
MongoDB and LangChain, the company known for its eponymous large language model (LLM) application framework, are excited to announce new developments in an already strong partnership. Two additional enhancements have just been added to the LangChain codebase, making it easier than ever to build cutting-edge AI solutions with MongoDB.
Checkpointer support
In LangGraph, LangChain’s library for building stateful, multi-actor applications with LLMs, memory is provided through checkpointers. Checkpointers are snapshots of the graph state at a given point in time. They provide a persistence layer, allowing developers to interact and manage the graph’s state. This has a number of advantages for developers—human-in-the-loop, “memory” between interactions, and more.
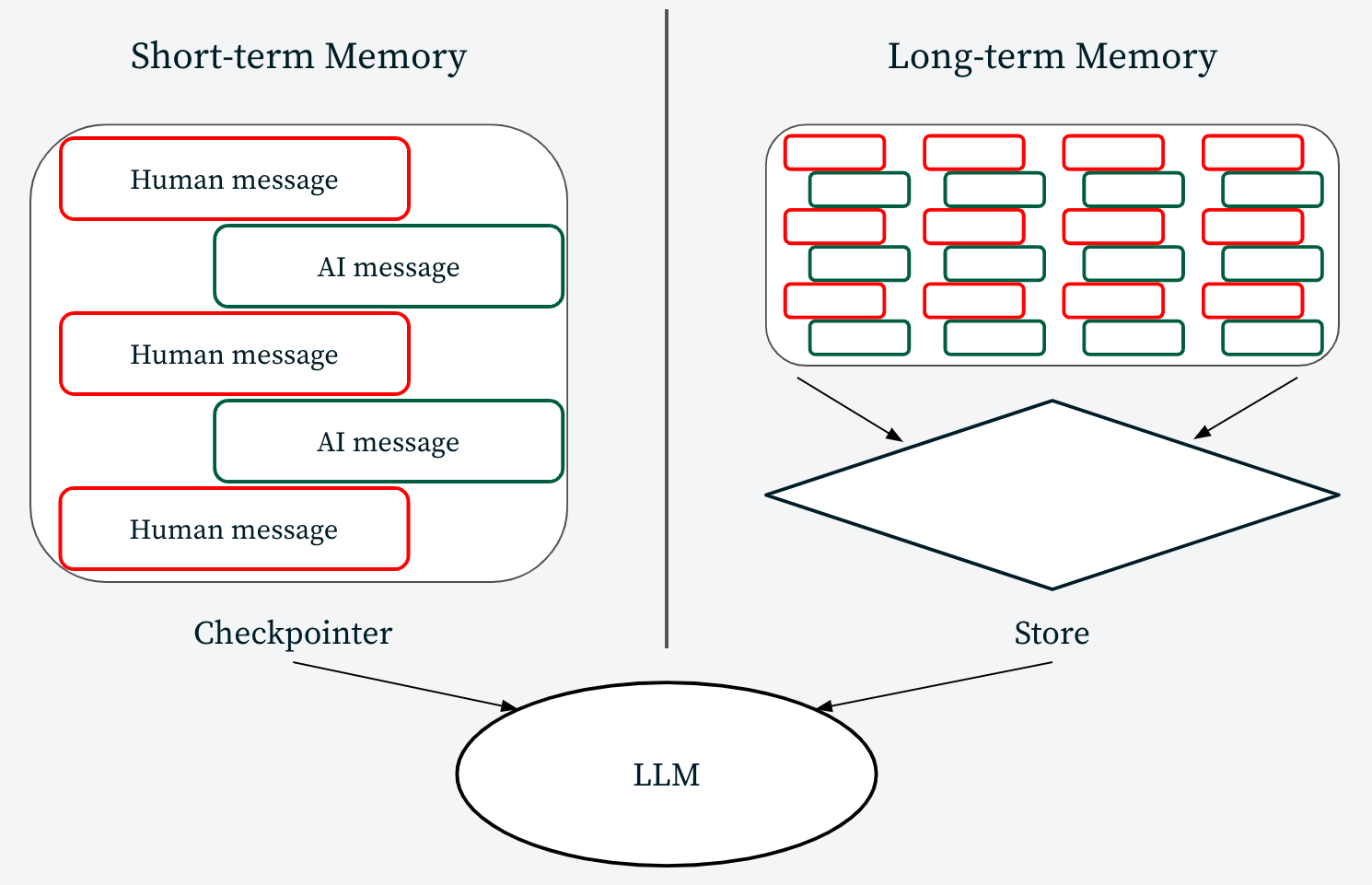
MongoDB has developed a custom checkpointer implementation, the “MongoDBSaver” class, that, with just a MongoDB URI (local or Atlas), can easily store LangGraph state in MongoDB. By making checkpointers a first-class feature, developers can have confidence that their stateful AI applications built on MongoDB will be performant.
That’s not all, since there are actually two new checkpointers as part of this implementation—one synchronous and one asynchronous. This versatility allows the new functionality to be even more versatile, and serving developers with a myriad of use cases.
Both implementations include helpful utility functions to make using them painless, letting developers easily store instances of StateGraph inside of MongoDB. A performant persistence layer that stores data in an intuitive way will mean a better end-user experience and a more robust system, no matter what a developer is building with LangGraph.
Native parent child retrievers
Second, MongoDB has implemented a native parent child retriever inside LangChain. This approach enhances the performance of retrieval methods utilizing the retrieval-augmented Generation (RAG) technique by providing the LLM with a broader context to consider.

In essence, we divide the original documents into relatively small chunks, embed each one, and store them in MongoDB. Using such small chunks (a sentence or a couple of sentences) helps the embedding models to better reflect their meaning.
Now developers can use “MongoDBAtlasParentDocumentRetriever” to persist one collection for both vector and document storage. In this implementation, we can store both parent and child documents in a single collection while only having to compute and index embedding vectors for the chunks. This has a number of performance advantages because storing vectors with their associated documents means no need to join tables or worry about painful schema migrations.
Additionally, as part of this work, MongoDB has also added a “MongoDBDocStore” class which provides many helpful utility functions. It is now easier than ever to use documents as a key-value store and insert, update, and delete them with ease. Taken together, these two new classes allow developers to take full advantage of MongoDB’s abilities.
MongoDB and LangChain continue to be a strong pair for building agentic AI—combining performance and ease of development to provide a developer-friendly experience. Stay tuned as we build out additional functionality!
To learn more about these LangChain integrations, here are some resources to get you started:
Check out our tutorial.
Experiment with checkpointers and native parent child retrievers to see their utility for yourself.
Read the previous announcement with LangChain about AI Agents, Hybrid Search, and Indexing.
Source: Read More
 future of next gen Xbox hardware")
