 Architecture Redefining Vision-Language AI")


Integrating vision and language capabilities in AI has led to breakthroughs in Vision-Language Models (VLMs). These models aim to process and interpret visual and textual data simultaneously, enabling applications such as image captioning, visual question answering, optical character recognition, and multimodal content analysis. VLMs play an important role in developing autonomous systems, enhanced human-computer interactions, and efficient document processing tools by bridging the gap between these two data modalities. Still, the complexity of handling high-resolution visual data alongside diverse textual inputs remains a main challenge in this domain.Â
Existing research has addressed some of these limitations using static vision encoders that lack adaptability to high-resolution and variable input sizes. Pretrained language models used with vision encoders often introduce inefficiencies, as they are not optimized for multimodal tasks. While some models incorporate sparse computation techniques to manage complexity, they frequently need to improve accuracy across diverse datasets. Also, the training datasets used in these models often need more diversity and task-specific granularity, further hindering performance. For instance, many models underperform in specialized tasks like chart interpretation or dense document analysis due to these constraints.
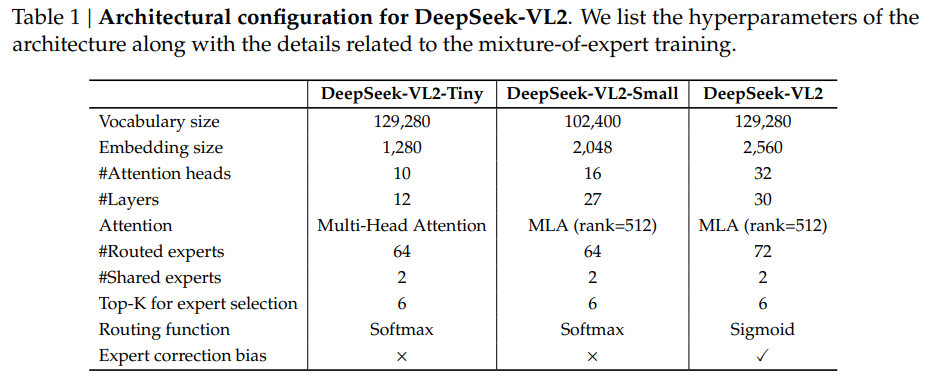
Researchers from DeepSeek-AI have introduced the DeepSeek-VL2 series, a new generation of open-source mixture-of-experts (MoE) vision-language models. These models leverage cutting-edge innovations, including dynamic tiling for vision encoding, a Multi-head Latent Attention mechanism for language tasks, and a DeepSeek-MoE framework. DeepSeek-VL2 offers three configurations with different activated parameters (activated parameters refer to the subset of a model’s parameters that are dynamically utilized during a specific task or computation):Â
- DeepSeek-VL2-Tiny with 3.37 billion parameters (1.0 billion activated parameters)
- DeepSeek-VL2-Small with 16.1 billion parameters (2.8 billion activated parameters)
- DeepSeek-VL2 with 27.5 billion parameters (4.5 billion activated parameters)Â
This scalability ensures adaptability for various application needs and computational budgets.
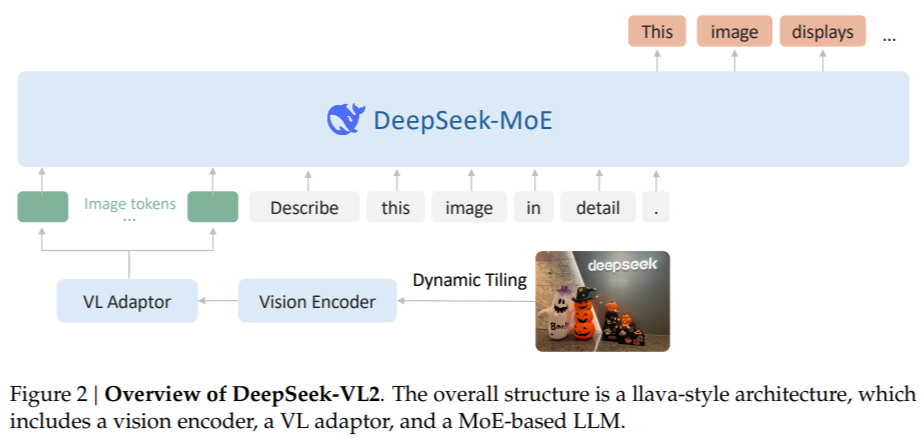
The architecture of DeepSeek-VL2 is designed to optimize performance while minimizing computational demands. The dynamic tiling approach ensures that high-resolution images are processed without losing critical detail, making it particularly effective for document analysis and visual grounding tasks. Also, the Multi-head Latent Attention mechanism allows the model to manage large volumes of textual data efficiently, reducing the computational overhead typically associated with processing dense language inputs. The DeepSeek-MoE framework, which activates only a subset of parameters during task execution, further enhances scalability and efficiency. DeepSeek-VL2’s training incorporates a diverse and comprehensive multimodal dataset, enabling the model to excel across various tasks, including optical character recognition (OCR), visual question answering, and chart interpretation.
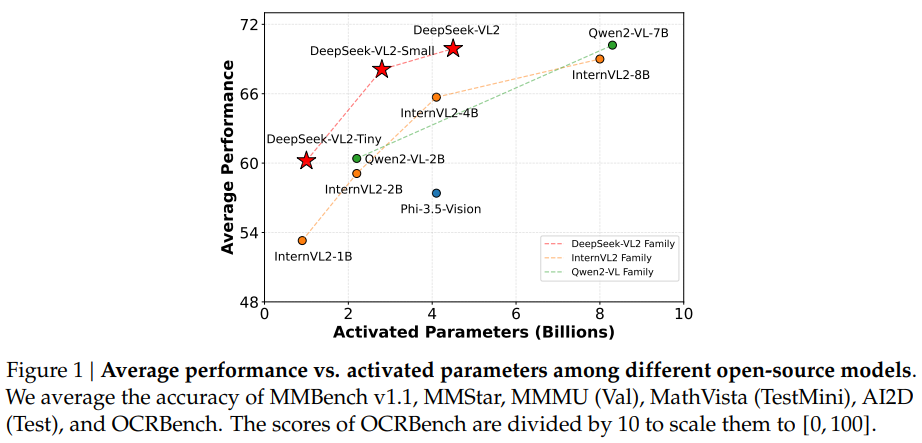
While checking for performances, the small configuration, for example, achieved an impressive 92.3% accuracy on OCR tasks, outperforming existing models by a significant margin. In visual grounding benchmarks, the model demonstrated a 15% improvement in precision compared to its predecessors. Also, DeepSeek-VL2 showed remarkable efficiency, requiring 30% fewer computational resources than comparable models while maintaining state-of-the-art accuracy. The results also highlighted the model’s ability to generalize across tasks, with its Standard variant achieving leading scores in multimodal reasoning benchmarks. These achievements underscore the effectiveness of the proposed models in addressing the challenges associated with high-resolution image and text processing.
Several takeaways from the DeepSeek-VL2 model series are as follows:
- By dividing high-resolution images into smaller tiles, the models improve feature extraction and reduce computational overhead. This approach is useful for dense document analysis and complex visual layouts. Â
- The availability of tiny (3B), small (16B), and standard (27B) configurations ensures adaptability to various applications, from lightweight deployments to resource-intensive tasks. Â
- Using a comprehensive dataset encompassing OCR and visual grounding tasks enhances the model’s generalizability and task-specific performance. Â
- The sparse computation framework activates only necessary parameters, enabling reductions in computational costs without compromising accuracy.

In conclusion, the DeepSeek-VL2 is an open-source vision language model series with three variants (1.8B, 2.8B, and 4.5B activated parameters). The research team has introduced a model series that excels in real-world applications by addressing critical limitations in scalability, computational efficiency, and task adaptability. Its innovative, dynamic tiling and Multi-head Latent Attention mechanisms enable precise image processing and efficient text handling, achieving state-of-the-art results across tasks like OCR and visual grounding. The model series sets a new standard in AI performance with scalable configurations and a comprehensive multimodal dataset.
Check out the Models on Hugging Face. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post DeepSeek-AI Open Sourced DeepSeek-VL2 Series: Three Models of 3B, 16B, and 27B Parameters with Mixture-of-Experts (MoE) Architecture Redefining Vision-Language AI appeared first on MarkTechPost.
Source: Read MoreÂ

