


Large language models (LLMs) built using transformer architectures heavily depend on pre-training with large-scale data to predict sequential tokens. This complex and resource-intensive process requires enormous computational infrastructure and well-constructed data pipelines. The growing demand for efficient and accessible LLMs has led researchers to explore techniques that balance resource use and performance, emphasizing achieving competitive results without relying on industry-scale resources.
Developing LLMs is filled with challenges, especially regarding computation and data efficiency. Pre-training models with billions of parameters demand advanced techniques and substantial infrastructure. High-quality data and robust training methods are crucial, as models face gradient instability and performance degradation during training. Open-source LLMs often struggle to match proprietary counterparts because of limited access to computational power and high-caliber datasets. Therefore, the challenge lies in creating efficient and high-performing models, enabling smaller research groups to participate actively in advancing AI technology. Solving this problem necessitates innovation in data handling, training stabilization, and architectural design.
Existing research in LLM training emphasizes structured data pipelines, using techniques like data cleaning, dynamic scheduling, and curriculum learning to improve learning outcomes. However, stability remains a persistent issue. Large-scale training is susceptible to gradient explosions, loss spikes, and other technical difficulties, requiring careful optimization. Training long-context models introduce additional complexity as attention mechanisms’ computational demands grow quadratically with sequence length. Existing approaches like advanced optimizers, initialization strategies, and synthetic data generation help alleviate these issues but often fall short when scaled to full-sized models. The need for scalable, stable, and efficient methods in LLM training is more urgent than ever.
Researchers at the Gaoling School of Artificial Intelligence, Renmin University of China, developed YuLan-Mini. With 2.42 billion parameters, this language model improves computational efficiency and performance with data-efficient methods. By leveraging publicly available data and focusing on data-efficient training techniques, YuLan-Mini achieves remarkable performance comparable to larger industry models.
YuLan-Mini’s architecture incorporates several innovative elements to enhance training efficiency. Its decoder-only transformer design employs embedding tying to reduce parameter size and improve training stability. The model uses Rotary Positional Embedding (ROPE) to handle long contexts effectively, extending its context length to 28,672 tokens, an advancement over typical models. Other key features include SwiGLU activation functions for better data representation and a carefully designed annealing strategy that stabilizes training while maximizing learning efficiency. Synthetic data was critical, supplementing the 1.08 trillion tokens of training data sourced from open web pages, code repositories, and mathematical datasets. These features enable YuLan-Mini to deliver robust performance with a limited computing budget.
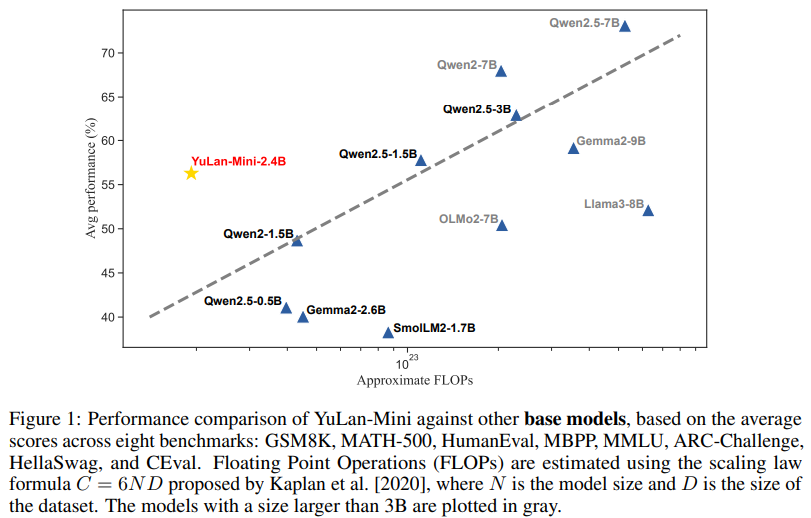
YuLan-Mini’s performance achieved scores of 64.00 on HumanEval in zero-shot scenarios, 37.80 on MATH-500 in four-shot settings, and 49.10 on MMLU in five-shot tasks. These results underscore its competitive edge, as the model’s performance is comparable to much larger and resource-intensive counterparts. The innovative context length extension to 28K tokens allowed YuLan-Mini to excel in long-text scenarios while still maintaining high accuracy in short-text tasks. This dual capability sets it apart from many existing models, which often sacrifice one for the other.

Key takeaways from the research include:
- Using a meticulously designed data pipeline, YuLan-Mini reduces reliance on massive datasets while ensuring high-quality learning.
- Techniques like systematic optimization and annealing prevent common issues like loss spikes and gradient explosions.
- Extending the context length to 28,672 tokens enhances the model’s applicability to complex, long-text tasks.
- Despite its modest computational requirements, YuLan-Mini achieves results comparable to those of much larger models, demonstrating the effectiveness of its design.
- The integration of synthetic data improves training outcomes and reduces the need for proprietary datasets.

In conclusion, YuLan-Mini is a great new addition to evolving efficient LLMs. Its ability to deliver high performance with limited resources addresses critical barriers to AI accessibility. The research team’s focus on innovative techniques, from data efficiency to training stability, highlights the potential for smaller-scale research to contribute to the field significantly. With just 1.08T tokens, YuLan-Mini sets a benchmark for resource-efficient LLMs.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post YuLan-Mini: A 2.42B Parameter Open Data-efficient Language Model with Long-Context Capabilities and Advanced Training Techniques appeared first on MarkTechPost.
Source: Read MoreÂ
