




Evaluating the real-world applicability of large language models (LLMs) is essential to guide their integration into practical use cases. One key challenge in assessing LLMs is their tendency to exploit fixed datasets during testing, leading to inflated performance metrics. Static evaluation frameworks often fail to determine a model’s ability to adapt to feedback or provide clarifications, resulting in evaluations that do not reflect real-world scenarios. This gap in assessment methods necessitates a dynamic and iterative framework to test models under evolving conditions.
Traditionally, evaluation methods like “LLM-as-a-Judge” rely on fixed datasets and static benchmarks to measure performance. While these approaches often correlate better with human judgments than lexical matching techniques, they suffer from biases, including verbosity preference and inconsistent scoring across iterations. They also fail to evaluate models in multi-turn interactions, where adaptability and iterative improvement are critical. As a result, these traditional methods struggle to capture a holistic understanding of an LLM’s capabilities.
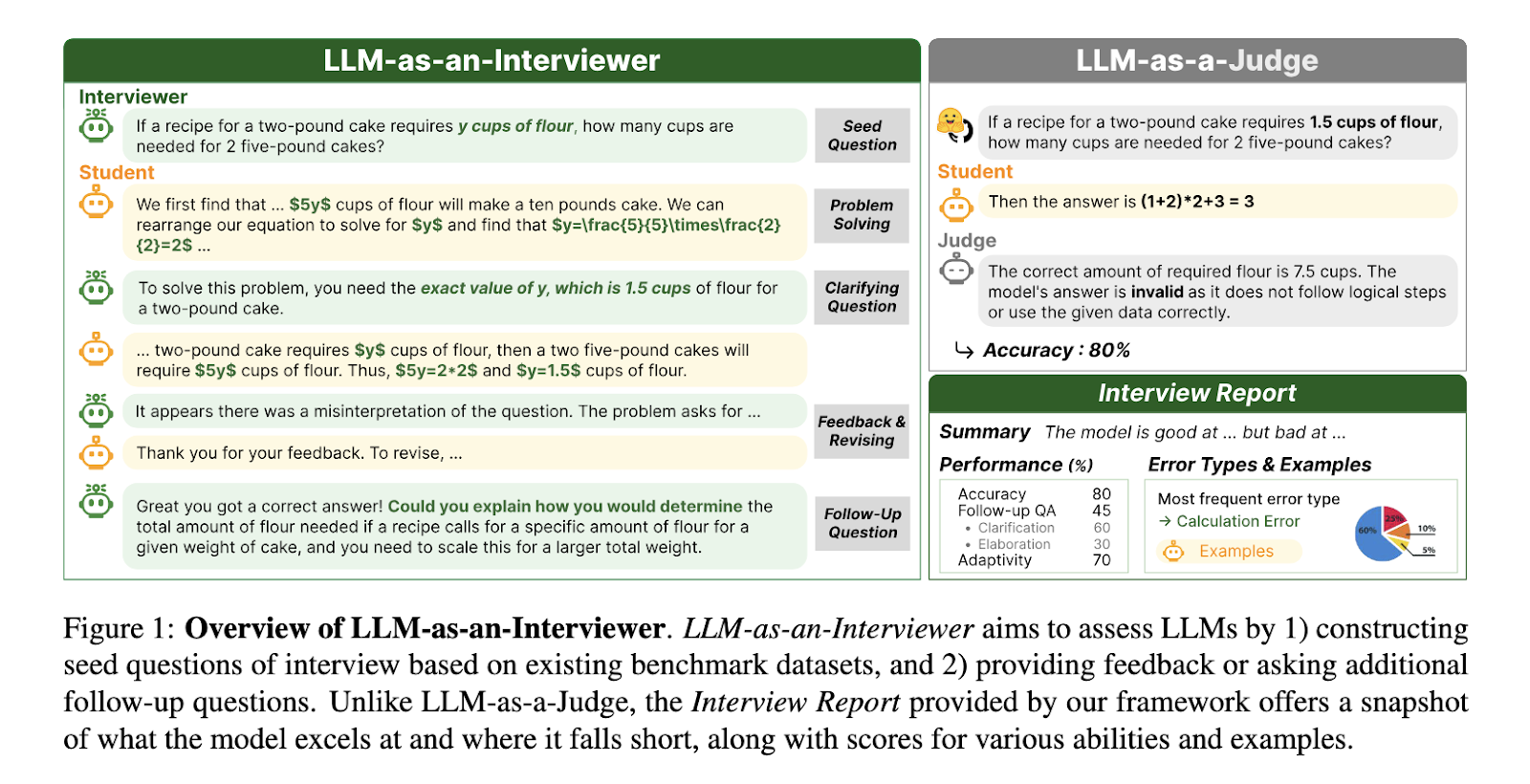
Researchers from KAIST, Stanford University, Carnegie Mellon University, and Contextual AI have introduced LLM-AS-AN-INTERVIEWER, a novel framework for evaluating LLMs. This approach mimics human interview processes by dynamically modifying datasets to generate tailored questions and providing feedback on model responses. The interviewer LLM adapts its questions based on the evaluated model’s performance, fostering a detailed and nuanced assessment of its capabilities. Unlike static methods, this framework captures behaviors such as response refinement and the ability to address additional inquiries effectively.
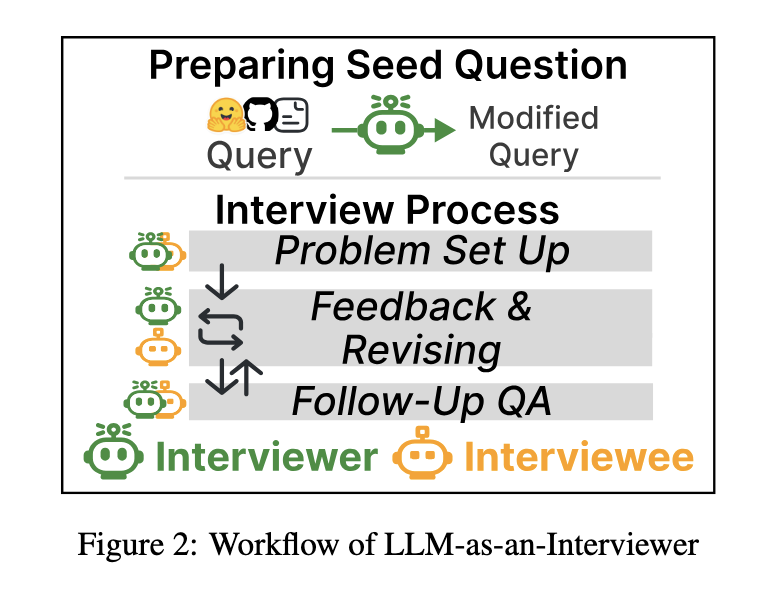
The framework operates in three stages: problem setup, feedback and revision, and follow-up questioning. Initially, the interviewer creates diverse and challenging questions by modifying benchmark datasets. During the interaction, it provides detailed feedback on the model’s responses and poses follow-up questions that test additional aspects of its reasoning or knowledge. This iterative process culminates in generating an “Interview Report,” which compiles performance metrics, error analysis, and a comprehensive summary of the model’s strengths and limitations. The report offers actionable insights into the model’s real-world applicability and adaptability.
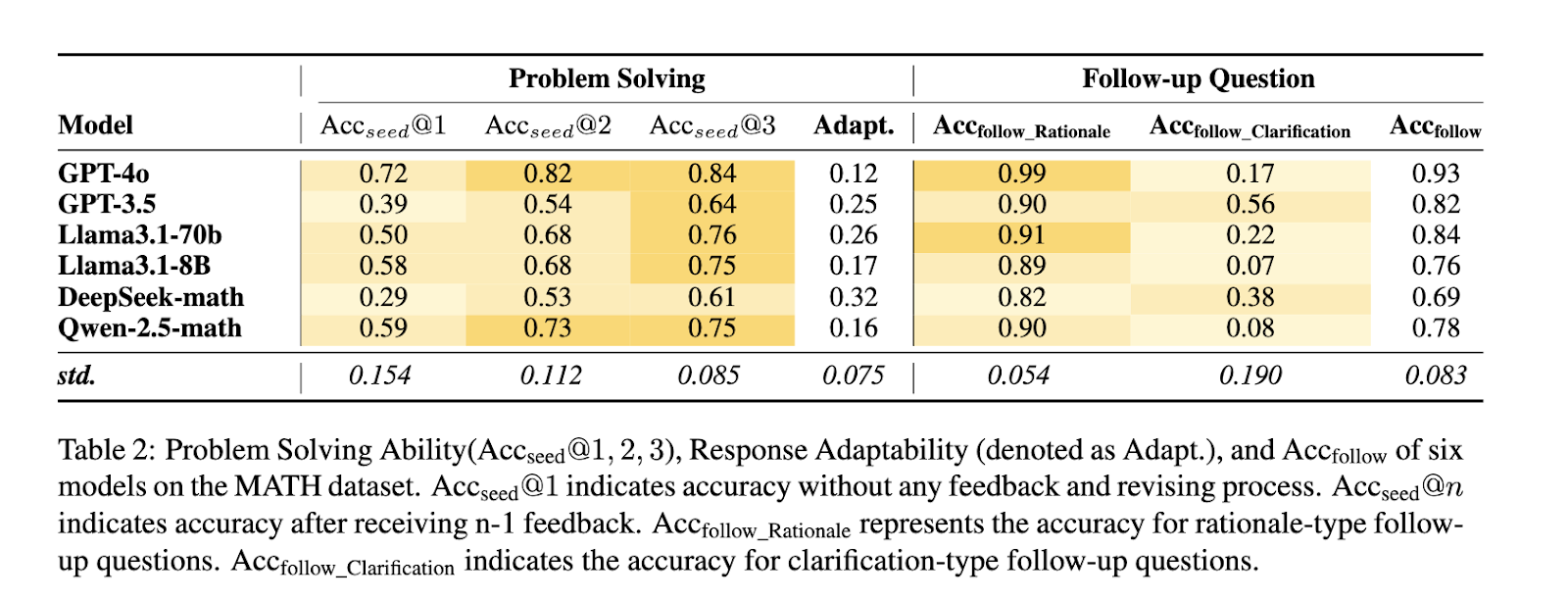
Experiments using the MATH and DepthQA datasets demonstrate the framework’s efficacy. For MATH, which focuses on arithmetic reasoning, models like GPT-4o achieved % initial problem-solving accuracy of 72%. This accuracy increased to 84% through iterative feedback and interaction, highlighting the framework’s ability to enhance model performance. Similarly, DepthQA evaluations, which emphasize open-ended queries, revealed the effectiveness of follow-up questions in uncovering models’ knowledge gaps and improving their responses. For instance, the adaptability metric for GPT-3.5 showcased a marked improvement of 25% after iterative interactions, reflecting the model’s ability to refine answers based on feedback.
The framework also addresses critical biases prevalent in LLM evaluations. Verbosity bias, a tendency to favor longer responses, diminishes as interactions progress, with a significant drop in correlation between response length and scores. Further, self-enhancement bias, where models favor their responses during evaluation, is minimized through dynamic interactions and comparative scoring. These adjustments ensure consistent and reliable evaluation outcomes across multiple runs, with standard deviations decreasing as feedback iterations increase.
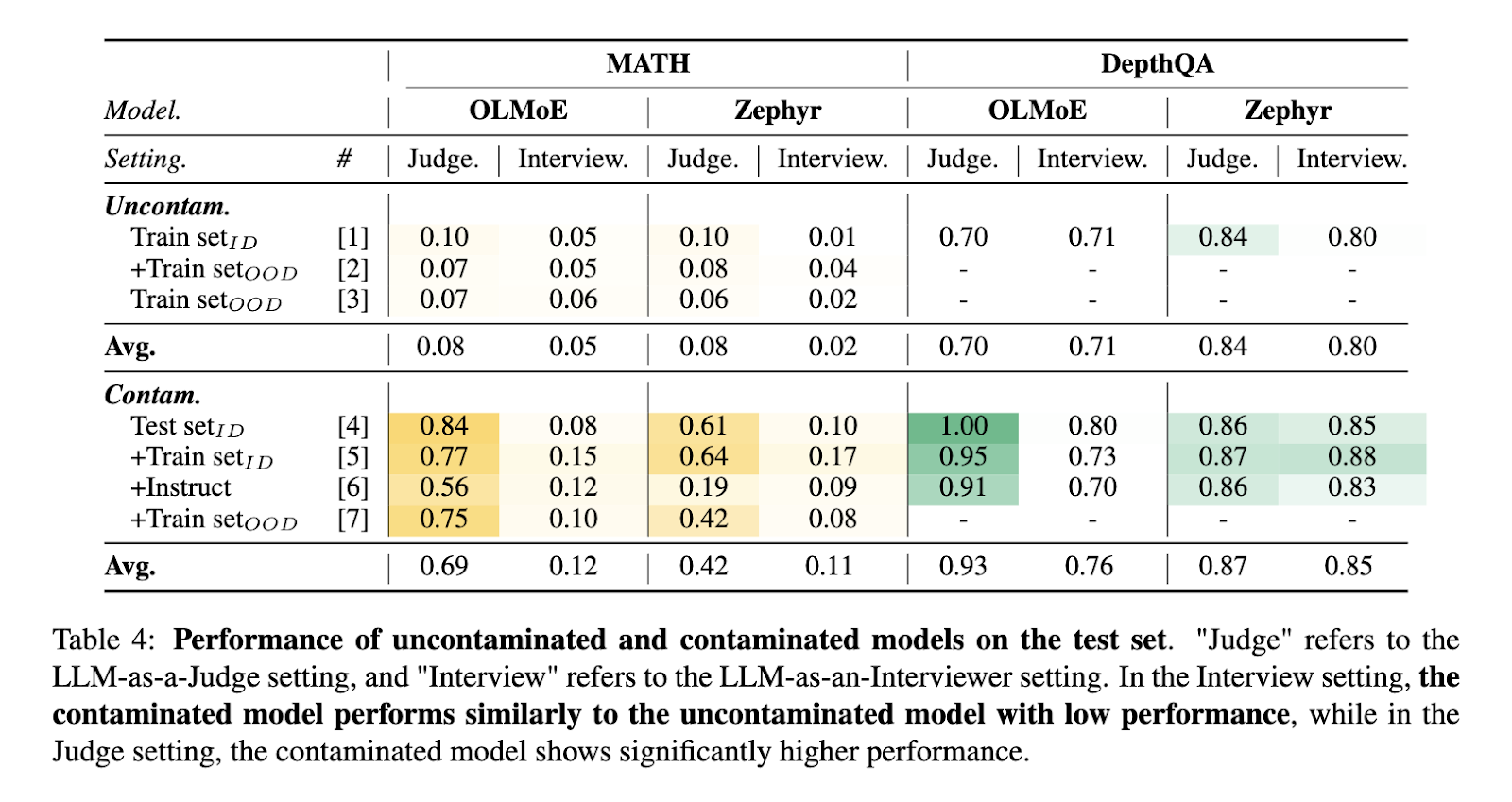
LLM-AS-AN-INTERVIEWER offers a robust solution to data contamination, a major LLM training and evaluation concern. The framework mitigates contamination risks by dynamically modifying benchmark questions and introducing novel follow-ups. For example, models trained on contaminated datasets showed significantly higher performance in static settings but aligned more closely with uncontaminated models when evaluated dynamically. This result underscores the framework’s ability to distinguish between genuine model capabilities and artifacts of training data overlap.
In conclusion, LLM-AS-AN-INTERVIEWER represents a paradigm shift in evaluating large language models. Simulating human-like interactions and dynamically adapting to model responses provide a more accurate and nuanced understanding of their capabilities. The framework’s iterative nature highlights areas for improvement and enables models to demonstrate their adaptability and real-world applicability. With its robust design and comprehensive analysis, this framework has the potential to set a new standard for LLM evaluation, ensuring that future models are assessed with greater precision and relevance.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
The post This AI Paper Introduces LLM-as-an-Interviewer: A Dynamic AI Framework for Comprehensive and Adaptive LLM Evaluation appeared first on MarkTechPost.
Source: Read MoreÂ
