
We’re delighted to introduce a major enhancement to our Google Cloud Dataflow templates for MongoDB Atlas. By enabling direct support for JSON data types, users can now seamlessly integrate their MongoDB Atlas data into BigQuery, eliminating the need for complex data transformations.
This streamlined approach not only saves users time and resources, but it also empowers customers to unlock the full potential of their data through advanced data analytics and machine learning.
Limitations without JSON support
Traditionally, Dataflow pipelines designed to handle MongoDB Atlas data often necessitate the transformation of data into JSON strings or flattening complex structures to a single level of nesting before loading into BigQuery. Although this approach is viable, it can result in several drawbacks:
Increased latency: The multiple data conversions required can lead to increased latency and can significantly slow down the overall pipeline execution time.
Higher operational costs: The extra data transformations and storage requirements associated with this approach can lead to increased operational costs.
Reduced query performance: Flattening complex document structures in JSON String format can impact query performance and make it difficult to analyze nested data.
So, what’s new?
BigQuery’s Native JSON format addresses these challenges by enabling users to directly load nested JSON data from MongoDB Atlas into BigQuery without any intermediate conversions.
This approach offers numerous benefits:
Reduced operating costs: By eliminating the need for additional data transformations, users can significantly reduce operational expenses, including those associated with infrastructure, storage, and compute resources.
Enhanced query performance: BigQuery’s optimized storage and query engine is designed to efficiently process data in Native JSON format, resulting in significantly faster query execution times and improved overall query performance.
Improved data flexibility: users can easily query and analyze complex data structures, including nested and hierarchical data, without the need for time-consuming and error-prone flattening or normalization processes.
A significant advantage of this pipeline lies in its ability to directly leverage BigQuery’s powerful JSON functions on the MongoDB data loaded into BigQuery. This eliminates the need for a complex and time-consuming data transformation process. The JSON data within BigQuery can be queried and analyzed using standard BQML queries.

Whether you prefer a streamlined cloud-based approach or a hands-on, customizable solution, the Dataflow pipeline can be deployed either through the Google Cloud console or by running the code from the github repository.
Enabling data-driven decision-making
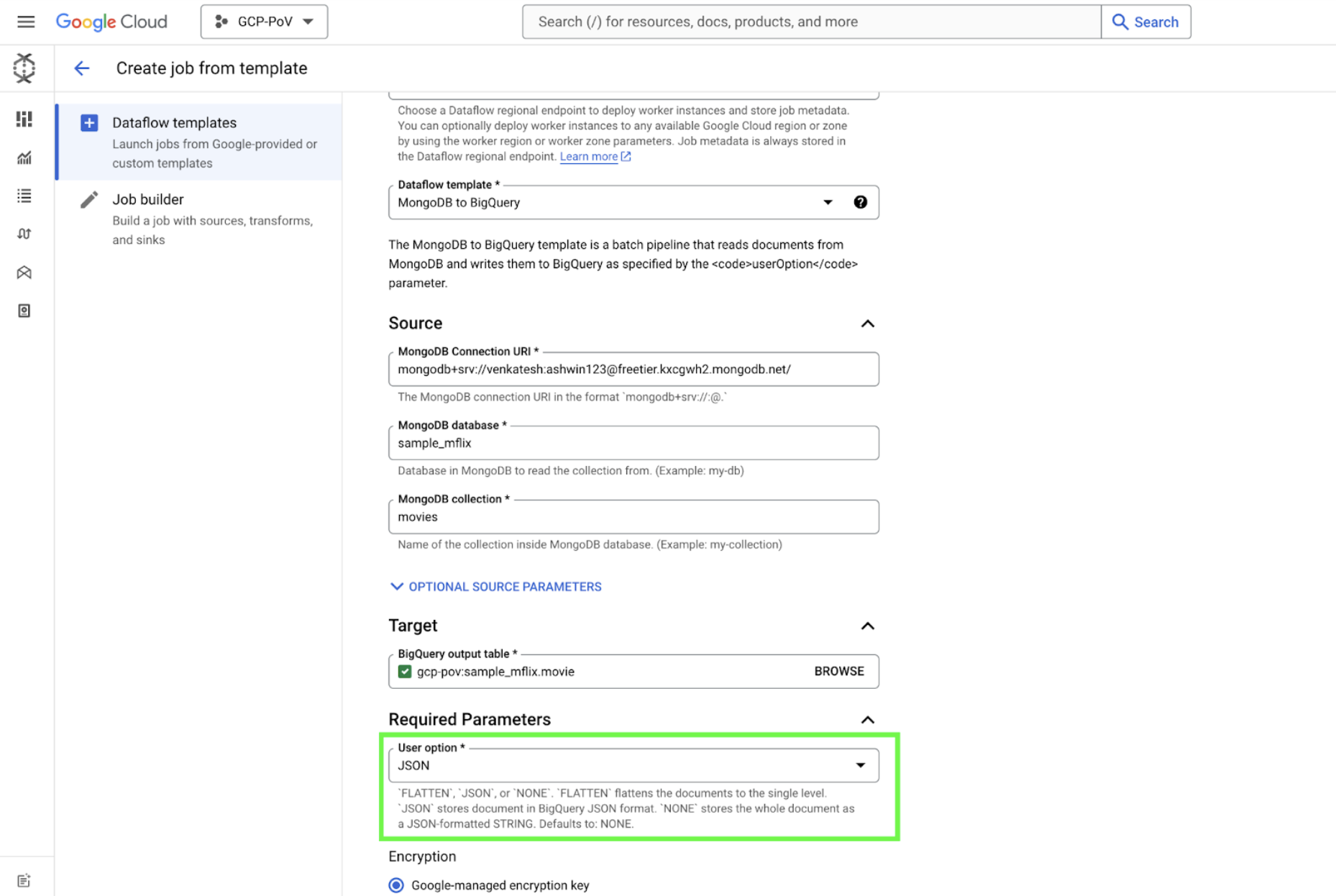
To summarize, Google’s Dataflow template provides a flexible solution for transferring data from MongoDB to BigQuery. It can process entire collections or capture incremental changes using MongoDB’s Change Stream functionality. The pipeline’s output format can be customized to suit your specific needs. Whether you prefer a raw JSON representation or a flattened schema with individual fields, you can easily configure it through the userOption parameter. Additionally, data transformation can be performed during template execution using User-Defined Functions (UDFs).
By adopting BigQuery Native JSON format in your Dataflow pipelines, you can significantly enhance the efficiency, performance, and cost-effectiveness of your data processing workflows. This powerful combination empowers you to extract valuable insights from your data and make data-driven decisions.
Follow the Google Documentation to learn how to set up the Dataflow templates for MongoDB Atlas and BigQuery.
Get started with MongoDB Atlas on Google Marketplace.
Learn more about MongoDB Atlas on Google Cloud on our product page.
Source: Read More
 future of next gen Xbox hardware")
