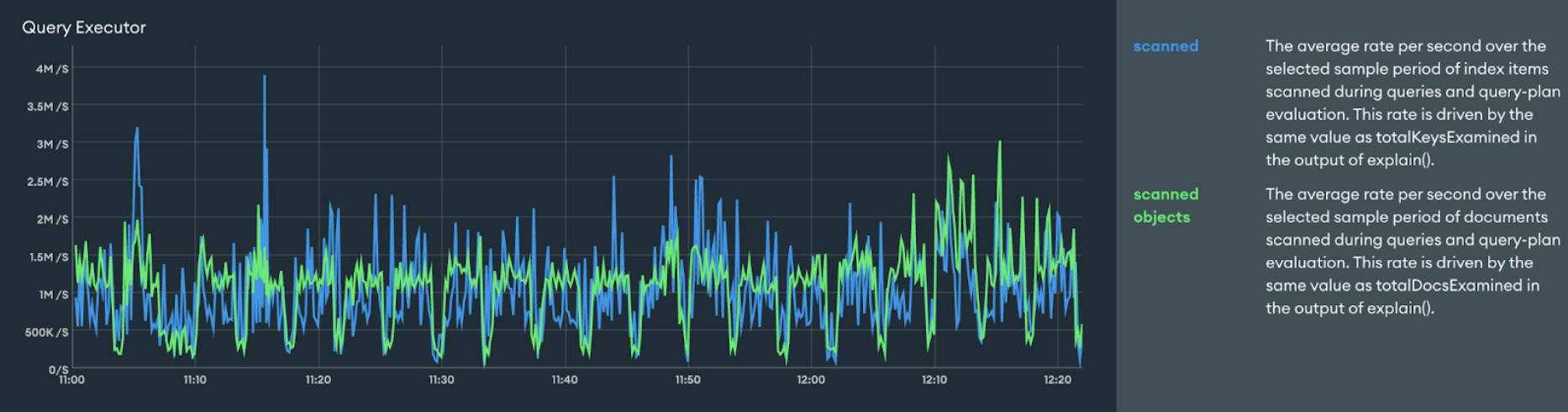
This represented roughly a 5x increase in the rate per second of index keys and documents scanned by queries and query plans.
Similarly, the Query Targeting graph looked like this before the upgrade:
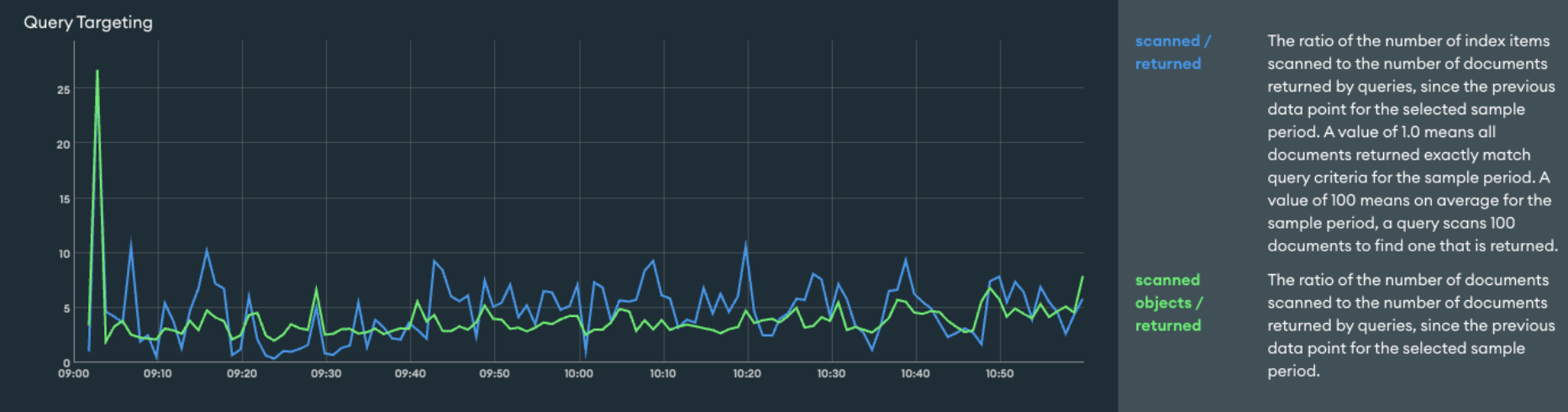
Whereas after the upgrade it looked like this:
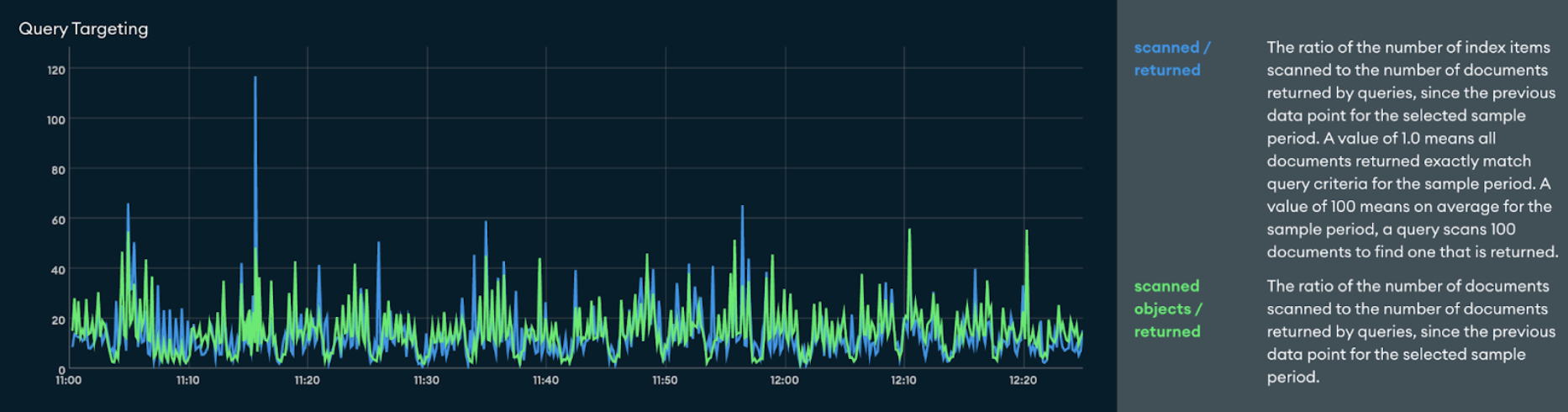
This also represented roughly a 5x increase to the ratio of scanned index keys and documents to the number of documents returned.
Both these graphs indicated there was at least one query that wasn’t using indexes as well as it had been before the upgrade. We got eyes on the cluster and it was determined that a bug in index pruning (a new feature introduced in 8.0) was causing the query planner to remove the most efficient index for a contained $or query shape. This is when a query contains an $or branch that isn’t the root of the query predicate, such as A and (C or B). For the 8.0 release this was listed as a known issue and disabled in Atlas, and index pruning was disabled entirely by the 8.0.1 release until we can fix the underlying issue in SERVER-94741.
Other clusters
Other teams’ clusters followed suit, but their upgrades went off without a hitch. It’s to be expected that the particulars of each dataset and workload would trigger various edge cases. Evergreen’s clusters hit some while the rest did not. This brings out an important lesson: testing against a variegated set of live workloads raises the likelihood we’ll encounter and address all the issues our customers would have encountered.
Continuous improvement
Although we caught these issues before they reached customers, our shift-left mindset motivates us to catch them earlier in the process through automated testing. As part of this effort, we plan to add additional tests focused on upgrades from older versions of the database. The index pruning issue, in particular, was part of the inspiration for us to investigate property based testing–an approach that has already uncovered several new bugs (SERVER-89308). SERVER-92232 will introduce a property based test specifically for index pruning.
What’s next?
All told, the exercise was a success. The 8.0 upgrade reduced Evergreen’s operation execution times by an order of magnitude:
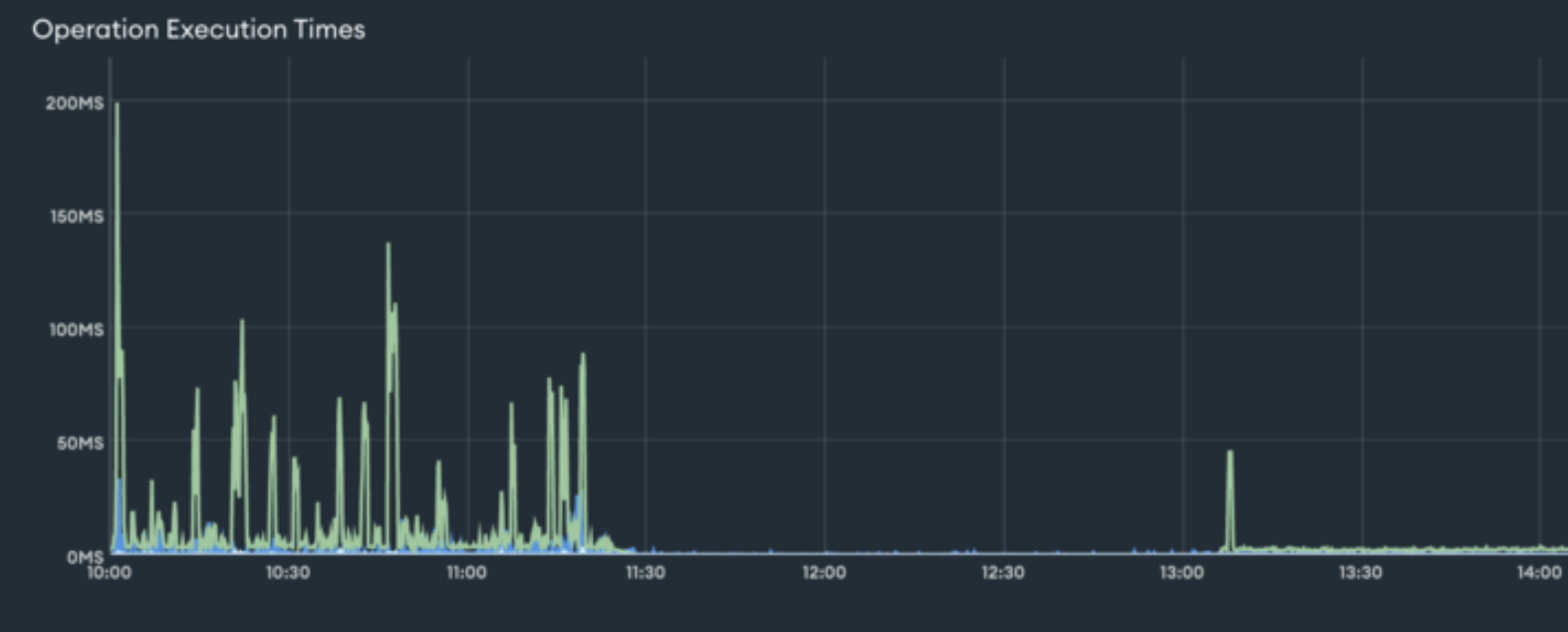
For customers, dogfooding uncovered novel issues and gave us the chance to fix them before they could disrupt customer workloads. By the time we cut the release we were confident we were providing our customers a seamless upgrade.
Through the dogfooding process we discovered additional internal teams with services built on MongoDB. And now we’re further leaning in on dogfooding by building out a formal framework that will include those teams and their clusters. For the next release, this will uncover even more insights and provide greater confidence.
Looking ahead, as our CTO aptly put it, “all customers demand security, durability, availability, and performance” from their technology. Our commitment to eating our own dogfood directly strengthens these very pillars. It’s a commitment to our customers, a commitment to innovation, and a commitment to making MongoDB the best database in the world.
Join our MongoDB Community to learn about upcoming events, hear stories from MongoDB users, and connect with community members from around the world.
Source: Read More

