


A direct correlation exists between an LLM’s training corpus quality and its capabilities. Consequently, researchers have invested a great deal of effort into curating extensive, high-quality datasets, which, at present, are achievable with craftful human annotations. Man-made datasets, however, have one downside: their reliance becomes increasingly unsustainable as complexity grows.
Many methods have been worked upon to address this, and one such notion is the idea of self-improvement, providing more scalable and cost-effective solutions. It is a continual process where the loop runs until the generated responses are refined. Self-improvement thereby does away with the need for extensive human data. While Self-improvement is undoubtedly a promising phenomenon, and its implementation testifies to its rapid development, our shallow understanding of it can’t be overlooked either. Many self-improvement strategies launched fail in scalability and saturate after three to five iterations. We still lack a deep understanding of the key factors and bottlenecks that drive successful self-improvement. Not only this, but we don’t even know why the internal optimization mechanisms remain primarily opaque.
In their recent paper, researchers from The Hong Kong University of Science and Technology have identified and proposed methods to monitor the pivotal factors of iterative self-improvement. The authors recognized two dynamic yet crucial factors affecting the improvement process: exploration and exploitation. Exploration refers to the model’s ability to generate correct and diverse responses. On the other hand, exploitation determined the effectiveness of external rewards in selecting high-quality solutions. The authors presented empirical evidence to confirm that these capabilities may lead growth to stagnate or decline. Further conflicts between the two undermine the model’s performance.
In response to the above issues, the research team proposed Balanced Self-Taught Reasoner, B-STAR: a novel approach for self-improvement to monitor and balance these dynamic factors and optimize the current policy and reward use. They presented a new metric balance score to adjust the configurations of sampling temperature and reward thresholds in the training process. Balance Score assesses the potential of a query based on the model’s exploration and exploitation capabilities. B-STAR then maximizes the average balance score by dynamically adjusting configurations to balance the above forces.
Balance Score captures the interplay of two capabilities by measuring the overall contribution of the synthetic data in training. The metric is designed to have a high number and proportion of high-quality responses. Authors then manipulate this score through hyperparameter configurations.
B-STAR was tested against mathematical problems, coding challenges, and common sense reasoning tasks.Results from these experiments showed that B-STAR effectively steered the model towards correct responses and thereby consistently achieved higher scores. B-STAR also yielded higher quality responses, confirming its enhanced exploration capacity. The proposed method maintained a substantial growth rate , unlike other baselines, which slowed down and stagnated. As per the experiments conducted in the paper, lower temperatures were preferred initially and then were subsequently increased to account for the model’s shifting limitations during training.The opposite is followed in reward threshold selection, where high rewards are set up initially to ensure rigorous filtering on a weak model.
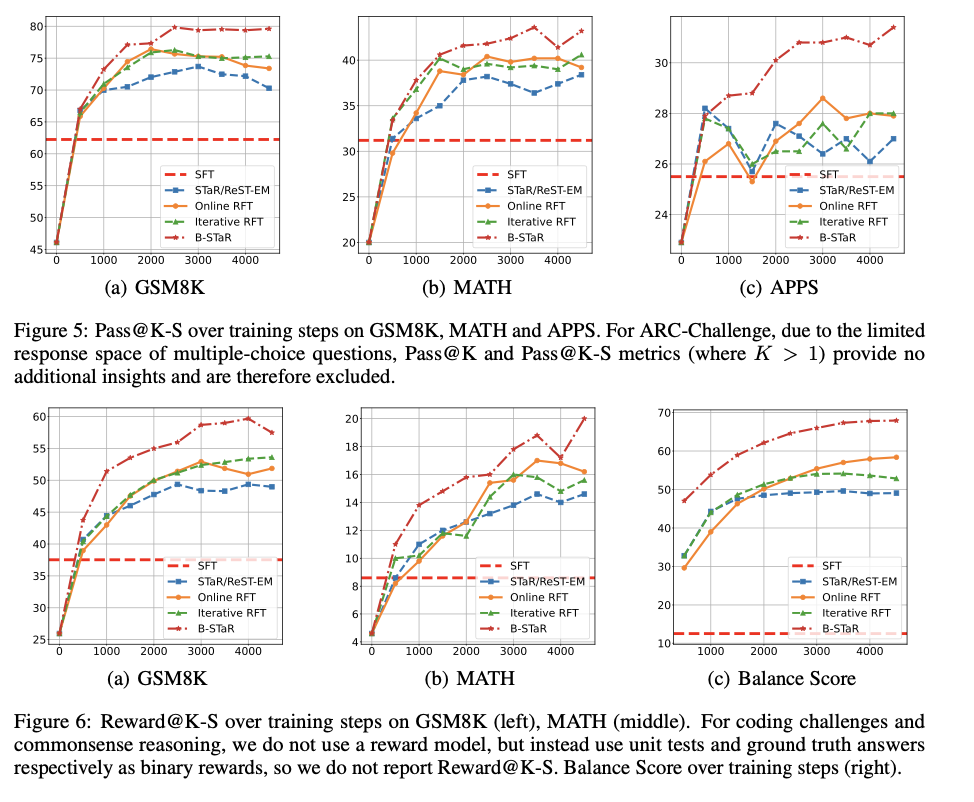
Conclusion-: B-STAR captured the interplay of exploration and exploitation capabilities and presented a simple method of hyperparameter configuration with a novel metric to balance factors above and improve performance in the self-improvement process. This paper lays the foundation for advanced research in decoding exploration and exploitation to maximize the quality of generated responses.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post B-STAR: A Self-Taught AI Reasoning Framework for LLMs appeared first on MarkTechPost.
Source: Read MoreÂ

