


Multimodal large language models (MLLMs) are advancing rapidly, enabling machines to interpret and reason about textual and visual data simultaneously. These models have transformative applications in image analysis, visual question answering, and multimodal reasoning. By bridging the gap between vision & language, they play a crucial role in improving artificial intelligence’s ability to understand and interact with the world holistically.
Despite their promise, these systems need to overcome significant challenges. A core limitation is the reliance on natural language supervision for training, often resulting in suboptimal visual representation quality. While increasing dataset size and computational complexity have led to modest improvements, they need more targeted optimization for visual understanding within these models to ensure they achieve the desired performance in vision-based tasks. Current methods frequently need to balance computational efficiency and improved performance.
Existing techniques for training MLLMs typically involve using visual encoders to extract features from images and feeding them into the language model alongside natural language data. Some methods employ multiple visual encoders or cross-attention mechanisms to enhance understanding. However, these approaches come at the cost of significantly higher data and computation requirements, limiting their scalability and practicality. This inefficiency underscores the need for a more effective way to optimize MLLMs for visual comprehension.
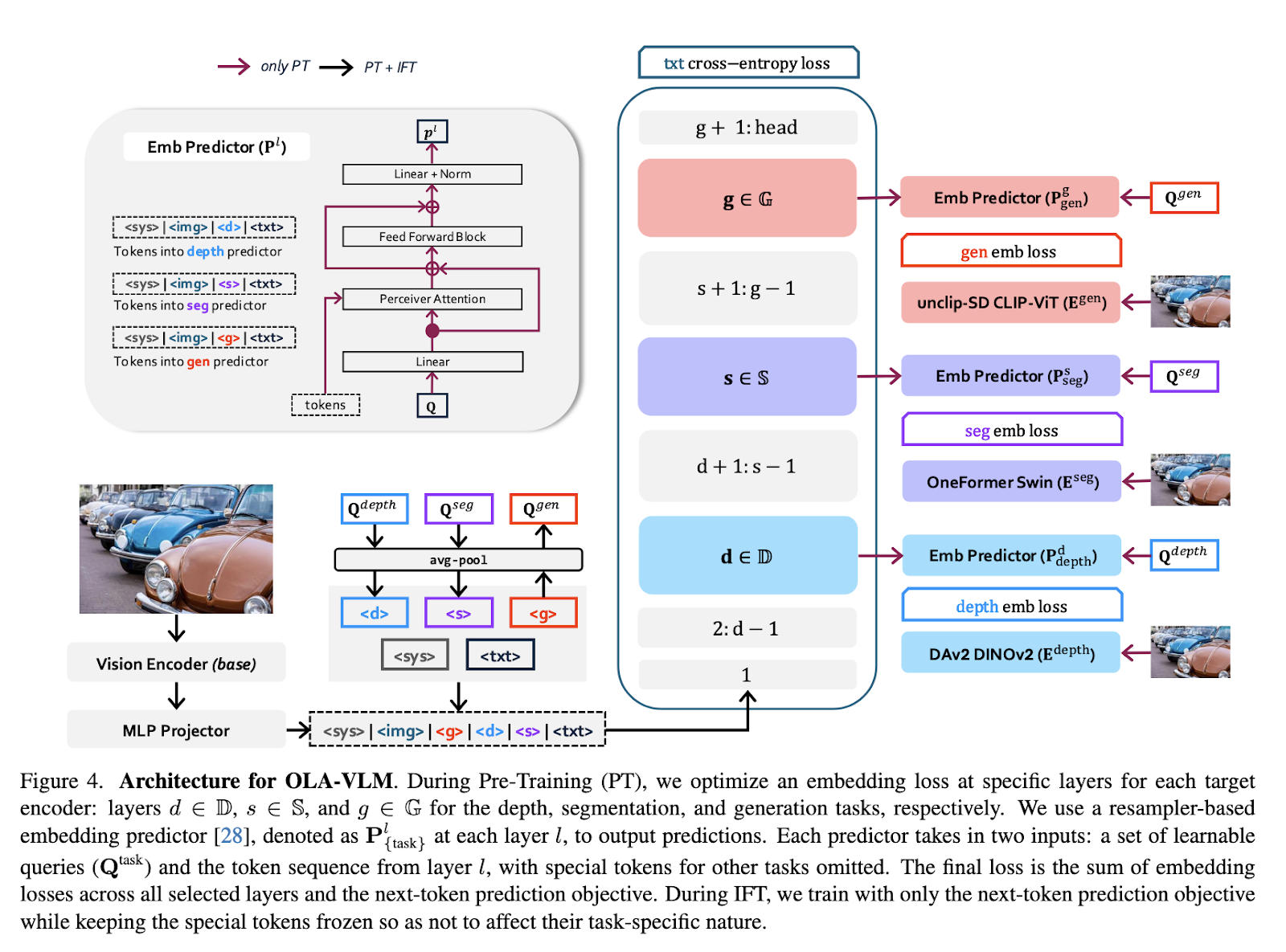
Researchers at SHI Labs at Georgia Tech and Microsoft Research introduced a novel approach called OLA-VLM to address these challenges. The method aims to improve MLLMs by distilling auxiliary visual information into their hidden layers during pretraining. Instead of increasing visual encoder complexity, OLA-VLM leverages embedding optimization to enhance the alignment of visual and textual data. Introducing this optimization into intermediate layers of the language model ensures better visual reasoning without additional computational overhead during inference.
The technology behind OLA-VLM involves embedding loss functions to optimize representations from specialized visual encoders. These encoders are trained for image segmentation, depth estimation, and image generation tasks. The distilled features are mapped to specific layers of the language model using predictive embedding optimization techniques. Further, special task-specific tokens are appended to the input sequence, allowing the model to incorporate auxiliary visual information seamlessly. This design ensures that the visual features are effectively integrated into the MLLM’s representations without disrupting the primary training objective of next-token prediction. The result is a model that learns more robust and vision-centric representations.
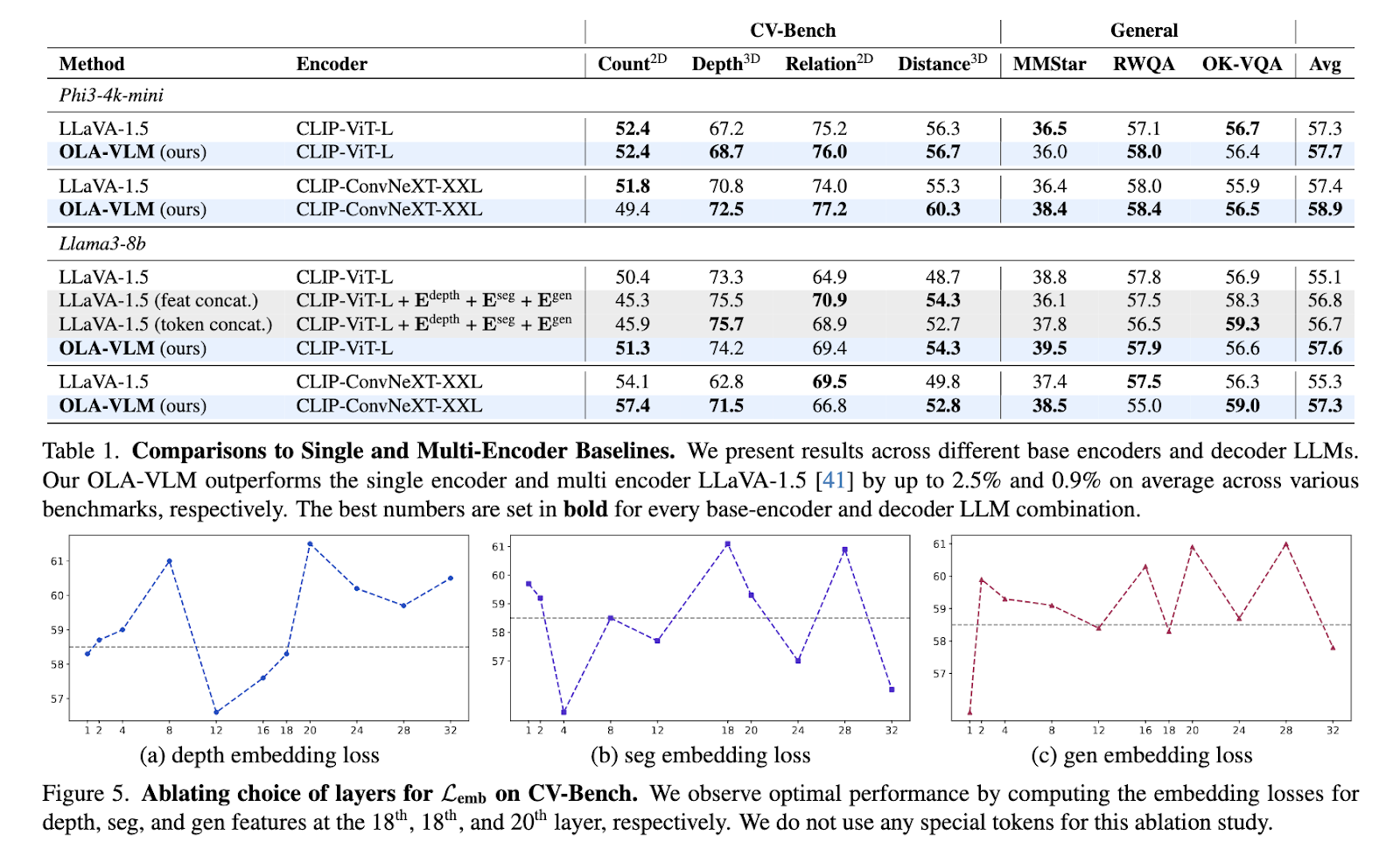
The performance of OLA-VLM was rigorously tested on various benchmarks, showing substantial improvements over existing single- and multi-encoder models. On CV-Bench, a vision-centric benchmark suite, OLA-VLM outperformed the LLaVA-1.5 baseline by up to 8.7% in in-depth estimation tasks, achieving an accuracy of 77.8%. For segmentation tasks, it achieved a mean Intersection over Union (mIoU) score of 45.4%, significantly improving over the baseline’s 39.3%. The model also demonstrated consistent gains across 2D and 3D vision tasks, achieving an average improvement of up to 2.5% on benchmarks like distance and relation reasoning. OLA-VLM achieved these results using only a single visual encoder during inference, making it far more efficient than multi-encoder systems.
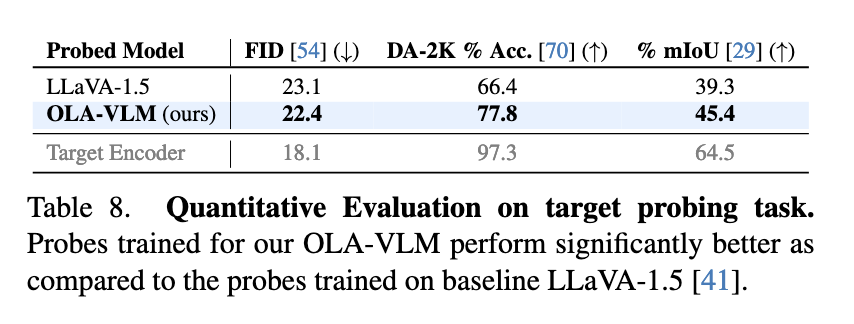
To further validate its effectiveness, researchers analyzed the representations learned by OLA-VLM. Probing experiments revealed that the model achieved superior visual feature alignment in its intermediate layers. This alignment significantly enhanced the model’s downstream performance across various tasks. For instance, the researchers noted that integrating special task-specific tokens during training contributed to better optimizing features for depth, segmentation, and image generation tasks. The results underscored the efficiency of the predictive embedding optimization approach, proving its capability to balance high-quality visual understanding with computational efficiency.
OLA-VLM establishes a new standard for integrating visual information into MLLMs by focusing on embedding optimization during pretraining. This research addresses the gap in current training methods by introducing a vision-centric perspective to improve the quality of visual representations. The proposed approach enhances performance on vision-language tasks and achieves this with fewer computational resources compared to existing methods. OLA-VLM exemplifies how targeted optimization during pretraining can substantially improve multimodal model performance.
In conclusion, the research conducted by SHI Labs and Microsoft Research highlights a groundbreaking advancement in multimodal AI. By optimizing visual representations within MLLMs, OLA-VLM bridges a critical gap in performance and efficiency. This method demonstrates how embedding optimization can effectively address challenges in vision-language alignment, paving the way for more robust and scalable multimodal systems in the future.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post Microsoft AI Research Introduces OLA-VLM: A Vision-Centric Approach to Optimizing Multimodal Large Language Models appeared first on MarkTechPost.
Source: Read MoreÂ

