


Integrating vision and language processing in AI has become a cornerstone for developing systems capable of simultaneously understanding visual and textual data, i.e., multimodal data. This interdisciplinary field focuses on enabling machines to interpret images, extract relevant textual information, and discern spatial and contextual relationships. These capabilities promise to reshape real-world applications by bridging the visual and linguistic understanding gap from autonomous vehicles to advanced human-computer interaction systems.
Despite many accomplishments in the field, it has notable challenges. Many models prioritize high-level semantic understanding of images, capturing overall scene descriptions but often overlooking detailed pixel or region-level information. This omission undermines their performance in specialized tasks requiring intricate comprehension, such as textual extraction from images or understanding spatial object relationships. Also, integrating multiple vision encoders to address these issues often results in computational inefficiency, increasing training and deployment complexity.
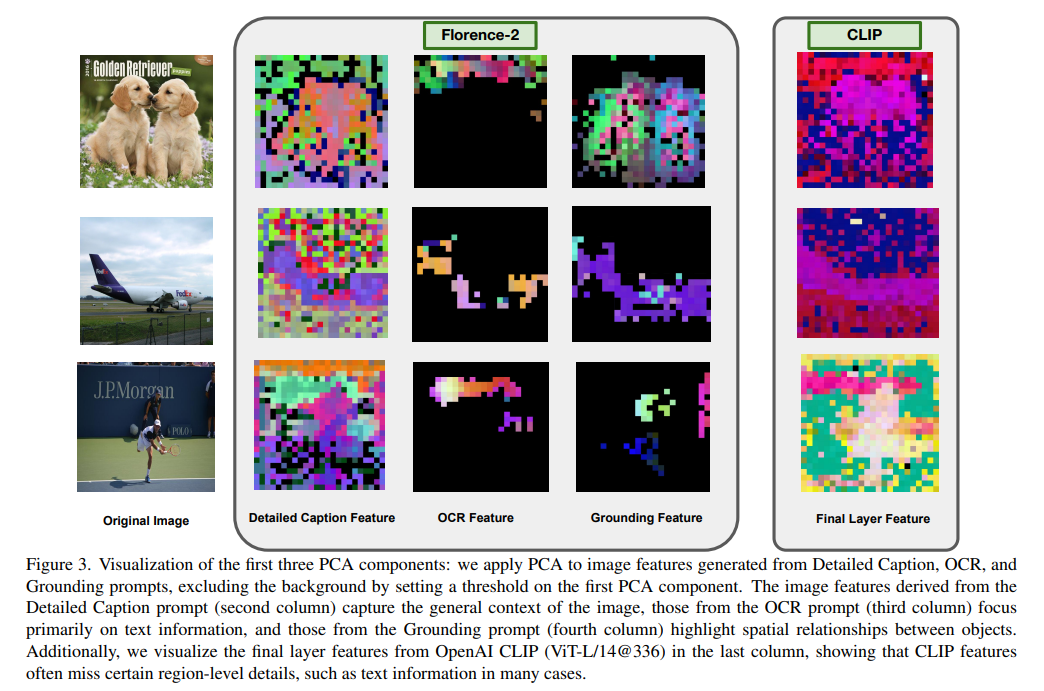
Tools like CLIP have historically set a benchmark for aligning visual and textual representations using contrastive pretraining. While effective for general tasks, CLIP’s reliance on single-layer semantic features limits its adaptability to diverse challenges. Advanced approaches have introduced self-supervised and segmentation models that address specific tasks, yet they frequently rely on multiple encoders, which can increase the computational demands. These limitations highlight the need for a versatile and efficient approach that balances generalization and task-specific precision.
Researchers from the University of Maryland and Microsoft introduced Florence-VL, a unique architecture to address these challenges and enhance vision-language integration. This model employs a generative vision foundation encoder, Florence-2, to provide task-specific visual representations. This encoder departs from traditional methods by utilizing a prompt-based approach, enabling it to tailor its features to various tasks such as image captioning, object detection, and optical character recognition (OCR).
Central to Florence-VL’s effectiveness is its Depth-Breadth Fusion (DBFusion) mechanism, which integrates visual features across multiple layers and prompts. This dual approach ensures the model captures granular and high-level details, catering to diverse vision-language tasks. Depth features are derived from hierarchical layers, offering detailed visual insights, while breadth features are extracted using task-specific prompts, ensuring adaptability to various challenges. Florence-VL combines these features efficiently by employing a channel-based fusion strategy, maintaining computational simplicity without sacrificing performance. Extensive training on 16.9 million image captions and 10 million instruction datasets further optimizes the model’s capabilities. Unlike traditional models that freeze certain components during training, Florence-VL fine-tunes its entire architecture during pretraining, achieving enhanced alignment between visual and textual modalities. Its instruction-tuning phase refines its ability to adapt to downstream tasks, supported by high-quality datasets curated for specific applications.

Florence-VL has been tested across 25 benchmarks, including visual question answering, OCR, and chart comprehension tasks. It achieved an alignment loss of 2.98, significantly surpassing models such as LLaVA-1.5 and Cambrain-8B. The Florence-VL 3B variant excelled in 12 out of 24 evaluated tasks, while the larger 8B version consistently outperformed competitors. Its results on OCRBench and InfoVQA benchmarks underline its ability to extract and interpret textual information from images with unparalleled precision.
Key takeaways from the research on Florence-VL are as follows:Â Â
- Unified Vision Encoding: A single vision encoder reduces complexity while maintaining task-specific adaptability. Â
- Task-Specific Flexibility: The prompt-based mechanism supports diverse applications, including OCR and grounding. Â
- Enhanced Fusion Strategy: DBFusion ensures a rich combination of depth and breadth features, capturing granular and contextual details. Â
- Superior Benchmark Results: Florence-VL leads performance in 25 benchmarks, achieving an alignment loss of 2.98. Â
- Training Efficiency: Fine-tuning the entire architecture during pretraining enhances multimodal alignment, yielding better task results. Â

In conclusion, Florence-VL addresses the critical limitations of existing vision-language models by introducing an innovative approach that effectively combines granular and high-level visual features. The multimodal model ensures task-specific adaptability by leveraging Florence-2 as its generative vision encoder and employing the Depth-Breadth Fusion (DBFusion) mechanism while maintaining computational efficiency. Florence-VL excels across diverse applications, such as OCR and visual question answering, achieving superior performance across 25 benchmarks.
Check out the Paper, Demo, and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
[Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
The post Microsoft Introduces Florence-VL: A Multimodal Model Redefining Vision-Language Alignment with Generative Vision Encoding and Depth-Breadth Fusion appeared first on MarkTechPost.
Source: Read MoreÂ

