


In your Java applications, you’ll typically work with various types of objects. And you might want to perform operations like sorting, searching, and iterating on these objects.
Prior to the introduction of the Collections framework in JDK 1.2, you would’ve used Arrays and Vectors to store and manage a group of objects. But they had their own share of drawbacks.
The Java Collections Framework aims to overcome these issues by providing high-performance implementations of common data structures. These allow you to focus on writing the application logic instead of focusing on low-level operations.
Then, the introduction of Generics in JDK 1.5 significantly improved the Java Collections Framework. Generics let you enforce type safety for objects stored in a collection, which enhances the robustness of your applications. You can read more about Java Generics here.
In this article, I will guide you through how to use the Java Collections Framework. We’ll discuss the different types of collections, such as Lists, Sets, Queues, and Maps. I’ll also provide a brief explanation of their key characteristics such as:
-
Internal mechanisms
-
Handling of duplicates
-
Support for null values
-
Ordering
-
Synchronization
-
Performance
-
Key methods
-
Common implementations
We’ll also walk through some code examples for better understanding, and I’ll touch on the Collections utility class and its usage.
Table of Contents:
Understanding the Java Collections Framework
According to the Java documentation, “A collection is an object that represents a group of objects. A collections framework is a unified architecture for representing and manipulating collections.”
In simple terms, the Java Collections Framework helps you manage a group of objects and perform operations on them efficiently and in an organized way. It makes it easier to develop applications by offering various methods to handle groups of objects. You can add, remove, search, and sort objects effectively using the Java Collections Framework.
Collection Interfaces
In Java, an interface specifies a contract that must be fulfilled by any class that implements it. This means the implementing class must provide concrete implementations for all the methods declared in the interface.
In the Java Collections Framework, various collection interfaces like Set, List, and Queue extend the Collection interface, and they must adhere to the contract defined by the Collection interface.
Decoding the Java Collections Framework Hierarchy
Check out this neat diagram from this article that illustrates the Java Collection Hierarchy:
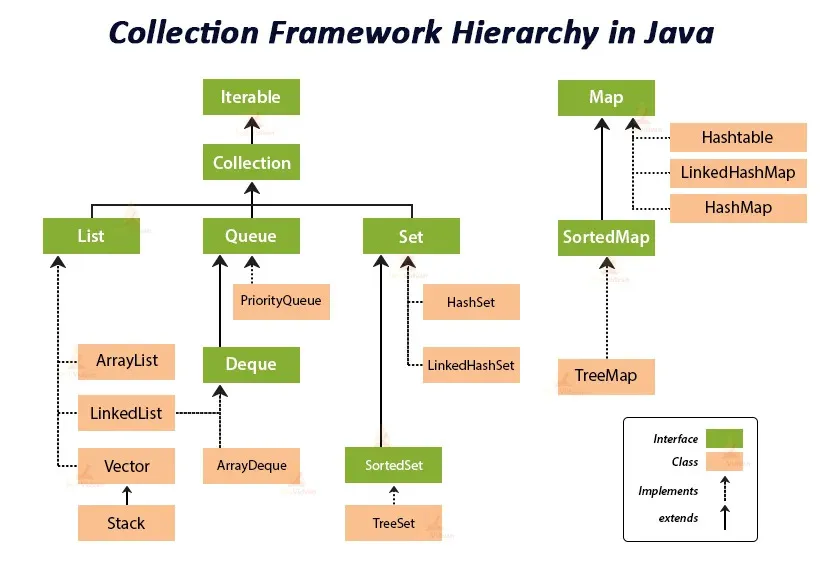
We’ll start from the top and work down so you can understand what this diagram is showing:
-
At the root of the Java Collections Framework is the
Iterableinterface, which lets you iterate over the elements of a collection. -
The
Collectioninterface extends theIterableinterface. This means it inherits the properties and behavior of theIterableinterface and adds its own behavior for adding, removing, and retrieving elements. -
Specific interfaces such as
List,Set, andQueuefurther extend theCollectioninterface. Each of these interfaces has other classes implementing their methods. For example,ArrayListis a popular implementation of theListinterface,HashSetimplements theSetinterface, and so on. -
The
Mapinterface is part of the Java Collections Framework, but it does not extend theCollectioninterface, unlike the others mentioned above. -
All the interfaces and classes in this framework are part of the
java.utilpackage.
Note: A common source of confusion in the Java Collections Framework revolves around the difference between Collection and Collections. Collection is an interface in the framework, while Collections is a utility class. The Collections class provides static methods that perform operations on the elements of a collection.
Java Collection Interfaces
By now, you’re familiar with the different types of collections that form the foundation of the collections framework. Now we’ll take a closer look at the List, Set, Queue, and Map interfaces.
In this section, we’ll discuss each of these interfaces while exploring their internal mechanisms. We’ll examine how they handle duplicate elements and whether they support the insertion of null values. We’ll also understand the ordering of elements during insertion and their support for synchronization, which deals with the concept of thread safety. Then we’ll walk through a few key methods of these interfaces and conclude by reviewing common implementations and their performance for various operations.
Before we begin, let’s talk briefly about Synchronization and Performance.
-
Synchronization controls access to shared objects by multiple threads, ensuring their integrity and preventing conflicts. This is crucial for maintaining thread safety.
-
When choosing a collection type, one important factor is its performance during common operations like insertion, deletion, and retrieval. Performance is usually expressed using Big-O notation. You can learn more about it here.
Lists
A List is an ordered or sequential collection of elements. It follows zero-based indexing, allowing the elements to be inserted, removed, or accessed using their index position.
-
Internal mechanism: A
Listis internally supported by either an array or a linked list, depending on the type of implementation. For example, anArrayListuses an array, while aLinkedListuses a linked list internally. You can read more aboutLinkedListhere. AListdynamically resizes itself upon the addition or removal of elements. The indexing-based retrieval makes it a very efficient type of collection. -
Duplicates: Duplicate elements are allowed in a
List, which means there can be more than one element in aListwith the same value. Any value can be retrieved based on the index at which it is stored. -
Null: Null values are also allowed in a
List. Since duplicates are permitted, you can also have multiple null elements. -
Ordering: A
Listmaintains insertion order, meaning the elements are stored in the same order they are added. This is helpful when you want to retrieve elements in the exact order they were inserted. -
Synchronization: A
Listis not synchronized by default, which means it doesn’t have a built-in way to handle access by multiple threads at the same time. -
Key methods: Here are some key methods of a
Listinterface:add(E element),get(int index),set(int index, E element),remove(int index), andsize(). Let’s look at how to use these methods with an example program.import java.util.ArrayList; import java.util.List; public class ListExample { public static void main(String[] args) { // Create a list List<String> list = new ArrayList<>(); // add(E element) list.add("Apple"); list.add("Banana"); list.add("Cherry"); // get(int index) String secondElement = list.get(1); // "Banana" // set(int index, E element) list.set(1, "Blueberry"); // remove(int index) list.remove(0); // Removes "Apple" // size() int size = list.size(); // 2 // Print the list System.out.println(list); // Output: [Blueberry, Cherry] // Print the size of the list System.out.println(size); // Output: 2 } } -
Common implementations:
ArrayList,LinkedList,Vector,Stack -
Performance: Typically, insert and delete operations are fast in both
ArrayListandLinkedList. But fetching elements can be slow because you have to traverse through the nodes.
| Operation | ArrayList | LinkedList |
| Insertion | Fast at the end – O(1) amortized, slow at the beginning or middle- O(n) | Fast at the beginning or middle – O(1), slow at the end – O(n) |
| Deletion | Fast at the end – O(1) amortized, slow at the beginning or middle- O(n) | Fast – O(1) if position is known |
| Retrieval | Fast – O(1) for random access | Slow – O(n) for random access, as it involves traversing |
Sets
A Set is a type of collection that does not allow duplicate elements and represents the concept of a mathematical set.
-
Internal mechanism: A
Setis internally backed by aHashMap. Depending on the implementation type, it is supported by either aHashMap,LinkedHashMap, or aTreeMap. I have written a detailed article about howHashMapworks internally here. Be sure to check it out. -
Duplicates: Since a
Setrepresents the concept of a mathematical set, duplicate elements are not allowed. This ensures that all elements are unique, maintaining the integrity of the collection. -
Null: A maximum of one null value is allowed in a
Setbecause duplicates are not permitted. But this does not apply to theTreeSetimplementation, where null values are not allowed at all. -
Ordering: Ordering of elements in a
Setdepends on the type of implementation.-
HashSet: Order is not guaranteed, and elements can be placed in any position. -
LinkedHashSet: This implementation maintains the insertion order, so you can retrieve the elements in the same order they were inserted. -
TreeSet: Elements are inserted based on their natural order. Alternatively, you can control the insertion order by specifying a custom comparator.
-
-
Synchronization: A
Setis not synchronized, meaning you might encounter concurrency issues, like race conditions, which can affect data integrity if two or more threads try to access aSetobject simultaneously -
Key methods: Here are some key methods of a
Setinterface:add(E element),remove(Object o),contains(Object o), andsize(). Let’s look at how to use these methods with an example program.import java.util.HashSet; import java.util.Set; public class SetExample { public static void main(String[] args) { // Create a set Set<String> set = new HashSet<>(); // Add elements to the set set.add("Apple"); set.add("Banana"); set.add("Cherry"); // Remove an element from the set set.remove("Banana"); // Check if the set contains an element boolean containsApple = set.contains("Apple"); System.out.println("Contains Apple: " + containsApple); // Get the size of the set int size = set.size(); System.out.println("Size of the set: " + size); } } -
Common implementations:
HashSet,LinkedHashSet,TreeSet -
Performance:
Setimplementations offer fast performance for basic operations, except for aTreeSet, where the performance can be relatively slower because the internal data structure involves sorting the elements during these operations.
| Operation | HashSet | LinkedHashSet | TreeSet |
| Insertion | Fast – O(1) | Fast – O(1) | Slower – O(log n) |
| Deletion | Fast – O(1) | Fast – O(1) | Slower – O(log n) |
| Retrieval | Fast – O(1) | Fast – O(1) | Slower – O(log n) |
Queues
A Queue is a linear collection of elements used to hold multiple items before processing, usually following the FIFO (first-in-first-out) order. This means elements are added at one end and removed from the other, so the first element added to the queue is the first one removed.
-
Internal mechanism: The internal workings of a
Queuecan differ based on its specific implementation.-
LinkedList– uses a doubly-linked list to store elements, which means you can traverse both forward and backward, allowing for flexible operations. -
PriorityQueue– is internally backed by a binary heap, which is very efficient for retrieval operations. -
ArrayDeque– is implemented using an array that expands or shrinks as elements are added or removed. Here, elements can be added or removed from both ends of the queue.
-
-
Duplicates: In a
Queue, duplicate elements are permitted, allowing multiple instances of the same value to be inserted -
Null: You cannot insert a null value into a
Queuebecause, by design, some methods of aQueuereturn null to indicate that it is empty. To avoid confusion, null values are not allowed. -
Ordering: Elements are inserted based on their natural order. Alternatively, you can control the insertion order by specifying a custom comparator.
-
Synchronization: A
Queueis not synchronized by default. But, you can use aConcurrentLinkedQueueor aBlockingQueueimplementation for achieving thread safety. -
Key methods: Here are some key methods of a
Queueinterface:add(E element),offer(E element),poll(), andpeek(). Let’s look at how to use these methods with an example program.import java.util.LinkedList; import java.util.Queue; public class QueueExample { public static void main(String[] args) { // Create a queue using LinkedList Queue<String> queue = new LinkedList<>(); // Use add method to insert elements, throws exception if insertion fails queue.add("Element1"); queue.add("Element2"); queue.add("Element3"); // Use offer method to insert elements, returns false if insertion fails queue.offer("Element4"); // Display queue System.out.println("Queue: " + queue); // Peek at the first element (does not remove it) String firstElement = queue.peek(); System.out.println("Peek: " + firstElement); // outputs "Element1" // Poll the first element (retrieves and removes it) String polledElement = queue.poll(); System.out.println("Poll: " + polledElement); // outputs "Element1" // Display queue after poll System.out.println("Queue after poll: " + queue); } } -
Common implementations:
LinkedList,PriorityQueue,ArrayDeque -
Performance: Implementations like
LinkedListandArrayDequeare usually quick for adding and removing items. ThePriorityQueueis a bit slower because it inserts items based on the set priority order.
| Operation | LinkedList | PriorityQueue | ArrayDeque |
| Insertion | Fast at the beginning or middle – O(1), slow at the end – O(n) | Slower – O(log n) | Fast – O(1), Slow – O(n), if it involves resizing of the internal array |
| Deletion | Fast – O(1) if position is known | Slower – O(log n) | Fast – O(1), Slow – O(n), if it involves resizing of the internal array |
| Retrieval | Slow – O(n) for random access, as it involves traversing | Fast – O(1) | Fast – O(1) |
Maps
A Map represents a collection of key-value pairs, with each key mapping to a single value. Although Map is part of the Java Collection framework, it does not extend the java.util.Collection interface.
-
Internal mechanism: A
Mapworks internally using aHashTablebased on the concept of hashing. I have written a detailed article on this topic, so give it a read for a deeper understanding. -
Duplicates: A
Mapstores data as key-value pairs. Here, each key is unique, so duplicate keys are not allowed. But duplicate values are permitted. -
Null: Since duplicate keys are not allowed, a
Mapcan have only one null key. As duplicate values are permitted, it can have multiple null values. In theTreeMapimplementation, keys cannot be null because it sorts the elements based on the keys. However, null values are allowed. -
Ordering: Insertion order of a
Mapvaries on the implementation:-
HashMap– the insertion order is not guaranteed as they are determined based on the concept of hashing. -
LinkedHashMap– the insertion order is preserved and you can retrieve the elements back in the same order that they were added into the collection. -
TreeMap– Elements are inserted based on their natural order. Alternatively, you can control the insertion order by specifying a custom comparator.
-
-
Synchronization: A
Mapis not synchronized by default. But you can useCollections.synchronizedMap()orConcurrentHashMapimplementations for achieving thread safety. -
Key methods: Here are some key methods of a
Mapinterface:put(K key, V value),get(Object key),remove(Object key),containsKey(Object key), andkeySet(). Let’s look at how to use these methods with an example program.import java.util.HashMap; import java.util.Map; import java.util.Set; public class MapMethodsExample { public static void main(String[] args) { // Create a new HashMap Map<String, Integer> map = new HashMap<>(); // put(K key, V value) - Inserts key-value pairs into the map map.put("Apple", 1); map.put("Banana", 2); map.put("Orange", 3); // get(Object key) - Returns the value associated with the key Integer value = map.get("Banana"); System.out.println("Value for 'Banana': " + value); // remove(Object key) - Removes the key-value pair for the specified key map.remove("Orange"); // containsKey(Object key) - Checks if the map contains the specified key boolean hasApple = map.containsKey("Apple"); System.out.println("Contains 'Apple': " + hasApple); // keySet() - Returns a set view of the keys contained in the map Set<String> keys = map.keySet(); System.out.println("Keys in map: " + keys); } } -
Common implementations:
HashMap,LinkedHashMap,TreeMap,Hashtable,ConcurrentHashMap -
Performance:
HashMapimplementation is widely used mainly due to its efficient performance characteristics depicted in the below table.
| Operation | HashMap | LinkedHashMap | TreeMap |
| Insertion | Fast – O(1) | Fast – O(1) | Slower – O(log n) |
| Deletion | Fast – O(1) | Fast – O(1) | Slower – O(log n) |
| Retrieval | Fast – O(1) | Fast – O(1) | Slower – O(log n) |
Collections Utility Class
As highlighted at the beginning of this article, the Collections utility class has several useful static methods that let you perform commonly used operations on the elements of a collection. These methods help you reduce the boilerplate code in your application and lets you focus on the business logic.
Here are some key features and methods, along with what they do, listed briefly:
-
Sorting:
Collections.sort(List<T>)– this method is used to sort the elements of a list in ascending order. -
Searching:
Collections.binarySearch(List<T>, key)– this method is used to search for a specific element in a sorted list and return its index. -
Reverse order:
Collections.reverse(List<T>)– this method is used to reverse the order of elements in a list. -
Min/Max Operations:
Collections.min(Collection<T>)andCollections.max(Collection<T>)– these methods are used to find the minimum and maximum elements in a collection, respectively. -
Synchronization:
Collections.synchronizedList(List<T>)– this method is used to make a list thread-safe by synchronizing it. -
Unmodifiable Collections:
Collections.unmodifiableList(List<T>)– this method is used to create a read-only view of a list, preventing modifications.
Here’s a sample Java program that demonstrates various functionalities of the Collections utility class:
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class CollectionsExample {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
numbers.add(5);
numbers.add(3);
numbers.add(8);
numbers.add(1);
// Sorting
Collections.sort(numbers);
System.out.println("Sorted List: " + numbers);
// Searching
int index = Collections.binarySearch(numbers, 3);
System.out.println("Index of 3: " + index);
// Reverse Order
Collections.reverse(numbers);
System.out.println("Reversed List: " + numbers);
// Min/Max Operations
int min = Collections.min(numbers);
int max = Collections.max(numbers);
System.out.println("Min: " + min + ", Max: " + max);
// Synchronization
List<Integer> synchronizedList = Collections.synchronizedList(numbers);
System.out.println("Synchronized List: " + synchronizedList);
// Unmodifiable Collections
List<Integer> unmodifiableList = Collections.unmodifiableList(numbers);
System.out.println("Unmodifiable List: " + unmodifiableList);
}
}
This program demonstrates sorting, searching, reversing, finding minimum and maximum values, synchronizing, and creating an unmodifiable list using the Collections utility class.
Conclusion
In this article, you’ve learned about the Java Collections Framework and how it helps manage groups of objects in Java applications. We explored various collection types like Lists, Sets, Queues, and Maps and gained insight into some of the key characteristics and how each of these types supports them.
You learned about performance, synchronization, and key methods, gaining valuable insights into choosing the right data structures for your needs.
By understanding these concepts, you can fully utilize the Java Collections Framework, allowing you to write more efficient code and build robust applications.
If you found this article interesting, feel free to check out my other articles on freeCodeCamp and connect with me on LinkedIn.
Source: freeCodeCamp Programming Tutorials: Python, JavaScript, Git & MoreÂ
 Exposes Systems to Remote Code Execution Risks")
