




Medprompt, a run-time steering strategy, demonstrates the potential of guiding general-purpose LLMs to achieve state-of-the-art performance in specialized domains like medicine. By employing structured, multi-step prompting techniques such as chain-of-thought (CoT) reasoning, curated few-shot examples, and choice-shuffle ensembling, Medprompt bridges the gap between generalist and domain-specific models. This approach significantly enhances performance on medical benchmarks like MedQA, achieving nearly a 50% reduction in error rates without model fine-tuning. OpenAI’s o1-preview model further exemplifies advancements in LLM design by incorporating run-time reasoning to refine outputs dynamically, moving beyond traditional CoT strategies for tackling complex tasks.
Historically, domain-specific pretraining was essential for high performance in specialist areas, as seen in models like PubMedBERT and BioGPT. However, the rise of large generalist models like GPT-4 has shifted this paradigm, with such models surpassing domain-specific counterparts on tasks like the USMLE. Strategies like Medprompt enhance generalist model performance by integrating dynamic prompting methods, enabling models like GPT-4 to achieve superior results on medical benchmarks. Despite advancements in fine-tuned medical models like Med-PaLM and Med-Gemini, generalist approaches with refined inference-time strategies, exemplified by Medprompt and o1-preview, offer scalable and effective solutions for high-stakes domains.
Microsoft and OpenAI researchers evaluated the o1-preview model, representing a shift in AI design by incorporating CoT reasoning during training. This “reasoning-native†approach enables step-by-step problem-solving at inference, reducing reliance on prompt engineering techniques like Medprompt. Their study found that o1-preview outperformed GPT-4, even with Medprompt, across medical benchmarks, and few-shot prompting hindered its performance, suggesting in-context learning is less effective for such models. Although resource-intensive strategies like ensembling remain viable, o1-preview achieves state-of-the-art results at a higher cost. These findings highlight a need for new benchmarks to challenge reasoning-native models and refine inference-time optimization.
Medprompt is a framework designed to optimize general-purpose models like GPT-4 for specialized domains such as medicine by combining dynamic few-shot prompting, CoT reasoning, and ensembling. It dynamically selects relevant examples, employs CoT for step-by-step reasoning, and enhances accuracy through majority-vote ensembling of multiple model runs. Metareasoning strategies guide computational resource allocation during inference, while external resource integration, like Retrieval-Augmented Generation (RAG), ensures real-time access to relevant information. Advanced prompting techniques and iterative reasoning frameworks, such as Self-Taught Reasoner (STaR), further refine model outputs, emphasizing inference-time scaling over pre-training. Multi-agent orchestration offers collaborative solutions for complex tasks.
The study evaluates the o1-preview model on medical benchmarks, comparing its performance with GPT-4 models, including Medprompt-enhanced strategies. Accuracy, the primary metric, is assessed on datasets like MedQA, MedMCQA, MMLU, NCLEX, and JMLE-2024, as well as USMLE preparatory materials. Results show that o1-preview often surpasses GPT-4, excelling in reasoning-intensive tasks and multilingual cases like JMLE-2024. Prompting strategies, particularly ensembling, enhance performance, though few-shot prompting can hinder it. o1-preview achieves high accuracy but incurs greater costs compared to GPT-4o, which offers a better cost-performance balance. The study highlights tradeoffs between accuracy, price, and prompting approaches in optimizing large medical language models.
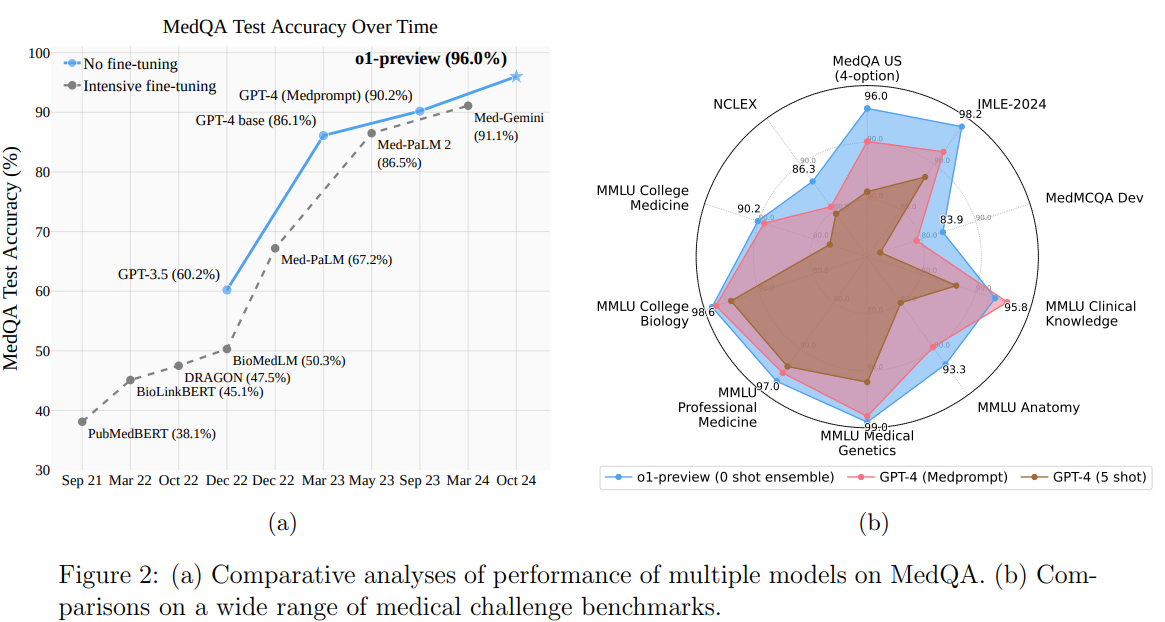
In conclusion, OpenAI’s o1-preview model significantly advances LLM performance, achieving superior accuracy on medical benchmarks without requiring complex prompting strategies. Unlike GPT-4 with Medprompt, o1-preview minimizes reliance on techniques like few-shot prompting, which sometimes negatively impacts performance. Although ensembling remains effective, it demands careful cost-performance trade-offs. The model establishes a new Pareto frontier, offering higher-quality results, while GPT-4o provides a more cost-efficient alternative for certain tasks. With o1-preview nearing saturation on existing benchmarks, there is a pressing need for more challenging evaluations to further explore its capabilities, especially in real-world applications.
Check out the Details and Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
[Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
The post Advancing Medical AI: Evaluating OpenAI’s o1-Preview Model and Optimizing Inference Strategies appeared first on MarkTechPost.
Source: Read MoreÂ